
冬の自由研究~プロ野球代打データ分析

こんにちは!とある女子大学院生です。
夏の自由研究をするつもりが…、すっかり冬になりました…。
完全に野球オタクのお戯れ研究ですので、どうぞ生暖かい目でご覧いただければ。笑
分析についての指摘とか色んな見解コメントはじゃんじゃんお待ちしています!よろしくお願いします!
研究テーマ
研究のテーマは、『プロ野球において代打を出すと得点確率があがるか?』です。
今回のヘッダー画像は私の推し選手・慶三さん。(撮影:私)
左投手相手の代打で輝く姿が大好き。他にハッセも好きなんですが、京セラ現地で代打グラスラを見れちゃいました。めっちゃ感動した!
代打選手の仕事人感、渋くてかっこよすぎませんか…ここぞで打つ勝負強さ…好きだ…。
でも代打って、絶対打ってくれって気持ちで観るけど実際はヒット出る確率って30%くらいじゃないですか。現実の打率に比べて期待度がだいぶ高い。凡退したらなかなかがっかりするし。
そういうわけで、代打ってほんとに有効な策なのかな~という気持ちから分析スタートです。
手法はマッチング法を考えています。この詳細はおいおい書くことにして、今回はデータの作成から記述統計的な部分を。代打をよく出している球団とかを調べました!!
最後にRのコードも載せているので何かの参考になればいいな。
データ
2020年シーズンのプロ野球のデータを使います。全試合のデータをとるのは大変なので、日付でランダムサンプリングをして、選ばれた30日の日付に行われた試合の7回以降を対象にしました。(うち2日は試合が1つもなかったので実質28日)とってきたデータの内容は、チーム・対戦相手・イニング・そのイニングに代打を出したかどうか・イニングに入った点数・表の攻撃か裏の攻撃か・負けている局面か・同点局面か・上位打線(1~5番)から始まるイニングか、です。スポナビのプロ野球速報アプリからひたすら手打ちで集めました。
修論のときも思いましたが、データ集めてるときが一番つまんなくてつらいんですよね…。
で、結果的に149試合分集まりました。サンプル数的には…30日切って少ないかと思ったけど試合数150近いので十分な気はします。
一応お作法的にゆるめの記述統計を置いておくと、
サンプル数846イニングのうち、代打が出されたのが312イニング(37%)・裏の攻撃391イニング(46%)・イニング開始時点で負けていたのが424イニング(50%)・同点だったのが109イニング(13%)・上位打線からが486イニング(57%)でした。イニングあたりの平均得点は0.43点。なかなか点は取れないものですね。
代打をよく出す球団はどこ?
代打をよく使う球団、いわゆる「積極的に動く球団」はどこかということですね。
結果がこちら。各球団が代打を出したイニングの割合です。

皆さんの予想と合ったでしょうか??
1番高かったのはカープ、12球団唯一の5割超えです。
パ・リーグのトップは日本ハム。栗山監督はよく動くイメージあるなぁ。
全体の平均は37%、リーグごとだとパ平均が29.8%、セ平均が44.1%でした。セの方が高いのは、DH制がなくて投手に打順がまわってくるので当然ですね。
リーグごとの平均を超えたのは、パがロッテ・日本ハム・オリックス、セが巨人・DeNA・広島・ヤクルトでした。逆に、断トツで低いのが西武です。確かにスタメンが完全体な印象ある。
興味深いのは、リーグ下位チームが代打率高めなことですね。スタメンが強力じゃないから代打が出されがちなんでしょうか。…とはいえ巨人とロッテも高めなのでこの時点ではなんとも言えぬですが。
こう見て思うのは、代打ってスタメンに自信がないから出されることもあれば、選手層が厚くて強打者が残ってるから出されることもあるんだなぁと。おもろいです…!(おもろいと思ってるのが私だけじゃないといいのですが笑)
終盤に強い球団はどこ?
これは代打と関係ない完全なるおまけ。終盤に強い球団はどこでしょう、です!!
試合の7回以降のデータを集めたので、試合終盤に各球団が、点をどれだけ取り、どれだけ取られているかを調べました。
結果がこちら。各球団の1イニングに取った点数・取られた点数の平均と、その差です。
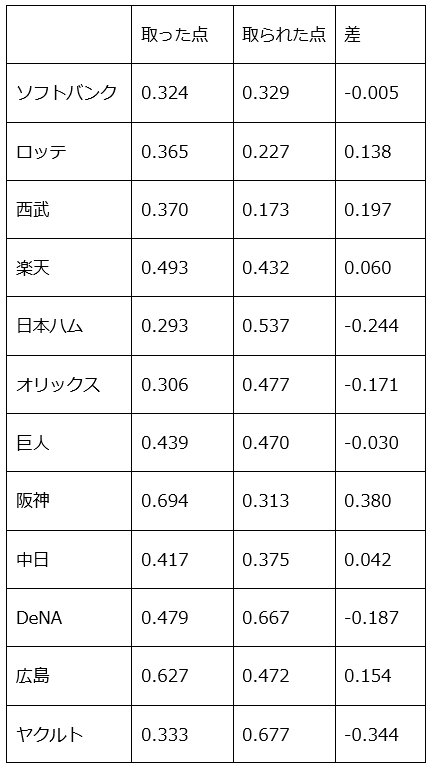
さぁ皆さんの贔屓球団は終盤に強かったでしょうか、弱かったでしょうか??
きついのはヤクルトですね…。取られる点が取れた点の倍あります。逆に阪神が良い感じ。取られる点の倍以上の点を取っています。
取られた点が最も少ないのは西武。俺達はいずこへ…新人王の平良が頑張ったかな?
両リーグ1位球団はともにわずかにマイナス。先行逃げ切り型ってことでしょうか。ソフトバンクは今季中継ぎめっちゃ良かったのでちょい感覚と外れてるかも。
いやぁこの表だけでめっちゃ語れちゃうなぁ…。
コード
使ったコードはこちら。RをJupyter Notebookに入れて使っています。
##諸々のパッケージ読み込み
suppressPackageStartupMessages(library(tidyverse))
suppressPackageStartupMessages(library(readxl))
##サンプルを選ぶ
#サンプルを選ぶための表を作る
#開幕6月19日 閉幕11月11日
#日を作る
day_june <- 19:30
day_september <- 1:30
day_november <- 1:11
day_others <- 1:31
day <- c(day_june,day_others,day_others,day_september,day_others,day_november)
#月を作る
june <- replicate(length(day_june),6)
july <- replicate(length(day_others),7)
augast <- replicate(length(day_others),8)
september <- replicate(length(day_september),9)
october <- replicate(length(day_others),10)
november <- replicate(length(day_november),11)
month <- c(june,july,augast,september,october,november)
#月日を結合
sample_origin <- cbind(month, day)
#サンプルとする日付を抽出
set.seed(99)
sample <- sample(1:length(day),30)
sample_origin[sample,]
#この日付をもとに、エクセルでデータを作成
##データの読み込み
data <- read_excel("(ファイルパス名です)/代打分析.xlsx", sheet=1, range="A1:I847", col_names=TRUE)
data$team <- as.factor(data$team)
data$opponent <- as.factor(data$opponent)
data$inning <- as.factor(data$inning)
data %>% str() #型の確認
##記述統計
data %>% summary()
attach(data)
sum(home);sum(behind);sum(even);sum(top);sum(pinchbatter)
##代打を多く出すチームは?
teams <- c("H","M","L","E","F","O","G","B","C","D","S","T")
pinchbatter_by_teams <- lapply(teams,function(t){
pinchbatter[team==t] %>% mean()
})
names(pinchbatter_by_teams) <- teams
#全体平均を超える球団は
exceed_mean <- sapply(teams,function(t){
pinchbatter_by_teams[[t]] > mean(pinchbatter)
})
#リーグごと
pacific <- c("H","M","L","E","F","O")
central <- c("G","B","C","D","S","T")
#リーグごとの平均
mean_pacific <- pinchbatter[team%in%pacific] %>% mean()
mean_central <- pinchbatter[team%in%central] %>% mean()
mean_league <- c(mean_pacific,mean_central)
names(mean_league) <- c("pacific","central")
#リーグごとの平均を超える球団は
exceed_pa <- sapply(pacific, function(t){
pinchbatter_by_teams[[t]] > mean_pacific
})
exceed_ce <- sapply(central, function(t){
pinchbatter_by_teams[[t]] > mean_central
})
exceed_league <- c(exceed_pa,exceed_ce)
#表にまとめる
pinchbatter_by_teams <- unlist(pinchbatter_by_teams)
pinchbatter_mean <- cbind(pinchbatter_by_teams,exceed_mean, exceed_league)
dimnames(pinchbatter_mean) <- list(teams, c("代打を出す確率","全体平均より代打確率が高い?","リーグ平均より代打確率が高い?"))
##(終盤に)点をよくとられているチームは?
point_by_opponent <- lapply(teams,function(t){
point[opponent==t] %>% mean()
})
names(point_by_opponent) <- teams
#(終盤に)点をよくとっているチームは?
point_by_team <- lapply(teams,function(t){
point[team==t] %>% mean()
})
names(point_by_team) <- teams
#表にする
point_by_opponent <- unlist(point_by_opponent) #リストをbrくとるに
point_by_team <- unlist(point_by_team)
points <- cbind(point_by_opponent,point_by_team)
differences <- sapply(teams,function(t){
points[t,2] - points[t,1]
})
points <- cbind(points,differences)
dimnames(points) <- list(teams, c("とられた点","とった点","差"))おわりに
念のため繰り返しますが、ここまでの部分はすべてサンプル内での話です。全データを入れると結果が異なる可能性もあります。
いやはやなかなかの文字数になりました…。楽しんでいただけていたらいいな!
それでは、また。
とある女子大学院生。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?