

#画像


【論文瞬読】1枚の画像から3Dシーンを生成!VistaDreamが切り開く新しい3D生成の世界
こんにちは!株式会社AI Nestです。今回は、最近発表された興味深い研究「VistaDream」についてご紹介したいと思います。単一の画像から3Dシーンを生成するという、とても魅力的な技術です。ARやVR、ロボティクスなど、様々な分野への応用が期待できる研究なので、しっかり解説していきましょう!
はじめに:なぜ単一画像からの3D生成が重要なの?皆さんは、1枚の写真から3Dモデルを作れたら便利だ




動画も高精度に!ComfyUIとSegment Anything Model 2(SAM 2)でセグメンテーションをマスターしよう
コンピュータビジョンの世界に革命をもたらした画像セグメンテーションモデル「Segment Anything Model(SAM)」。その登場から約1年、METAが新たな進化を遂げた「Segment Anything Model 2(SAM 2)」を発表しました。画像だけでなく動画にも対応したこの最新モデル、使い方によってはかなり実用的になり得るでしょう。
本記事では、SAM 2の特徴や機能、そして
【論文瞬読】SAM 2:画像と動画を自在に切り取る魔法のAI
こんにちは!株式会社AI Nestです。今日は、画像・動画処理の世界に革命を起こす可能性を秘めた最新のAIモデル「SAM 2」について、わかりやすく解説していきます。準備はいいですか?それでは、AIの魔法の世界へ飛び込んでいきましょう!
1. SAM 2とは? AIによる"万能はさみ"の誕生皆さんは、写真や動画から特定のものだけを切り取りたいと思ったことはありませんか?例えば、家族写真から背景だ


レガシーAIシリーズ(2) 簡単アニメキャラ抜き出しアプリ
画像中のアニメのキャラクタだけを抜き出したいことってありますよね。Illustratorなどの画像処理系アプリを使えばそれなりに出来ますし、WebUIなど、StableDiffusionで生成する時に背景削除も出来るようになっています。そのような中でキャラクタを取り出して画像の中央に配置し、ついでにアップスケールで自在に大きさを変えたり、キャンパスサイズを変更してキャラクタの一部、例えば顔やポート
もっとみる



セグメンテーションについて
セグメンテーション:画像を分割する機械学習のタスクセグメンテーションは、画像をいくつかのオブジェクトに分割する機械学習のタスクです。この分野には主に3つのタイプがあります。
1. セマンティックセグメンテーション
目的: 画像中の全ての画素にクラスラベルを予測する。
特徴: 各画素がどのオブジェクトに属するかを識別します。
2. インスタンスセグメンテーション
目的: 画像中の全ての物体


ZERO-SHOT-DETECTIONをDeticで実装!物体検出学習コストの大幅削減も可能に
初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
転職回数:1回(建設(2年9か月)→IT系年収100万up(現職3か月))
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はzero-shot-detectio
SAM(Segment Anything Model)を用いた画像分析の解説
初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
転職回数:1回(建設(2年9か月)→IT系年収100万up(現職3か月))
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はSAMに関して解説します!この一つ前




画像からテキストを検出するwebアプリを開発してみました
はじめに自己紹介
むぎなすびと申します。むぎは飼い猫の名前です。職業はメーカーの研究開発職(非IT業務)で、プログラミングの初心者です。DXスキルを身につけるために、アプリ開発にチャレンジしました。
背景
この記事は筆者が通うプログラミングスクール Aidemy Premium のカリキュラムの一環で卒業制作の記録として書いたもので、受講修了条件を満たすために公開しています。
タイ


「Depth Anything」: 画像と動画に新たな次元をもたらす革命的な深度推定ツール
私たちの生活には、革新的な技術が息吹を吹き込んでいます。特にAI(人工知能)の進化は、私たちが世界を理解し、それと対話する方法を根本から変えています。「Depth Anything」は、この技術の波に乗じて開発された、画像や動画から深度(奥行き)情報を抽出し、二次元データに三次元の豊かさを加えるオープンソースのAIツールです。
導入の詳細解説私たちの生活は、日々の技術革新によって大きく変化してい


【Computer Vision(4)】 Key technologies of Medical Image Diagnosis
前回の記事では、顔画像解析に焦点を当て、特に肌測定と顔認識に特化したアルゴリズム(Viola-Jones、Fisherfaces、ローカルバイナリパターン(LBP)、畳み込みニューラルネットワーク(CNN)など)について詳しく掘り下げました。その記事へのリンクはこちらです。
In our previous article, we delved into facial image analysis,

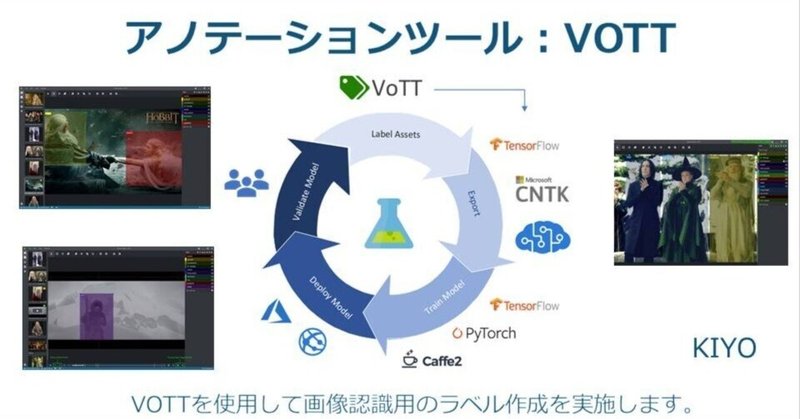
アノテーションツール:VOTT
1.概要 画像認識、物体検出は教師あり学習のため画像データと合わせてラベルデータ(正解データ)が必要であり、ラベルには座標情報が必要となります。
今回は下記のYOLOv5用にアノテーションを実施してラベルデータを作成しました。
1-1.アノテーションツールの紹介
アノテーションツールは複数あり用途、価格、使いやすさで選定します。VoTTは、画像セグメンテーションはできませんが、無料であり