ログイン
会員登録
データセット
書いてみる
関連タグ
#モデル (13,631)
#研究 (35,350)
#データ (31,941)
#使用 (3,662)
#タスク (6,930)
#機械学習 (149,192)
人気
急上昇
新着
定番
有料のみ
841件
人気の記事一覧
著作権に配慮した画像生成AI開発用データ約1000万個を無償公開
AI Picasso
1か月前
78
新しいRAGの仕組み!マイクロソフト、新技術GraphRAGをオープンソース化!
0xpanda alpha lab
2か月前
46
大規模言語モデルLLMの論理的思考を強くするデータセットを考える①
AIサトシ
11日前
9
3Dヒューマンヘッドのための大規模合成データセット「VGGHeads」を試してみる
SUTO💡
1か月前
12
ネットの文章とChatBotの文章は「どれくらい離れているか」を可視化する
Kan Hatakeyama
1か月前
16
LAION-5Bの開発元であるLAIONがデータセットからCSAMを削除した「Re-LAION-5B」を新たに発表しました
榊正宗 Official note@blender & ComfyUI
3週間前
9
ビジネスパーソン必見!Difyで簡単に生成AIアプリを作る方法
ゆず檸檬
3週間前
12
【論文瞬読】長文コンテキスト理解におけるRAGとLLMの比較とハイブリッドアプローチSELF-ROUTEの提案
AI Nest
1か月前
18
【論文瞬読】SAM 2:画像と動画を自在に切り取る魔法のAI
AI Nest
1か月前
14
LLMだけでデータセット生成してみよう!Magpie方式でのprompt生成
鐵火卷
3か月前
10
EDAツール魔法大戦に終止符を Ydata-Profiling, Sweetviz, Lux
Puuuii | 伝える技術と心理学で戦うデータエンジニア
3か月前
27
誰でも自由に使える日本語の指示データセットを作っています
Kan Hatakeyama
6か月前
44
Stable Diffusionを極める!追加学習で自分だけの画像生成を実現しよう
中山
1か月前
4
(後編) トランプチームは、CBDC (中央デジタル通貨)を導入するつもりなのかもしれません。確かに彼らはリアルIDを導入するつもりであり、これは "社会信用システム"の第一歩です。
よっちQAJF⭐️⭐️⭐️
3か月前
13
arXiv trend: August 13, 2024
Ikemen Mas Kot
1か月前
4
LLM評価データセット概観
sharp_engineer
5か月前
17
うみはひろいか,おおきいか.
Tomo Kunimitsu
3か月前
5
軽量・高速・高性能と三拍子揃った日本語対応のAI(Orion-14B)で指示データセットを自動生成するメモ
Kan Hatakeyama
7か月前
41
生成AIのビジネスはおそらく今後こうなる。パソコンをDOS時代から売ってた技術者やセールスマンとしての自分の予測。
かふぇらて
10日前
3
ローカルLLM : 最近作成したデータセットについての記録
AIサトシ
5か月前
16
大規模言語モデルの構築の事前学習に使えそうなデータセット(主に日本語系)の整理メモ
Kan Hatakeyama
7か月前
38
第2回: 大規模言語モデル(LLM)の基本
Kajimoto Muneyoshi
3か月前
8
【論文瞬読】WILDCHATが切り拓く会話AIの新時代:100万件のチャットログが示す可能性と課題
AI Nest
4か月前
10
【論文瞬読】大規模言語モデルのプロンプト圧縮に革新をもたらす新手法 LLMLingua-2
AI Nest
4か月前
12
【論文瞬読】InternVL 1.5: オープンソースのマルチモーダル言語モデルの新たな地平
AI Nest
5か月前
10
大規模言語モデルのための合成データセットcosmopediaの中身を確認する
Kan Hatakeyama
7か月前
19
【論文瞬読】AGENTLESSが切り開く、LLMを用いたソフトウェア開発自動化の新時代
AI Nest
2か月前
13
データがなくても大丈夫!無料で使える学習用データを活用しよう~国内版~
DATA MINDS編集部@ワークスアイディDS東京
2か月前
7
【レポート】人工知能学会 全国大会2024in浜松に参加しました!
【PIXTA】機械学習データサービス
3か月前
7
arXiv trend: August 12, 2024
Ikemen Mas Kot
1か月前
2
X線診断の精度向上を実現する自己教師型AIの効果
0xpanda alpha lab
4か月前
12
社長(AI)に頼んで1万件(10K)の商用利用可能(llama2ライセンス)な日本語マルチターン会話データセットを作ってもらった
shi3z
8か月前
34
第3回: 画像生成AIの進化
Kajimoto Muneyoshi
3か月前
3
(後編) トランプチームは、CBDC (中央デジタル通貨)を導入するつもりなのかもしれません。確かに彼らはリアルIDを導入するつもりであり、これは "社会信用システム"の第一歩です。「あなたのお好きな未来をお選びください」by クリフ・ハイ (2024/5/20)
mayuLoveQ_17⭐️⭐️⭐️
4か月前
30
GPTからChatGPTへ:OpenAIの言語モデルの進化の歴史
yutohub
5か月前
8
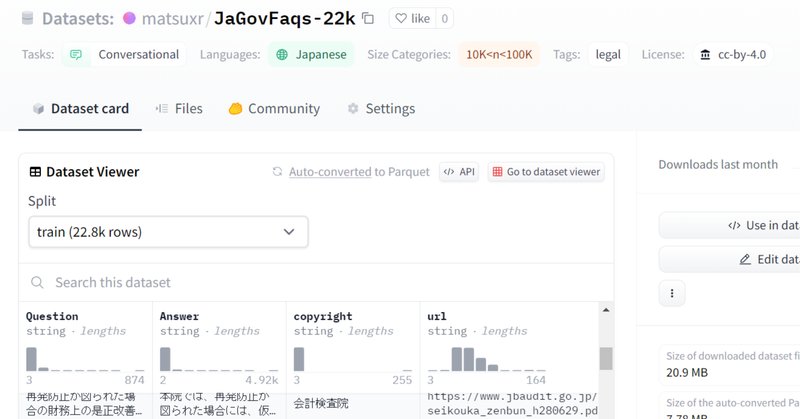
日本の官公庁にある「よくある質問」をデータセットにまとめました
松note
8か月前
55
arXiv trend: July 24, 2024
Ikemen Mas Kot
2か月前
2
いまさら聞けない!LLMを最適化する鍵、Scaling Law(スケーリング則)徹底解説【学習ソースあり】
0xpanda alpha lab
6か月前
22
【論文瞬読】マルチタスク言語理解ベンチマークMMLUの元論文を読んでみた
AI Nest
6か月前
12
巨大なプログラミング言語データセットThe Stackを少しだけ読み込んで表示するPythonコード
ウチダマサトシ
6か月前
9
ChatGPTのログをexportしてjsonlにするメモ (指示データセットに使いたい)
Kan Hatakeyama
5か月前
6
AIってどんな風に賢くなるの? 女子にもわかるAIの仕組み解説♡
べっく
1か月前
1
Are Large Language Models a Good Replacement of Taxonomies?
Ikemen Mas Kot
3か月前
4
日本語Wikipediaのマルチターン会話データセット10万個を作りました
shi3z
10か月前
58
【論文瞬読】常識的推論の評価は本当に常識的?WINOGRANDEが問いかけるAIの「理解」
AI Nest
6か月前
10
LLaMA-Reg: Using LLaMA 2 for Unsupervised Medical Image Registration
Ikemen Mas Kot
3か月前
5
データサイエンスの学習を始めるとぶち当たる人種問題の壁
ライトニングサンダー
6か月前
18
【寸劇】学習は盗みだ!!
七瀬葵
3か月前
2
社長(AI)に頼んで2万会話文の商用利用可(llama2)なデータセットを生成してもらった
shi3z
8か月前
21
大規模言語モデルの事前学習のためのデータセット、トークン数などの目安
Kan Hatakeyama
7か月前
17