
EDAツール魔法大戦に終止符を Ydata-Profiling, Sweetviz, Lux

以前こちらの記事で―
noteの分析をしたときも使いましたが、データエンジニアの中でも意外と存在を知られていないのが今回紹介するEDAツールです。
今回はそんな中から3つの代表的なツールを紹介します。
Ydata-Profilling
一番有名なのがYdata-Profillingです。
データセットの各種統計情報や注意すべきデータの状態、変数一つ一つの詳細情報、変数間の関係性まで丁寧に可視化してくれます。
一方でサイズが大きいデータセットだと読み込めなかったり、カスタマイズ性には少々欠けていたりします。

使い方は次のとおりです。
# install the package first
!pip install ydata-profiling
# import libraries
import pandas as pd
from ydata_profiling import ProfileReport
# read and create reports
df = pd.read_csv('data.csv')
profile = ProfileReport(mpg, title="Profiling Report")
profile.to_notebook_iframe()Sweetviz
今回紹介する3つの中で一番見た目に力を入れているのがSweetvizでしょう。
また2つのデータセットを比較しながらデータ探索できる点が大きな特徴となっています。
一方Ydata-Profillingに比べるとちょっと情報量が少なかったり、こちらもカスタマイズ性に乏しかったりするデメリットがあります。
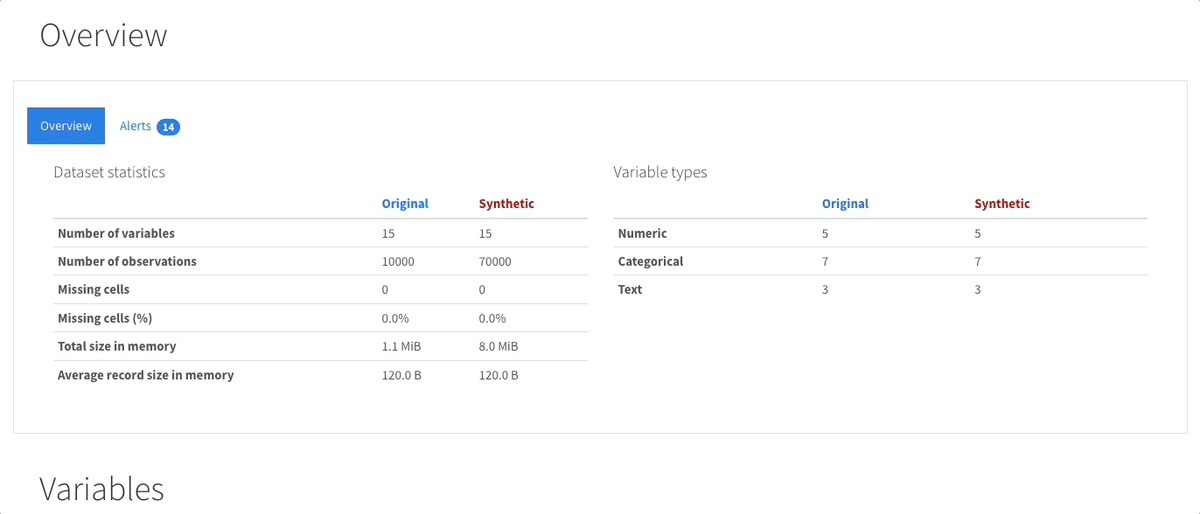
使い方は次のとおりです。
# install the package first
!pip install sweetviz
# import libraries
import sweetviz as sv
import pandas as pd
# read and create reports
df = pd.read_csv('data.csv')
report = sv.analyze(df)
report.show_html('Sweetviz_Report.html')Lux
Jupyter notebookの中でデータを見て深掘りながら使えるのがLuxの特徴です。
またデータの属性やユーザーとのやりとりによって適した可視化をおすすめしてくれるところもいいですね。
一方でユーザーとのやりとりが発生する分学習コストは他と比べて高めです。

使い方は次のとおりです。
# install the package first
!pip install lux-api
!pip install lux-widget
# import libraries
from google.colab import output
output.enable_custom_widget_manager()
import pandas as pd
import lux
df = df.read_csv('data.csv')
# create visualize
df.intent = ["column1", "column2"]
dfまとめ
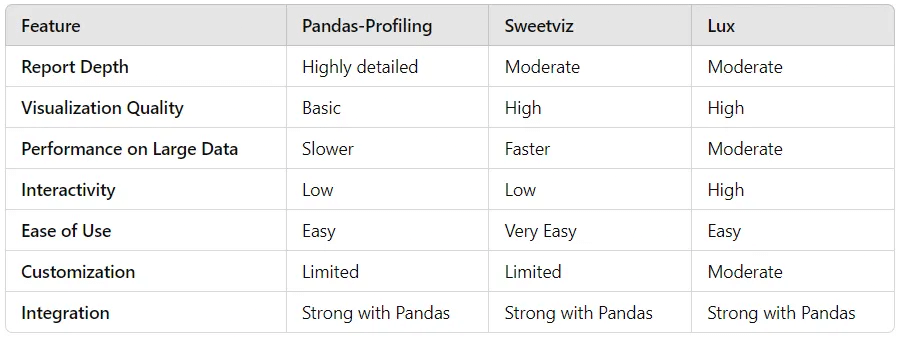
最後にまとめ表を貼っておきます。
この表を見ると分かる通り、データ探索をするうえで銀の弾丸はやはり存在せず、用途によって使いわける必要がありそうですね。
データやITを専門としない人にシンプルに知見を共有したいならYdata-Profillingですし、2つのデータセットの違いをサクッと共有したいならSweetviz、データサイエンティストがどんどんデータを深掘る使い方ならLuxがいいと思います。
参考
よろしければサポートお願いします! いただいたサポートはクリエイターとしての活動費に使わせていただきます!