
【論文瞬読】InternVL 1.5: オープンソースのマルチモーダル言語モデルの新たな地平

みなさん、こんにちは。株式会社AI Nestです。近年、自然言語処理と画像認識の融合により、テキストと画像を統合的に理解することができる大規模マルチモーダル言語モデル(MLLM)が注目を集めています。MLLMは、画像キャプショニング、ビジュアル質問応答、ドキュメント理解など、様々なタスクへの応用が期待されており、人工知能分野の重要な研究トピックの一つとなっています。
今回は、そんなMLLMの最新の研究動向として、オープンソースのMLLMである「InternVL 1.5」について紹介します。InternVL 1.5は、上海AI研究所を中心とする研究チームによって開発されました。彼らは、オープンソースのMLLMと商用のMLLMの性能ギャップを縮めることを目的に、InternVL 1.5の開発に取り組んできました。
タイトル:How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
URL:https://arxiv.org/abs/2404.16821
所属:Shanghai AI Laboratory, SenseTime Research, Tsinghua University, Nanjing University, Fudan University, The Chinese University of Hong Kong
著者:Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao
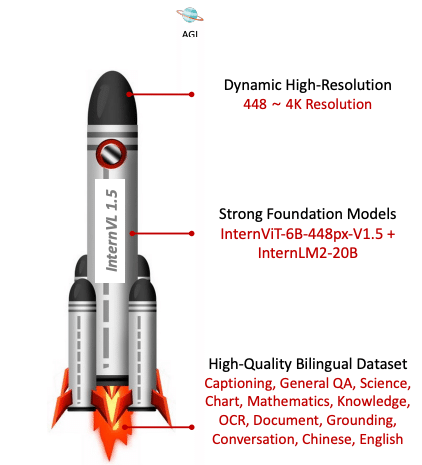
InternVL 1.5の特徴
InternVL 1.5は、以下の3つの特徴を持っています。
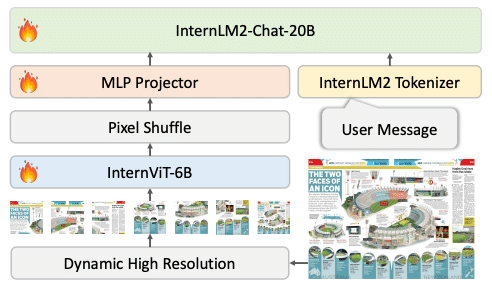
InternViT-6Bという強力なビジョン事前学習モデルを使用: InternVL 1.5は、InternViT-6Bという大規模なビジョン事前学習モデルをベースにしています。InternViT-6Bは、大量の画像とテキストのペアを用いて事前学習されたモデルであり、豊富な視覚的知識を持っています。InternVL 1.5は、このInternViT-6Bを継続学習することで、さらに強力なビジョン理解能力を獲得しています。
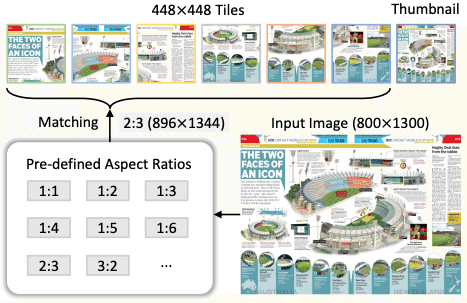
最大4K解像度の画像を動的に分割して入力可能: 高解像度の画像を処理することは、ドキュメント理解などの実世界のタスクにおいて重要です。InternVL 1.5は、最大4K解像度の画像を動的に分割し、それぞれの領域を独立に処理することができます。これにより、詳細な情報を損なうことなく、効率的に高解像度の画像を処理することが可能になります。
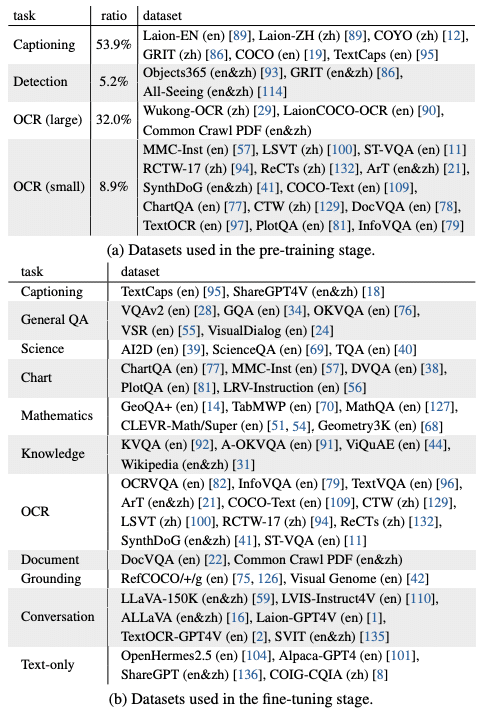
英語と中国語の高品質なデータセットを使用: InternVL 1.5は、英語と中国語の大規模かつ高品質なデータセットを用いて学習されています。このデータセットには、日常シーンの画像とその説明、ドキュメント画像とそれに関連する質問応答のペアなどが含まれています。多言語のデータを用いることで、InternVL 1.5は英語と中国語の両方で高い性能を発揮することができます。
性能評価
InternVL 1.5の性能は、18のベンチマークを用いて評価されました。これらのベンチマークは、OCR関連タスク、一般的なマルチモーダルタスク、数学的推論タスク、マルチターン対話タスクなど、多岐にわたります。
評価の結果、InternVL 1.5はOCR関連タスクと中国語の理解において特に優れた性能を示しました。具体的には、InternVL 1.5は、DocVQA、ChartQA、TextVQAなどのOCR関連のベンチマークで、他のオープンソースモデルや商用モデルを上回る性能を達成しました。また、中国語の理解を要するタスクにおいても、InternVL 1.5は商用モデルを上回る性能を示しました。
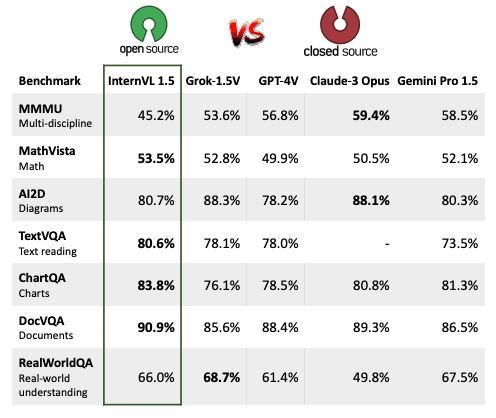
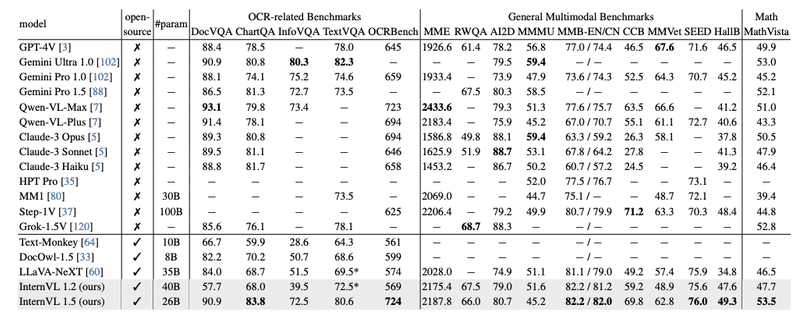
16のマルチモーダルベンチマークで比較
これらの結果は、InternVL 1.5が商用モデルとの性能ギャップを大幅に縮めることに成功したことを示しています。InternVL 1.5の登場により、オープンソースのMLLMが実用レベルの性能を達成しつつあることが明らかになりました。
感想
InternVL 1.5の研究を読んで、いくつかの興味深い点があったので共有します。
地道な改善の積み重ねの重要性: InternVL 1.5の性能向上には、ビジョンモデルの継続学習やデータセットの拡張といった地道な努力の積み重ねが大きく寄与していました。新規性の高いアイデアを追求することも重要ですが、着実な改善の積み重ねがブレークスルーにつながることを再認識しました。
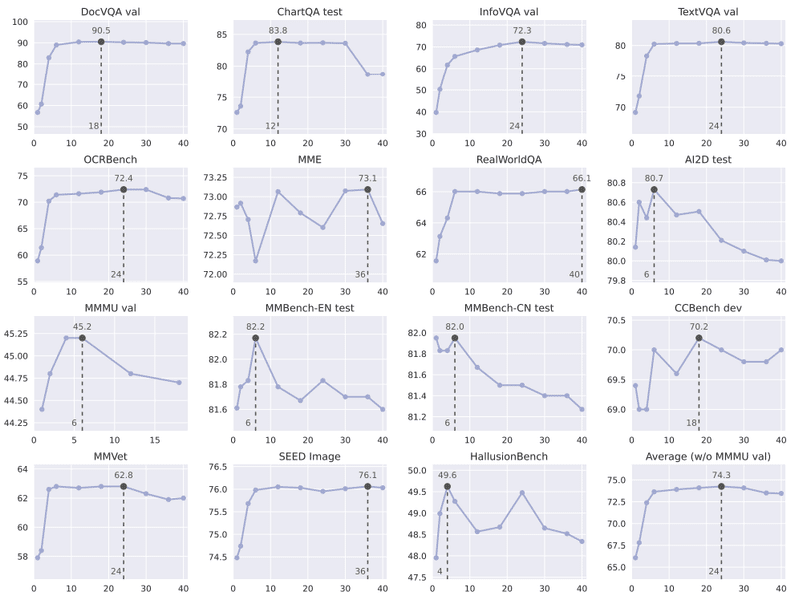
タスクに応じた最適な解像度の選択: InternVL 1.5は、動的な高解像度入力により、ドキュメント理解などの実世界のタスクにおいて高い性能を発揮しました。一方で、すべてのタスクで高解像度が効果的というわけではないことも示唆されていました。タスクの特性に応じて、適切な解像度を選択することが重要だと感じました。
多言語対応の重要性: 英語と中国語のバイリンガルモデルであることも、InternVL 1.5の大きな強みの一つです。グローバル化が進む中、多言語対応は、MLLMの実用性を高める上で欠かせない要素になっていくでしょう。今後、さらに多くの言語への対応が進むことを期待しています。
一方で、InternVL 1.5の研究には、いくつかの課題や改善点もあると感じました。例えば、モデルのスケーラビリティについては十分に議論されておらず、より大規模なモデルへの発展可能性については不明確でした。また、モデルの詳細なアーキテクチャについても、再現性の観点からより詳細な説明が望まれます。これらの点は、今後の研究の発展に向けた課題であると言えるでしょう。
おわりに
InternVL 1.5は、MLLMの発展に重要な貢献をする研究であり、今後のさらなる発展に期待が持てる内容でした。InternVL 1.5のソースコードとモデルの重みが公開されることで、多くの研究者や実践者がこの成果を活用し、MLLMの研究がさらに加速することを楽しみにしています。
同時に、InternVL 1.5の研究から、MLLMの発展には、新規性の高いアイデアだけでなく、着実な改善の積み重ねが重要であることを学びました。また、多言語対応やタスクに応じた最適な設定の選択など、実用性を高めるための要素にも目を向ける必要があります。
以上、InternVL 1.5についての紹介でした。MLLMに関心をお持ちの読者の皆さまにとって、有益な情報となれば幸いです。