
新しいRAGの仕組み!マイクロソフト、新技術GraphRAGをオープンソース化!

先週、マイクロソフトがオープンソース化した新しいRetrieval Augmented Generation(RAG)システム「GraphRAG」は、知識グラフを活用して生成と推論能力を飛躍的に向上させます。これにより、複雑な情報の関連性を理解し、高精度な回答を提供することが可能になります。GraphRAGの詳細とその活用方法について見ていきましょう。
GraphRAGとは何か
GraphRAG(Graph-based Retrieval Augmented Generation)は、従来のRAG(Retrieval-Augmented Generation)技術をさらに一歩進めたものです。通常のRAGはベクトル類似性を用いた検索技術を利用しますが、GraphRAGはLLM(大規模言語モデル)を使って知識グラフを生成し、より高精度な情報検索と生成を可能にします。
公式ページ:https://microsoft.github.io/graphrag/
関連サイト:
👉 Microsoft Research Blog Post
👉 GraphRAG Accelerator
👉 GitHub Repository
👉 GraphRAG Arxiv
GraphRAGの仕組み
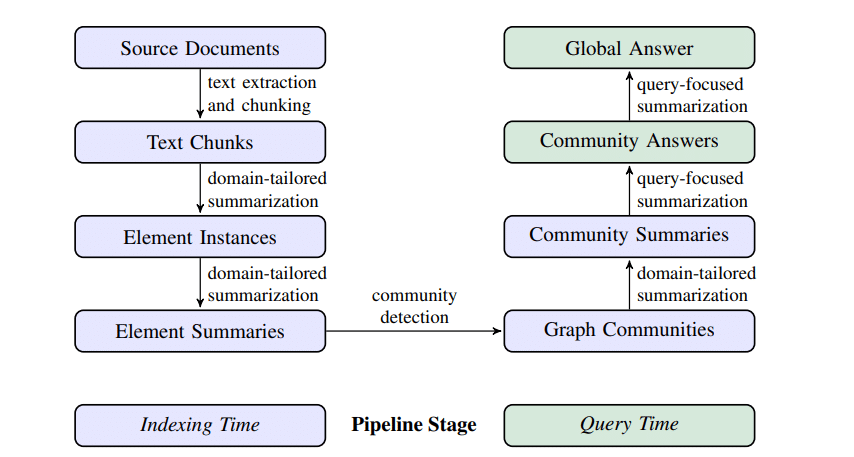
GraphRAGは以下のステップで動作します:
インデックス作成:入力コーパスをTextUnitsと呼ばれる解析単位に分割します。
エンティティ抽出:LLMを使用して、TextUnitsからエンティティ、関係、および重要な主張を抽出します。
階層クラスタリング:Leiden技法を用いてグラフを階層的にクラスタリングします。
コミュニティ要約の生成:下位から上位への要約を生成し、データセットの全体的な理解を支援します。
これらの構造は、クエリ時にLLMのコンテキストウィンドウに提供され、質問に答える際に使用されます。
GraphRAGの利点と特徴
精度の向上:知識グラフに基づくため、従来のベクトル検索に比べて情報の関連性が高まり、質問に対する回答の精度が向上します。
複雑な情報の理解:エンティティ間の関係性を把握することで、複雑な情報をより効果的に理解し、回答を生成します。
全体的なテーマの把握:データセット全体をセマンティッククラスタリングし、主要なテーマを要約することができます。
GraphRAGの主な用途
GraphRAGは、多くの文書にまたがる情報を統合し、キーワードやベクトルベースの検索メカニズムでは回答が難しい質問に答えることができます。たとえば、「このデータセットの主要なテーマは何か」といった抽象的な質問にも対応できます。GraphRAGは、ドメイン固有のテキストデータコーパスで使用することを想定しており、高度な分析と洞察を提供します。
GraphRAGの評価方法
GraphRAGの評価は、以下の基準に基づいて行われます:
データセットの正確な表現:手動検査と自動テストを組み合わせて実施。
応答の透明性と根拠の提示:自動カバレッジ評価と人間による文脈検査。
プロンプトおよびデータコーパスの攻撃に対する耐性:手動および半自動技術を用いてテスト。
低い幻覚率:主張カバレッジメトリクス、手動検査、および敵対的攻撃を通じて評価。
GraphRAGの限界とその克服方法
GraphRAGは、適切に構築されたインデックス例に依存します。一般的なアプリケーション(人、場所、組織、物事などに関連するコンテンツ)では、例示的なインデックスプロンプトが提供されますが、ユニークなデータセットでは、ドメイン固有の概念を適切に特定する必要があります。インデックス作成はコストがかかるため、最初にターゲットドメインの小規模なテストデータセットを作成し、インデクサーのパフォーマンスを確認することが推奨されます。
運用上の考慮事項と設定
GraphRAGは、高度な情報処理に取り組む経験豊富なユーザー向けに設計されています。信頼できるユーザーがシステムの出力を適切に解析し、得られた洞察を検証することが重要です。GraphRAGは、全体的なトピックやテーマに焦点を当てた自然言語テキストデータに対して最も効果的な結果をもたらします。
結論
GraphRAGは、知識グラフを活用してLLMの生成と推論能力を大幅に向上させる新しいアプローチです。これにより、複雑な情報を扱う多くのシナリオで、より正確かつ関連性の高い回答を提供できるようになります。マイクロソフトのGraphRAGを導入することで、企業や研究機関は自社のデータを最大限に活用し、新たな洞察を得ることができるでしょう。