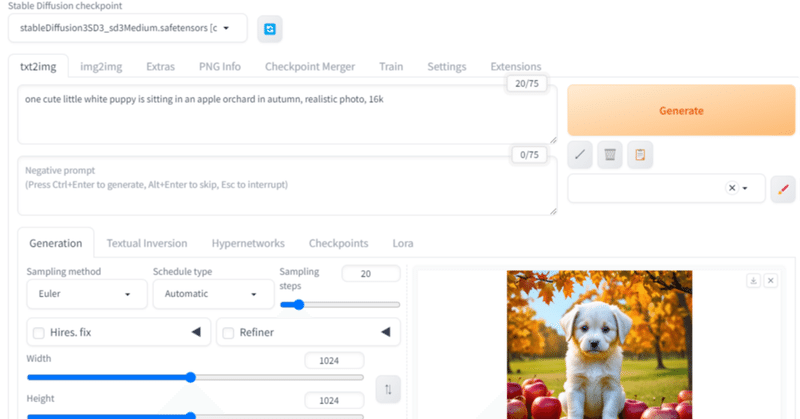
AUTOMATIC1111 がv1.10.xにアップデートでSD3Mをサポートしたという噂を聞きつけ試してみた
AUTOMATIC1111のアップデートとStable Diffusion 3 MediumStable Diffusion web UIといえばAUTOMATIC1111氏のものを基本的には指すと思います。ずいぶん浸透してきましたね。
一方で、そのweb UIで特にたくさん使われるはずであった新モデルStable Diffusion 3 Mediumの知名度は低いままの印象です。
とりあえず今回AUTOMATIC1111のアップデートにより、使える状況になったと聞いて試して