画像から効率的に3Dキャラを作ってくれる「CharacterGen」を試してみる
CharacterGenとはこれまたXでとても話題になっている「CharacterGen」。
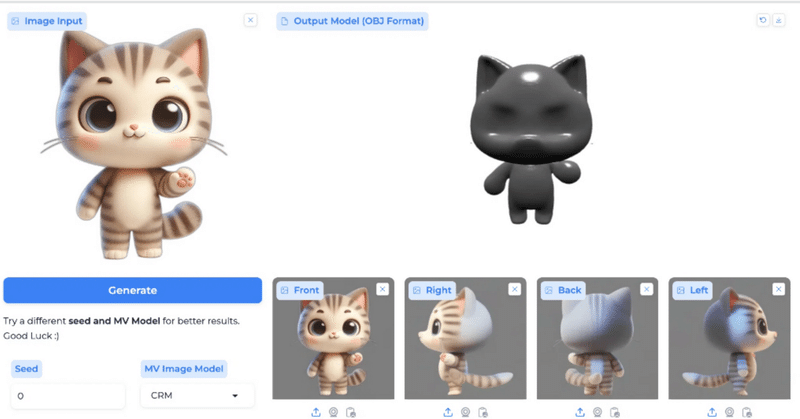
一枚のキャラクター画像から正面、左右、後ろの4面図を自動で作成。その後、3Dキャラクター化してくれます。
生成された3Dキャラクターは高品質な形状とテクスチャを持っていて、アニメーションやゲーム開発などの応用に役立ちます!
オープンソースなのでコード、デモ、学習済みのモデルが🤗で公開されています!これはやるっきゃない!
🌐プロジェクトページ類💪試してみる早速この男の子をいれて試して