
【論文瞬読】常識的推論の評価は本当に常識的?WINOGRANDEが問いかけるAIの「理解」

こんにちは!株式会社AI Nestです。
今回は、常識的推論の評価のための新しいデータセット「WINOGRANDE」を紹介する論文について、詳しく解説していきたいと思います。
タイトル:WINOGRANDE: An Adversarial Winograd Schema Challenge at Scale
URL:https://arxiv.org/abs/1907.10641
所属:Allen Institute for Artificial Intelligence, University of Washington
著者:Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, Yejin Choi
WSCからWINOGRANDEへ:常識的推論の評価の難しさ
常識的推論、つまり人間にとっては常識的に理解できることを機械に理解させるのは、AIにとって非常に難しい課題です。その評価のために、WSC (Winograd Schema Challenge) というデータセットが使われてきました。WSCは、人間には簡単だが機械学習モデルには難しい代名詞解消の問題を273問集めたものです。
しかし近年、BERTやRoBERTaといった強力な言語モデルがWSCの変種で90%近い精度を達成するようになりました。これは素晴らしい成果なのですが、果たして本当に「理解」しているのでしょうか?著者らは、モデルがデータセット中の望ましくないバイアス(統計的な偏り)を利用した「うわべだけの理解」をしている可能性を指摘しています。
そこで登場するのが、WSCを大規模化し、バイアスを除去したデータセット「WINOGRANDE」です。

Table 1は、WSCの典型的な問題と、データセット特有のバイアスがある問題を比較しています。バイアスのある問題では、特定の単語(例えば"exciting"や"very strong")が答えと強く関連付けられています。こうしたバイアスを利用すれば、文脈を理解せずとも正解できてしまうのです。
WINOGRANDEの作り方:クラウドソーシングとAFLITE
WINOGRANDEの作成は、大きく2つのステップに分かれます。
クラウドソーシングでWSC形式の問題を大量に作成
AFLITEアルゴリズムでバイアスを除去
まず、Amazon Mechanical Turkというクラウドソーシングプラットフォームを使って、WSC形式の問題を77,000問作成しました。その際、ワーカーにはWikiHowの記事からランダムに選んだ単語を使うように指示することで、多様で創造性のある問題を作ってもらいました。その後、別のワーカーによる検証を経て、53,000問に絞り込みました。
次に、このデータセットからバイアスを除去するために、AFLITEという新しいアルゴリズムを開発しました。AFLITEの手順は以下の通りです。
RoBERTaを6,000問でファインチューニング
残りのデータのRoBERTaの埋め込みを計算
データのサブセットでアンサンブル線形分類器を学習
分類器の予測がバイアスを反映していたらそのデータを除去

Figure 1は、AFLITEによるバイアス除去の効果を示しています。AFLITEを適用する前は、データの分布が答えラベル(0か1か)によって大きく異なっていましたが、適用後はその差が小さくなっています。つまり、バイアスが効果的に除去されたと言えるでしょう。
こうして、最終的に12,282問の難しい代名詞解消問題が得られました。これがWINOGRANDE(debiased)です。
WINOGRANDEの評価:人間vs最新モデル
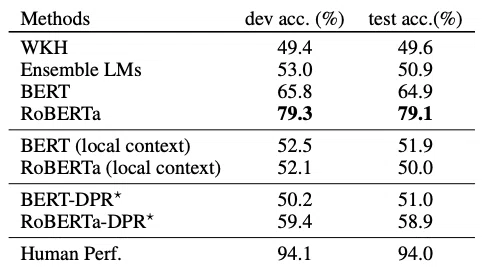
Table 3は、WINOGRANDE(debiased)における各モデルの性能を比較しています。人間の正解率が94%であるのに対し、最新モデルであるRoBERTaでも79.1%にとどまっています。この大きな差は、WINOGRANDEが常識的推論の難しさを適切に反映していることを示唆しています。

Figure 2は、RoBERTaがWINOGRANDE(debiased)の学習データの量を増やしていったときの性能変化を示しています。データ量が増えるほど性能は向上しますが、人間レベルの94%に到達するには、12万問以上のデータが必要と予測されます。これは、現在のモデルの限界を示す興味深い結果だと言えるでしょう。
さらに著者らは、WINOGRANDEを他のWSC関連タスクへの転移学習に利用し、そこでもState-of-the-art (SOTA) を達成しました。

Table 6は、WINOGRANDEを転移学習に使ったときの、他のWSC関連タスクでの性能を示しています。全てのタスクで大幅な性能向上が見られ、WINOGRANDEが常識的推論の評価に広く役立つことがわかります。
ただし、著者らはこれらのデータセットにもバイアスがある可能性を指摘しています。モデルの高い性能は、本当の「理解」ではなく、バイアスの利用によるものかもしれません。
まとめ
この論文の意義は、常識的推論の評価のための新しいデータセットWINOGRANDEを提案し、バイアス除去の重要性を示した点にあります。著者らは、近年の言語モデルの「理解」を過大評価している可能性が高いと指摘し、モデルが発展するにつれ、テストデータも更新し続ける必要性を訴えています。
ただし、バイアス除去の具体的なガイドラインは示されておらず、AFLITEの一般性についても更なる検証が必要でしょう。また、そもそも代名詞解消がどの程度「常識的推論」を必要とするのかについても議論の余地があります。
常識的推論の評価は非常に難しい課題であり、データセットの作成方法だけでなく、そもそも何をもって「常識的推論」とするのかについても、より深い議論が必要です。この論文はその重要な一歩を示したと言えるでしょう。
AIの「理解」とは何か。常識的推論の評価を通して、この根源的な問いを考え続けることが重要なのかもしれません。