大規模言語モデルの事前学習のためのデータセット、トークン数などの目安

はじめに
大規模言語モデルをフルスクラッチで作るにあたり、どれくらいの計算リソースやデータセットが必要になるか、目安がよくわからなかったので、調べました。
参考になるサイト
諸々の整理
BLOOMのテック記事
LLMとGPUとネットワーク (GPU枚数の試算など)
パラメータ数と学習トークン数のバランスをどうするか
学習時の最重要パラメータ(?)といえば、モデルサイズ(パラメータ数)と、学習データセットのサイズ(token数)です。
GPT-3ではパラメータ数≒トークン数くらいだったようです。
最近は、とにかくtoken数を稼ぎましょう(llama、Chincilla)、のような流れが出てきています。
Chinchilla の論文では、両者の最適なバランスについて議論されていました。

こちらの結果は、あくまでtraining loss基準のデータではありますが、少なくとも、モデルのパラメータ数の数倍くらいのtoken数はあると良いことは読み取れそうです。
※データセットのトークン数とファイルサイズの関係は自明ではありません。こちらの目安によると、、
トークン数 ファイル容量
GPT-2: 10 B 40 GB
GPT-3: 500 B 750 GB
学習にどれくらいのGPUが必要か?
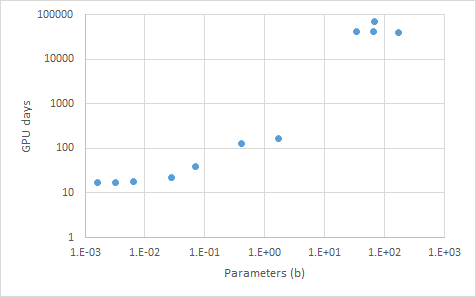
いくつかのwebサイトから、必要なGPU daysについて、実測データを収集してみました(参考1,2,3)。

とりあえずプロットしてみた結果は以下の通り。
プロジェクトごとにデータセットのトークン数は異なるものの、パラメータ数が増えるにつれて、GPU daysが増えることがわかります。
10Bモデルを作る際のデータセットや計算リソースの目安
例えば、10Bのモデルを作ることを考えてみます。
(かなりいい加減な試算です。間違っていたらすみません)
データセットサイズ
先程のChincillaの結果を目安にすると、少なくとも数十Bトークンくらいのデータセットは準備した方が良さそうです。
GPUリソース
上記のグラフからいくと、A100で1000GPU daysくらいは確保すると良さそうです。H100は3倍くらいの性能向上とすると、H100 x 300 GPU daysくらいでしょうか。
H100を20枚、準備できるとすると、ざっくり15日くらいで計算が終わることになりそうです。
蛇足: 日英でクロスリンガル転移はできるのか?
なんだかんだで日本語のデータは少ないのが現状です。
そこで、例えば、日英の両方のテキストを学習させることで、英→日の知識転移をすることができるのか、という期待が湧きます(クロスリンガル転移)。
プレプリントでの成功
以下が有名なプレプリントのようで、多言語の学習で、相乗効果的な性能向上が観測されたようです。2019年のやや古い論文(BERT?)なので注意。
特に優位性は観測されなかったとの報告(日英)
日本語とマルチ言語の混合データセットにおける大規模言語モデルの構築
0.4b程度のモデル、データセットはJapanese-mC4(300b)+THE PILE(300b)で学習させたようです。 日英を同時学習させても、性能は悪化も改善もしなかった模様です。 クロスリンガル転移は、一筋縄では行かないようです。
どちらかというと多言語の学習は逆効果という報告(英仏)
ガチのフランス語のLLMを作ろうというプロジェクトの論文がありました(24/2/13)
英仏のwikipedia(+プログラムコード)を同時に学習させながらlossを追うという予備検討をしたようです(下記)。
少なくとも2Bまでのモデルでは、多言語の学習は、特定の言語の学習にとって、むしろマイナスという結果になったようです。

equalは英仏のtokenが同じ、frplusはフランス語が多い、enplusは英語が多いケース
(1) 「equal」は、40%が英語データ、40%がフランス語データ、20%がコードデータ
(2) 「frplus」は、20%が英語データ、60%がフランス語データ、20%がコードデータ
(3) 「enplus」は、60%が英語データ、20%がフランス語データ、20%がコードデータ
英語の性能を上げたいなら、enplus > equal > frplus の順に高性能、フランス語はその逆、という感じです。少なくともこの検討では、英語の習得に、フランス語の学習はあまり役に立たなかったようです。
このプロジェクトでは最終的に、英仏を1:1にしてモデルを構築しました。
とりあえずやってみたとの報告
70bモデルの追加学習をしたようです。バッチ中に日英、両方のテキストを組み込むことで、クロスリンガル転移の発現を目指したようです。
プログラミング
ちょっと横道に逸れますが、プログラムコードを学習させると、言語モデルがロジカルになるかも?という研究もあるようです。
まとめ
大規模言語モデルをフルスクラッチで作るにあたり、必要なデータセットのサイズやGPUについて調べました。どの程度のリソースが必要なのか、なんとなくの手応えが見えてきました。
この記事が気に入ったらサポートをしてみませんか?