最近の記事

Python3.12以降でmatplotlibで日本語フォントを表示したいときは、matplotlib-fontjaをimportすると楽
matplotlibで日本語フォントを表示する際には、多くの人がuehara1414さんが作成されたjapanize-matoplotlibにお世話になっていたかと思います。importするだけで日本語フォント対応できるので、とても有り難いライブラリです。 ただ、Python3.12からはdistutilsが含まれなくなったため、japanize-matplotlibをインポートするときにエラーが発生します。 ここに対処するフォークとして、matplotlib-fontj






いつの間にかWindowsでもシンプルに pip install bitsandbytes でbitsandbytesが使えるようになっていた
LLMを使う時、4bit/8bit量子化をするなら必要になるbitsandbytesというライブラリがあります。今までWindowsは正式にはサポートされておらず、公式以外のビルドを使ったりなどの工夫が必要でした。 ところが、3週間くらい前にリリースされたbitsandbytesのリリース情報を見ていたら、最新の0.43.0でWindowsがサポートされたとありました。 「多分、公式にpip install bitsandbytesでWindowsもサポートできたと思うよ
llm-jp/llm-jp-13b-dpo-lora-hh_rlhf_ja-v1.1 のLoRAファイルをマージして使ってみる
LLM-jpから、新しい13bモデルであるversion 1.1が公開されました。先に公開されていた1.0のモデルに対して、新しいデータセットでのインストラクションチューニングを加えたものみたいです。理研が進めている自然な日本語のデータセットichikaraを使っているのもポイント。 このモデルのいいところは、日本語に強い13bモデルとしては珍しい、Apache 2.0ライセンスであることです。モデルはもちろん、生成結果も自由に利用出来るので、様々な活用や遊びができそうです

UnityからStyle-Bert-VITS2のAPIを呼ぶときに、BudouXのUnity版であるUniBudouXを使ってテキストを自動的に100文字以下に分割して音声合成する
趣味でAITuberを作っています。UnityでVRMを表示し、発話の生成はローカルLLMで。そして音声合成はローカルで動かしているStyle-Bert-VITS2をつくよみちゃんコーパスで学習させたものを使わせてもらっています。以下が最初のテスト配信です。合成音声コンテンツの本場はニコニコだろうということでニコ生でやりました。今後もニコ生メインでやってみたい。 UnityからStyle-Bert-VITS2を呼び出すときは、Style-Bert-VITS2のAPIサーバー
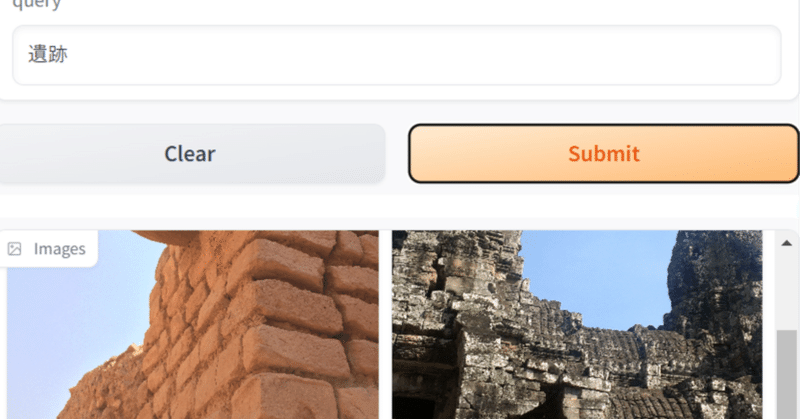
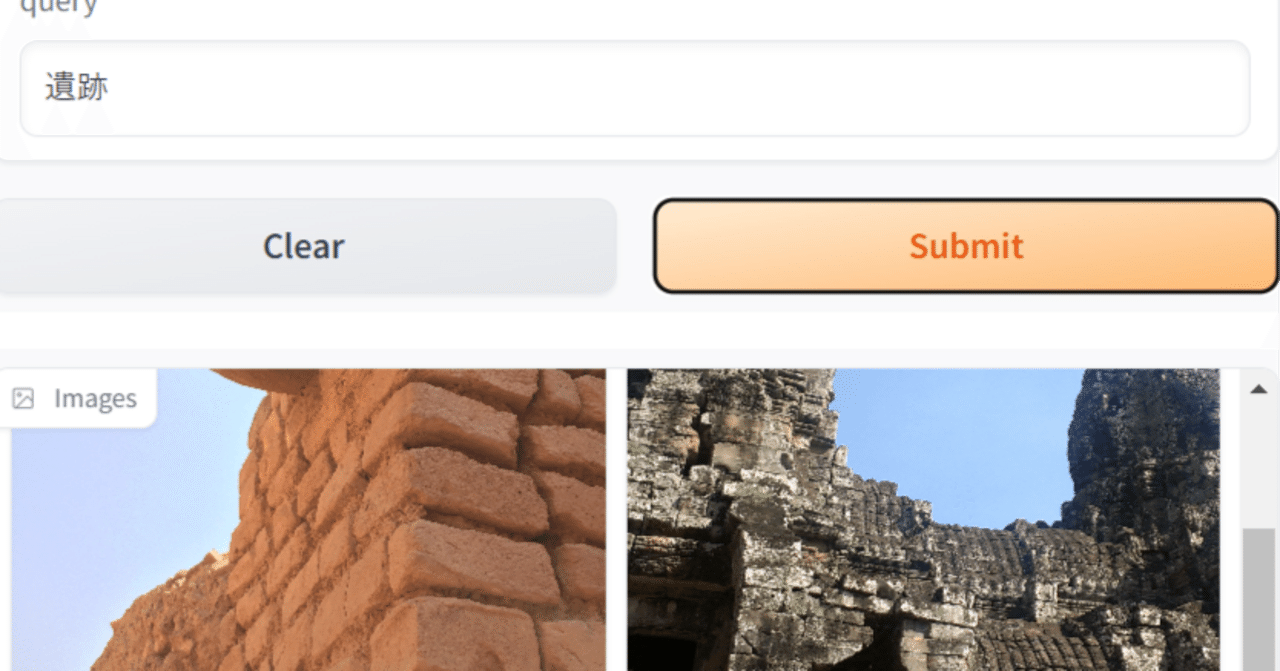
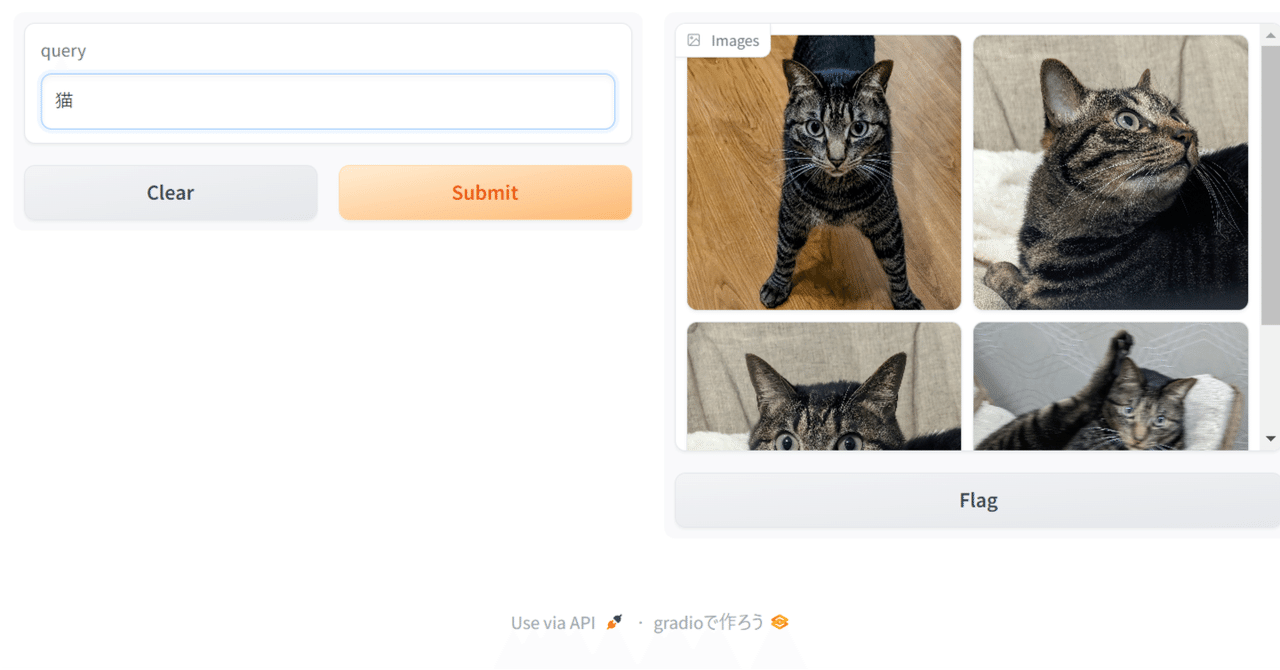
リクルートからも日本語CLIPが来た! recruit-jp/japanese-clip-vit-b-32-roberta-base を使って、ローカルの画像を日本語で検索してみる
一昨日、Googleのmultiligual SigLIPを使って画像検索する記事を書いたところで、なんと、昨日、リクルートからも日本語対応のCLIPが出ました。しかも商用可能なCC-BY-4.0ライセンス!ヤバい。今年はローカルで動くマルチモーダルがアツい年になりそうです。 CLIPとはスーパー雑に言えば、画像とテキストを同じ空間のベクトルにできるモデルで、テキストと画像が「近いか」を判定したりできます。この性質を利用して、任意のテキストタグで画像を分類したりできます。
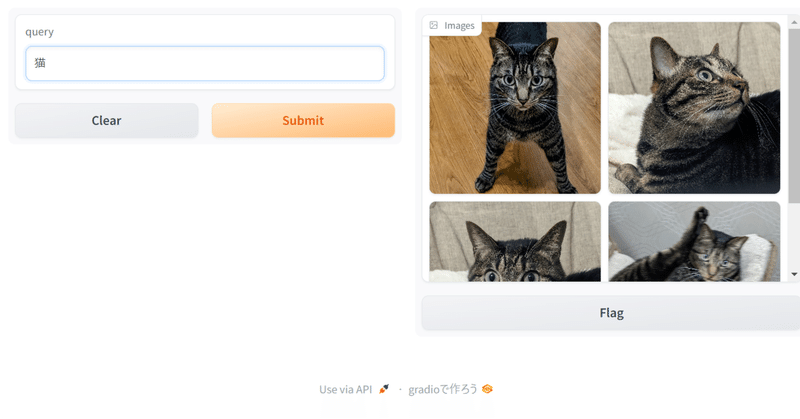
google/siglip-base-patch16-256-multilingual を使って、ローカルの画像を日本語で検索してみる
今年1月に、Googleから、SigLIPという、画像とテキストの両方をベクトルとして扱うことができるモデルのmultilingual版(多言語対応版)が公開されました。transformers 4.37以降で対応しています。日本語も対応しています。 これを使って、以前、昨年11月に公開された stabilityai/japanese-stable-clip-vit-l-16 を使ってやってみたときと同じように、ローカルの画像を日本語で検索してみるというのをやってみました。