記事一覧




Python3.12以降でmatplotlibで日本語フォントを表示したいときは、matplotlib-fontjaをimportすると楽
matplotlibで日本語フォントを表示する際には、多くの人がuehara1414さんが作成されたjapanize-matoplotlibにお世話になっていたかと思います。importするだけで日本語フォント対応できるので、とても有り難いライブラリです。
ただ、Python3.12からはdistutilsが含まれなくなったため、japanize-matplotlibをインポートするときにエラー

マルチモーダルembeddigモデルE5-Vを試してみる
画像と文字列を同じ埋め込みベクトル化できるマルチモーダルなembeddingモデルE5-Vというものを知ったので、試してみました。
画像と文字列を共にベクトル化できるとなると、先行するものとしてCLIPやSigLIPがありますが、このE5-Vは画像も理解するLLMであるLLaVA-NeXT-8Bをベースにしていることから、文章理解力が上がっているようです(上記論文参考)。
画像と文字列とでモダ

アイシア・ソリッドさんの動画を見続けたらG検定に受かった話 ディープラーニングを学ぶのにオススメYouTube3選
日本ディープラーニング協会が実施しているG検定という試験があります。ディープラーニングにまつわる話題について一通り理解しているかを問う試験内容で、1960年代からつい最近の生成AIまで、機械学習の歴史を浅く広く出題する感じ。暗記問題の4択なので、エンジニアではなく、技術系の会社の営業や広報の人向けかもしれないです。
国家資格ではないので受かったから何か意味があるかと言えばないかもしれませんが、私

いつの間にかWindowsでもシンプルに pip install bitsandbytes でbitsandbytesが使えるようになっていた
LLMを使う時、4bit/8bit量子化をするなら必要になるbitsandbytesというライブラリがあります。今までWindowsは正式にはサポートされておらず、公式以外のビルドを使ったりなどの工夫が必要でした。
ところが、3週間くらい前にリリースされたbitsandbytesのリリース情報を見ていたら、最新の0.43.0でWindowsがサポートされたとありました。
「多分、公式にpip

ReazonSpeech v2, whisper-large v3, nue-asrを比較してみた
今年2024年の2月14日に、日本語音声の文字起こしエンジンReazonSpeechのv2がリリースされました。NVIDIAのNemoを採用し、学習データセットも強化され、Fast Conformerという手法により高速化されたそうです。強そう。
同じく今年の1月に、transformersが4.73になり、OpenAIによる文字起こしエンジンwhisperが、transfomersでBatch

UnityからStyle-Bert-VITS2のAPIを呼ぶときに、BudouXのUnity版であるUniBudouXを使ってテキストを自動的に100文字以下に分割して音声合成する
趣味でAITuberを作っています。UnityでVRMを表示し、発話の生成はローカルLLMで。そして音声合成はローカルで動かしているStyle-Bert-VITS2をつくよみちゃんコーパスで学習させたものを使わせてもらっています。以下が最初のテスト配信です。合成音声コンテンツの本場はニコニコだろうということでニコ生でやりました。今後もニコ生メインでやってみたい。
UnityからStyle-Ber
AI, LLM, VR/ARの情報を得るためのRSSリスト(たまに更新)
最近、X(Twitter)が怖い感じになってきた気がします。元気なときはいいのですが、気分が沈んでいるときに見ると刺激的すぎる投稿が上がってきていたりします。
というわけで、しばらく、Xを見ないことにしてみました。AndroidスマホはWellbeingというところから、iPadはスクリーンタイムから、それぞれXのアプリ・Webにアクセスできないように設定しました。PCでも、以下のChrome拡
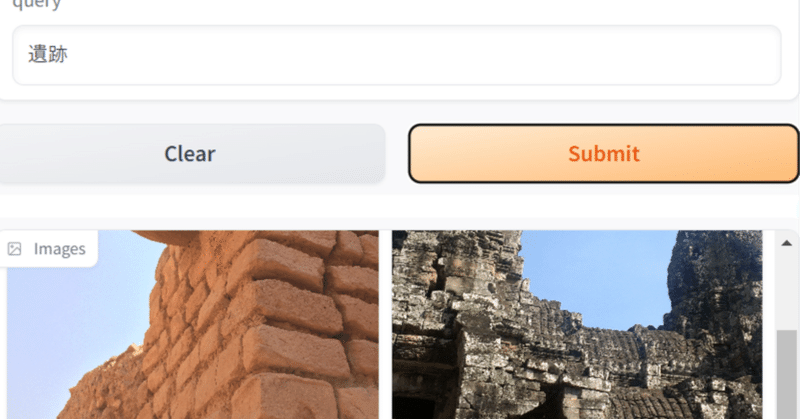
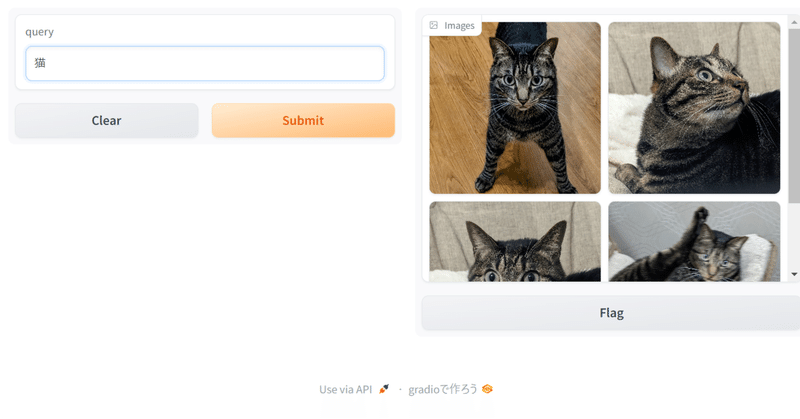
リクルートからも日本語CLIPが来た! recruit-jp/japanese-clip-vit-b-32-roberta-base を使って、ローカルの画像を日本語で検索してみる
一昨日、Googleのmultiligual SigLIPを使って画像検索する記事を書いたところで、なんと、昨日、リクルートからも日本語対応のCLIPが出ました。しかも商用可能なCC-BY-4.0ライセンス!ヤバい。今年はローカルで動くマルチモーダルがアツい年になりそうです。
CLIPとはスーパー雑に言えば、画像とテキストを同じ空間のベクトルにできるモデルで、テキストと画像が「近いか」を判定した