
いつの間にかWindowsでもシンプルに pip install bitsandbytes でbitsandbytesが使えるようになっていた

LLMを使う時、4bit/8bit量子化をするなら必要になるbitsandbytesというライブラリがあります。今までWindowsは正式にはサポートされておらず、公式以外のビルドを使ったりなどの工夫が必要でした。
ところが、3週間くらい前にリリースされたbitsandbytesのリリース情報を見ていたら、最新の0.43.0でWindowsがサポートされたとありました。

「多分、公式にpip install bitsandbytesでWindowsもサポートできたと思うよ」的な事が書いてあります。
Windows should be officially supported in bitsandbytes with pip install bitsandbytes
というわけで早速、新しい仮想環境を作って pip install bitsandbytes してみました。
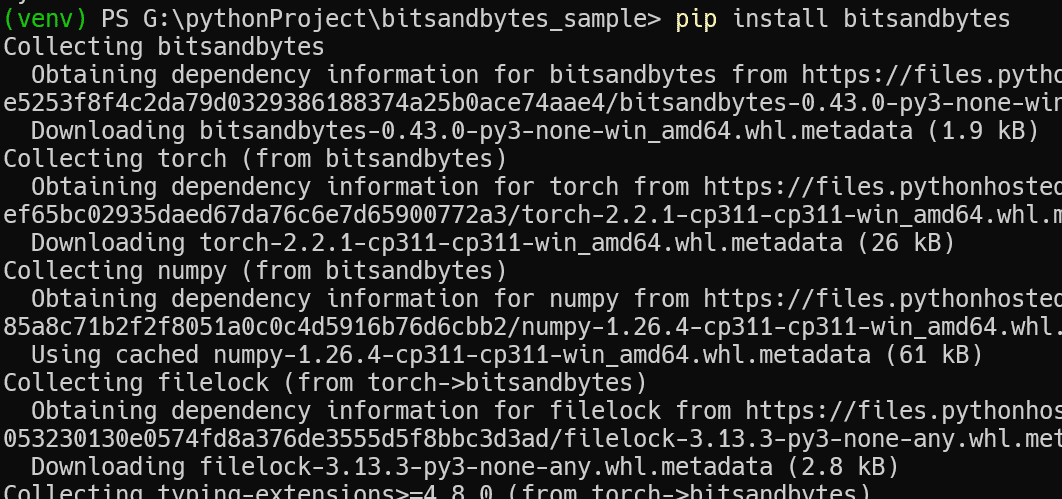
おお、ちゃんとインストールできたみたい。試しに python -m bitsandbytes で試験してみたら、torchがCUDA有効でコンパイルされてないよ! と怒られました。pip install bitsandbytesで自動的にインストールされるtorchはCUDA版はインストールされないみたいです。
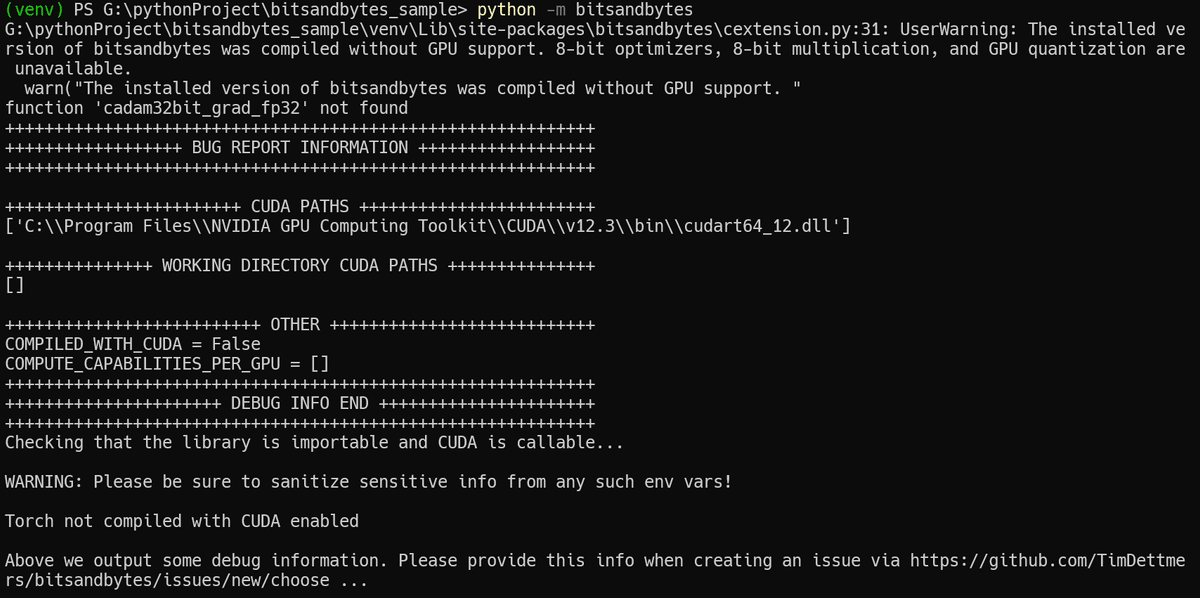
そこで、一旦、pip uninstall torch torchaudio torchvision でtorchをアンインストールし、
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
でCUDA有効のtorchをインストールし直しました。(Windows上にCUDAはセットアップ済みの状態です)
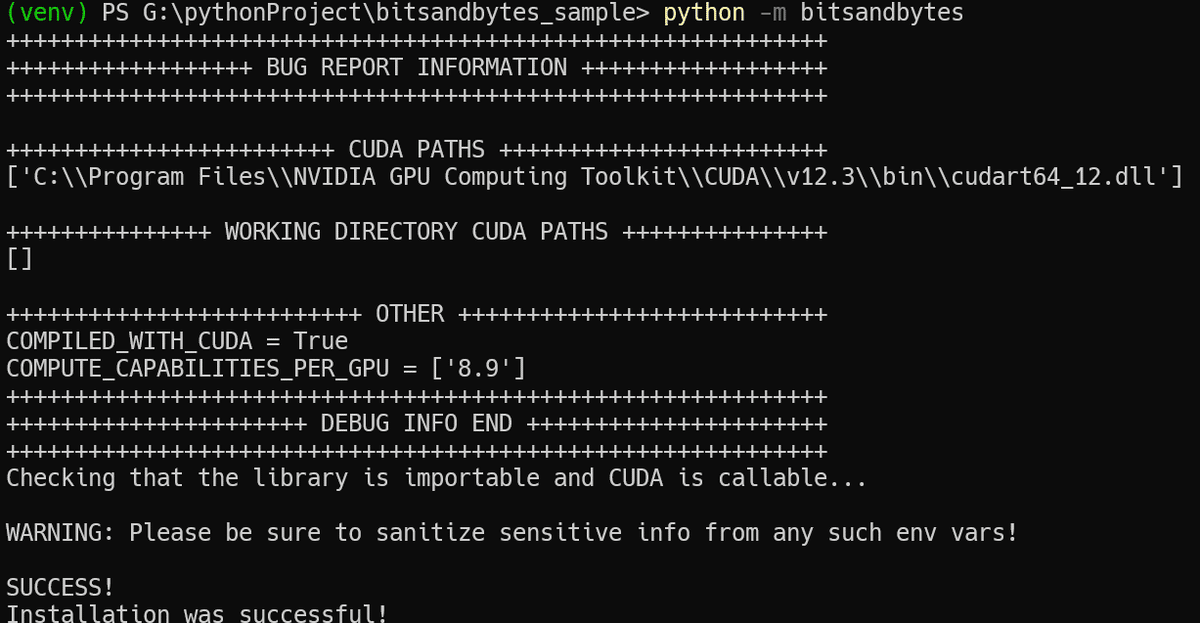
そして改めて python -m bitsandbytes を実行してみると、SUCCESS! の文字が出ました! インストールできてる!
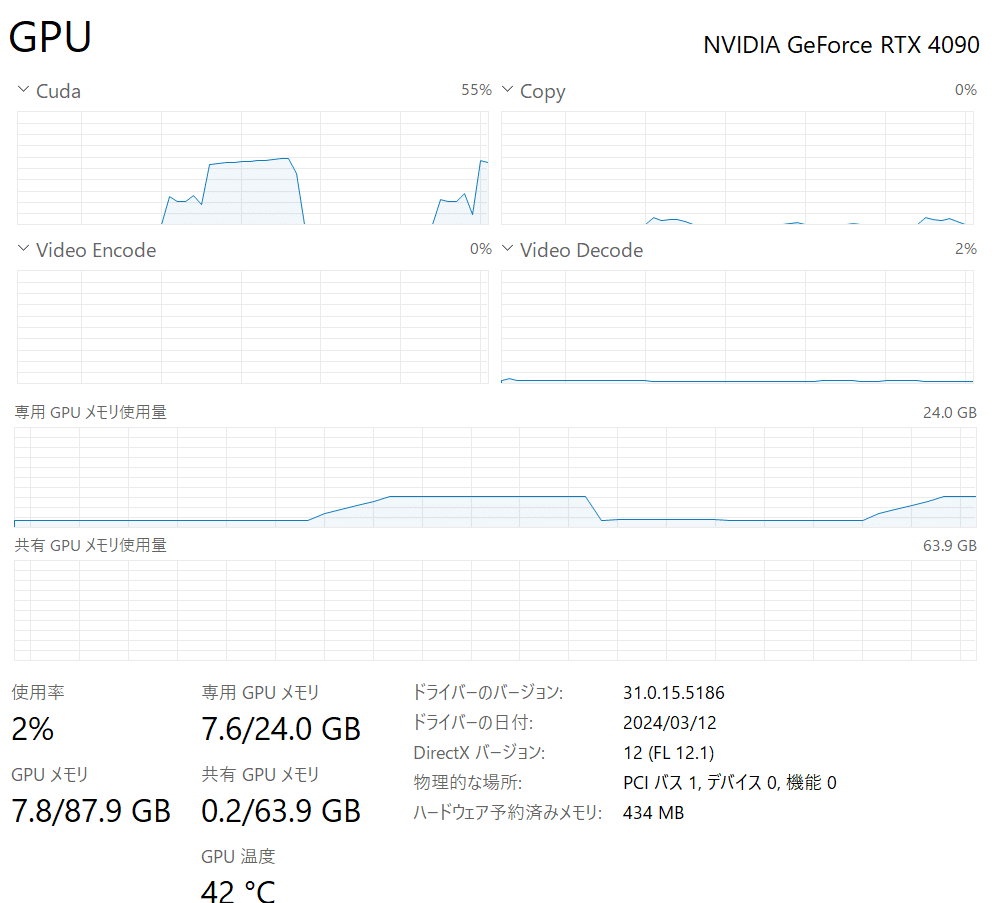
試しに、つい最近リリースされた mistralai/Mistral-7B-Instruct-v0.2 をload_in_4bit=Trueで動かしてみたら、ちゃんとVRAM消費量8GB以下で動いてました!
動かしてみたソースです。pip install transformers を先に実行しておいてください。
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2",
load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
messages = [
{"role": "user", "content": "どんな調味料が好きですか?"},
{"role": "assistant", "content": "レモン果汁がオススメです。"},
{"role": "user", "content": "マヨネーズを使ったレシピを教えてください。"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
generated_ids = model.generate(encodeds, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])出力結果は以下です。mistralはv0.2になったとはいえ、素のままだと日本語は修行中という感じですね。
The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
`low_cpu_mem_usage` was None, now set to True since model is quantized.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 3/3 [00:04<00:00, 1.49s/it]
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
G:\pythonProject\bitsandbytes_sample\venv\Lib\site-packages\transformers\generation\utils.py:1460: UserWarning: You are calling .generate() with the `input_ids` being on a device type different than your model's device. `input_ids` is on cpu, whereas the model is on cuda. You may experience unexpected behaviors or slower generation. Please make sure that you have put `input_ids` to the correct device by calling for example input_ids = input_ids.to('cuda') before running `.generate()`.
warnings.warn(
G:\pythonProject\bitsandbytes_sample\venv\Lib\site-packages\bitsandbytes\nn\modules.py:391: UserWarning: Input type into Linear4bit is torch.float16, but bnb_4bit_compute_dtype=torch.float32 (default). This will lead to slow inference or training speed.
warnings.warn('Input type into Linear4bit is torch.float16, but bnb_4bit_compute_dtype=torch.float32 (default). This will lead to slow inference or training speed.')
G:\pythonProject\bitsandbytes_sample\venv\Lib\site-packages\transformers\models\mistral\modeling_mistral.py:688: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at ..\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:263.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
<s> [INST] どんな調味料が好きですか? [/INST]レモン果汁がオススメです。</s> [INST] マヨネーズを使ったレシピを教えてください。 [/INST] マレーン坚 meatballs in tomato sauce はお勧めです。以下に、基本的なレシピを紹介します。
Ingredients:
- 1 lb (0.5 kg) ground beef
- 1/2 cup chopped onion
- 1/2 cup chopped celery
- 1/2 cupbreadcrumbs
- 1/2 cup milk
- 1 egg
- 1 clove garlic, minced
- 1 tbsp soy sauce
- 1 tbsp Worcestershire sauce
- 1 tbsp ketchup
- 1 tbsp mustard
- 1 tbsp parsley, chopped
- Salt and pepper to taste
- 2 tbsp olive oil
- 1 can (28 oz / 796 ml) tomato sauce
- 2 tbsp tomato paste
- 2 tbsp sugar
- 1/4 cup water
- 1 tsp dried basil
- 1 tsp dried oregano
- 1 tsp dried thyme
Procedure:
1. Preheat oven to 350°F (180°C).
2. In a large bowl, combine ground beef, onion, celery, breadcrumbs, milk, egg, garlic, soy sauce, Worcestershire sauce, ketchup, mustard, parsley, salt, and pepper. Mix well.
3. Form mixture into mini meatballs.
4. Heat olive oil in a large skillet over medium heat. Cook meatballs until browned on all sides.
5. Transfer meatballs to a baking dish.
6. In the same skillet, add tomato sauce, tomato paste, sugar, water, basil, oregano, thyme, and bring to a simmer.
7. Pour sauce over meatballs in the baking dish.
8. Bake for 30 minutes.
Serves 4-6.
Enjoy your meal!
この記事が気に入ったらサポートをしてみませんか?