Llama.cppのOpenAI互換モードを使って、OpenAIから少ない手間でローカルLLMに乗り換える

ご家庭のパソコンで簡易ChatGPTみたいなものが動かせるローカルLLMと呼ばれるものがあります。金融などハイレベルな機密情報を扱う企業などはクラウドに情報を簡単に出せないため、クローズドな環境でChatGPTみたいなことをしたいというニーズに応える活用例も考えられています。単純にホビーとして動かすのも楽しいです。
そんなローカルLLMを動かすために、開発が進んでいるのがLlama.cppです。GPUがなくても、CPUだけでも動かすことができ、Raspberry Pi 4のような小さなコンピューターでも動きます(遅いですが)。
そんなLlama.cppですが、サーバーとして動かすことができます。ローカルホストで起動させ、httpリクエストを投げる形で使えるので、様々なプログラムと連携させることが可能です。
Llama.cppをサーバーとして立ち上げる
サーバーとして起動する方法は、Llama.cppをビルドしたら、コマンドラインでserver.exeを立ち上げるだけです(Windowsの場合)
g:\llama.cpp\build\bin\Release\server.exe -m "G:\llama.cpp\models\ELYZA-japanese-Llama-2-13b-fast-instruct-q5_K_M.gguf" -ngl 99 -c 4096オプションはそれぞれ、以下の意味です。GPU有効でビルドするのと、レイヤー数については、本稿の後半で軽く触れます。
-m の後にgguf形式になったモデルのある場所
-ngl の後の数字は、GPUにオフロードするレイヤーの数(GPU有効でビルドした場合)
-c の後の数字はコンテキスト幅(すごく雑に言えば扱う文字数に対応する数)
このサーバーには、標準では以下のURLにリクエストするようになっています。(curlでの例)
curl --request POST --url http://localhost:8080/completion --header "Content-Type: application/json" --data '{"prompt": "Building a website can be done in 10 simple steps:","n_predict": 128}'
すると、オプションがたくさんあるので、使いこなしたい方は↑のURLからドキュメントを読んでみてください。
OpenAI互換モードで使う
Llama.cppのserverは、実は http://localhost:8080/v1/chat/completions というエンドポイントでもリクエストを受け付けています。これが、OpenAI互換モードです。入力と出力がOpenAIのgpt-3.5-turboやgpt-4と同じになるので、OpenAIのライブラリをそのまま使うことができるようになります。Pythonの場合、普通に
pip install openaiでOpenAIのパッケージをインストールした後、呼び出すときに base_url="http://localhost:8080/v1" を足すだけです。
import openai
client = openai.OpenAI(
base_url="http://localhost:8080/v1", # この1行を追加
api_key = "APIキーは使わないのでなんか適当な文字列でOKです"
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたはChatGPTのふりをしたローカルAIです。"},
{"role": "user", "content": "クラウドの大型AIとローカルの小型AIの違いを述べてください"}
]
)
print(completion.choices[0].message.content)クラウドの大型AIとローカルの小型AIの違いを述べます。
クラウドの大型AIは、インターネット上に設置された大規模サーバーに訓練データやアルゴリズムを保存しており、様々なユーザーからの質問や要求に処理能力を活用して回答しています。一方、ローカルの小型AIは、ユーザーの端末内に訓練データやアルゴリズムを保存しており、ユーザーからの質問や要求に処理能力を活用して回答しています。
クラウドの大型AIとローカルの小型AIの違いをまとめると、配置の場所に違いがあることが挙げられます。クラウドの大型AIはインターネット上に設置されており、ローカルの小型AIはユーザーの端末内に配置されています。
model="gpt-3.5-turbo"と書かれていますが、もちろんgpt-3.5は使いません。ローカルのLlama.cppを使って推論し、JSONの形式はOpenAIのAPIと同じ形で返ってきます。
いままでOpenAIのAPIを使って作っていたスクリプトを最少の変更でローカルLLM利用に変えられます。世にある様々なサンプルスクリプトやライブラリ資産を活用できます。
また、たとえば、OpenAIのAPIの調子が悪いなと思ったら、自動的にローカルLLMに切り替えるという実装を書くのも、同じ形式なので楽でしょう。
私は趣味でAIキャラクターを作っているのですが、高度な受け答えはやはりOpenAIのほうが優れている一方で、倫理基準に厳しすぎたり、突然重くなって10秒経っても返事が返ってこないということがままあります。キャラクターとの対話をしようと思ったときに、これは結構、致命的です。そんなとき、すばやくローカルLLMに切り替えることで、スムーズな対話が進むようにしています。
具体的には、常に同じリクエストをローカルとOpenAI両方に投げておいてOpenAIが返事が遅かったり倫理チェックに引っかかった感じだったら、ローカルの返答のほうを採用する、という感じで制作中です。逆もありかもしれないですね。基本ローカルLLMだけど、対応できていないようだったらOpenAIのほうを採用する、みたいに。
使っていてわりと便利だと思ったので、記事にして見ました。
Llama.cppをGPUありでビルドする
Llama.cppはもともと、MacでLlamaを動かすのが当初の目的だったため、CPUで動かすのがメインの機能です。バージョンアップを重ねるに従って、NVIDIA、AMD、IntelのGPUを使って高速な推論ができるようになりました。その代わり、後から対応したので、やり方が若干複雑です。
hipBLAS、cuBLAS、CLBlastなど、GPUを使ったビルド方法だけでもたくさんあります。
WindowsでNVIDIAのGPUを使っていて、Visual Studio Build ToolsとCUDA ToolkitとCMakeをインストールしてある状態なら、cuBLASを使うのが楽な気がします。公式のドキュメントにあるとおり、以下の通りにビルドします。
git cloneしたフォルダに入り、以下のコマンドを実行します。
mkdir build
cd build
cmake .. -DLLAMA_CUBLAS=ON
cmake --build . --config Release
無事にビルドが完了すれば、※cloneしたフォルダ※\build\bin\Release\ に、server.exe ができているはずです。このserver.exeを、前述のように起動すれば、サーバーが立ち上がります。
-ngl の数字の意味
これはnumber of GPU laygersの略(だと思う)で、GPUに置くレイヤーの数を表しています。モデルに含まれるレイヤーを全てGPUに置けば、全部GPUで動くので早くなります。
じゃあそのレイヤーの数ってどうやって見るの、という話ですが、cuBLASを有効にしたserver.exeになにかggufのモデルを読み込ませて起動画面に出てくる、以下の部分が参考になります。
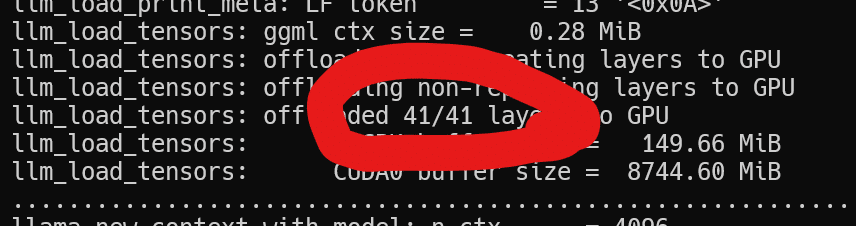
ELYZA-japanese-Llama-2-13b-fast-instruct-q5_K_M.ggufは41レイヤーあるので、-nglを41にすれば、全てのレイヤーがGPUに乗ります。
なんとなくですが、Llama2系は7Bサイズが33、13Bサイズが41のことが多い気がします。他のアーキテクチャーの場合も、とりあえず適当なnglの数で起動しておいて、ここの数字を見て、立ち上げ直すというが良さそうです。
ちなみに、nglにレイヤー数よりも大きな数字を設定する分にはとくにエラーは出なかったので、最近はなんでも-ngl 99にしています(VRAM 24GBのゆとり)。もちろん、VRAMの小さいGPUを使っている場合も、VRAMに収まる範囲のnglの数を調整することで、最適なパフォーマンスを追求できるのかもしれません。公式ドキュメントにも「Generally results in increased performance.(一般的にはパフォーマンスが増加します)」とあります。
この記事が気に入ったらサポートをしてみませんか?