
【論文瞬読】マルチタスク言語理解ベンチマークMMLUの元論文を読んでみた

こんにちは!株式会社AI Nestです。日本語に特化したLLM(大規模言語モデ
ル)が登場していますよね。
そこでどのように日本語の性能って測っているのか気になり、調べてみたところ、JMMLUといったベンチマークがあることがわかりました。また、このベンチマークはもともとMMLUという英語のベンチマークが元になっていたため、その論文を瞬読してみました。
タイトル:Measuring Massive Multitask Language Understanding
URL:https://arxiv.org/abs/2009.03300
所属:UC Berkeley, Columbia University, UChicago, UIUC
著者:Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt
言語モデルって何?
まず、言語モデルとは何でしょうか?簡単に言うと、言語モデルとは、大量のテキストデータを学習し、言語の確率分布を捉えたAIモデルのことです。最近では、GPT-3などの大規模な言語モデルが注目を集めています。
これらのモデルは、大量のデータから言語の特徴を学習し、驚くほど自然な文章を生成したり、質問に答えたりすることができます。例えば、以下のようにGPT-3にいくつかの例を与えると、それに続く問題を解くことができます。

しかし、果たしてそれは本当の意味で「言語を理解」しているのでしょうか?
既存のベンチマークの問題点
従来、言語モデルの性能は、GLUEやSuperGLUEなどのベンチマークテストで評価されてきました。しかし、最近の研究では、これらのテストでは言語理解の重要な側面を捉えきれていないという問題が指摘されています。
実際、GPT-3の性能を見ると、常識問題(Commonsense)や言語理解問題(Linguistics)よりも、今回の研究で提案された知識理解(Knowledge)で大きく改善していることが分かります。

新たなベンチマークテストの提案
そこで登場したのが、今回紹介する研究で提案された新しいベンチマークテストです。このテストは、人文科学、社会科学、STEM、その他の57もの多様な分野の問題で構成されており、初等レベルから高度な専門レベルまでの難易度の問題を含んでいます。
研究チームは、このテストを使ってGPT-3などの最新の言語モデルの性能を評価しました。その結果、モデルは一定の成果を示したものの、分野によって性能にばらつきがあることが明らかになりました。

モデルの弱点と今後の課題
特に興味深いのは、計算を要する問題や倫理的な判断を要する問題で、モデルの性能が低かったという点です。これは、モデルが単に言葉の表面的な特徴を捉えているだけでなく、深い理解を獲得することの難しさを示唆しています。
また、モデルの確信度と実際の性能の間にギャップがあることも分かりました。つまり、モデルが自信を持って答えていても、それが必ずしも正解とは限らないのです。
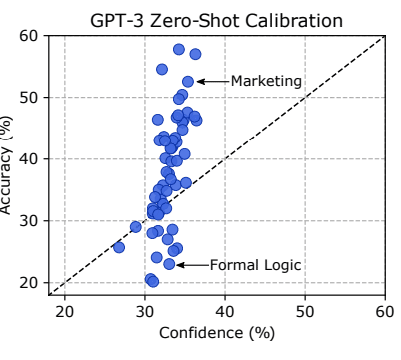
言語モデルの評価と社会的影響
言語モデルの性能評価は、単なる技術的な問題ではありません。これらのモデルが私たちの社会に大きな影響を与える可能性があるからです。特に、倫理や法律に関する問題で性能が低いことは、モデルを実社会で応用する際の大きな課題と言えるでしょう。
研究チームは、今後のモデル開発においては、性能向上のための技術的な工夫だけでなく、倫理的・社会的な影響についても慎重に議論していく必要性を指摘しています。
まとめ
以上、言語モデルの評価に関する新しい研究を紹介しました。この研究が提案する新たなベンチマークテストは、言語モデルの性能をより多角的に評価するための有力なツールになると期待されます。
同時に、この研究は、言語モデルの開発と応用において、技術的な側面だけでなく、倫理的・社会的な影響についても慎重に考えていく必要性を示唆しています。
言語モデルの研究は、まだ発展途上の段階です。今後のさらなる進展に期待したいと思います。