
700億パラメータの日本語LLM「ELYZA-japanese-Llama-2-70b」を開発し、デモを公開しました

はじめに
この度 ELYZA は、新たに開発した700億パラメータの大規模言語モデル (LLM) である「ELYZA-japanese-Llama-2-70b」のデモを公開しました。「ELYZA-japanese-Llama-2-70b」は、前回までに引き続き、英語の言語能力に優れた Meta 社の「Llama 2」シリーズに日本語能力を拡張するプロジェクトの一環で得られた成果物です。
ELYZA が公開している日本語ベンチマーク ELYZA Tasks 100 を用いたブラインド性能評価では、公開されている日本語の大規模言語モデル (以下、LLM) を大きく上回っていることに加え、OpenAI 社の「GPT-3.5 Turboシリーズ」や Anthoropic 社の「Claude 2シリーズ」をはじめとするグローバルモデルに匹敵する性能を達成しました(図1)。
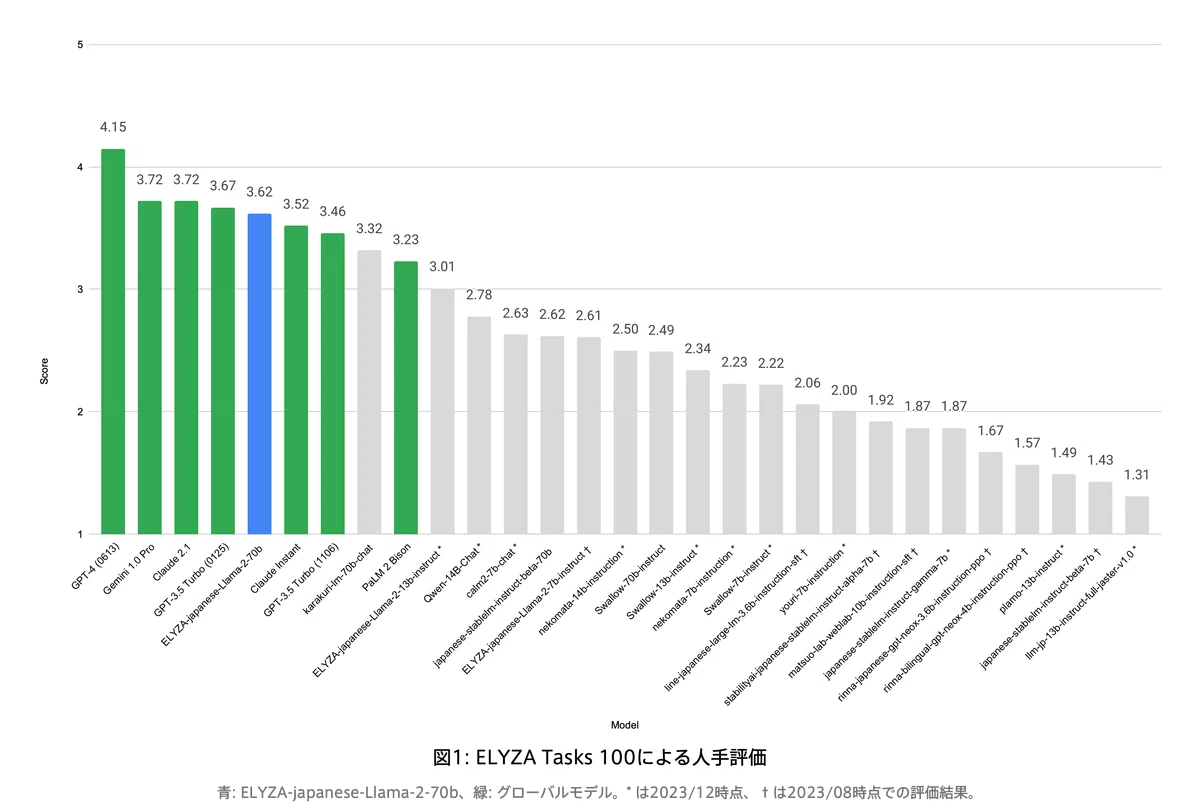
以降では、「ELYZA-japanese-Llama-2-70b」の概要と性能評価についてご紹介します。
なお、今回のモデルを含む国産 LLM「ELYZA LLM for JP」シリーズは API 提供を予定しており、2024年春以降、順次提供を開始する予定です。
デモ

今回開発した LLM「ELYZA-japanese-Llama-2-70b」の性能を皆様に体感していただくため、デモを公開しました。本デモサイトは、以下のリンクから触っていただくことができます。
● ELYZA LLM for JP|デモ版
※ アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
パラメータ数が700億ともなると、推論速度の低下が深刻な問題になります。そこで、デモを公開するにあたり、Speculative Decoding と呼ばれる高速化技術を導入しました。これにより可能な限り性能を維持しつつ、よりスムーズな応答を実現しています。
なお、本デモは Amazon EC2 Inf2 インスタンスを用いて運用されており、開発は AWS 社と密に連携して進めてまいりました。Amazon EC2 Inf2 上での推論を行う際には、こちらのサンプルコードを参考に実装しました。
学習
「ELYZA-japanese-Llama-2-70b」は Meta 社 の「Llama 2」をベースに、日本語の追加事前学習と事後学習を行なっています。これにより、「Llama 2」 の英語に対する強力な言語能力を日本語に対する言語能力に拡張させています。追加事前学習には、約100Bトークンの日本語コーパスを用いています。事後学習には、日本語での指示追従能力と一般的な知識を向上させることを目的として ELYZA が独自に構築した高品質なデータセットを用いています。また、今回学習データの一部としてichikara-instructionデータ [1] も使用しています。
なお、 「ELYZA-japanese-Llama-2-70b」を含む ELYZA のモデルの学習には「GPT-4」や「GPT-3.5 Turbo」などのモデル (※) の出力は一切含まれていません。
※ 利用規約の中で、その出力を他モデルの学習に利用することが禁止されているモデル全般を指します
性能評価
ELYZA Tasks 100 と Japanese MT-Bench を用いて評価を行いました。今回は OpenAI 社の「GPTシリーズ」や Google 社の「Gemini」等のグローバルモデルと、いくつかの代表的な日本語 LLM に対して評価を行い、性能を比較しました。
ELYZA Tasks 100
ELYZA Tasks 100 は、LLM の指示に従う能力や、ユーザーの役に立つ回答を返す能力を測ることを目的とした日本語ベンチマークです。ELYZA Tasks 100 は、各事例の評価基準とともに一般公開しているため、自由にご利用いただけます。(ELYZA Tasks 100 に関する詳細はこちら)
評価には、評価対象のテキストに紐づくモデル名を隠し、シャッフルした状態でのブラインド性能評価を採用しています。また、3人の評価者によるスコアを平均することで最終的な評価を行っています。評価対象のモデルを推論する際の プロンプトやハイパーパラメータについては、可能な限り各モデルの README と同様になるように設定しています。実際の推論コードについては、後日 ELYZA Tasks 100 のリポジトリにて公開する予定です。
以下は、ELYZA Tasks 100 を用いた人手評価の結果です。図 2 はグローバルモデルに絞ったものです。
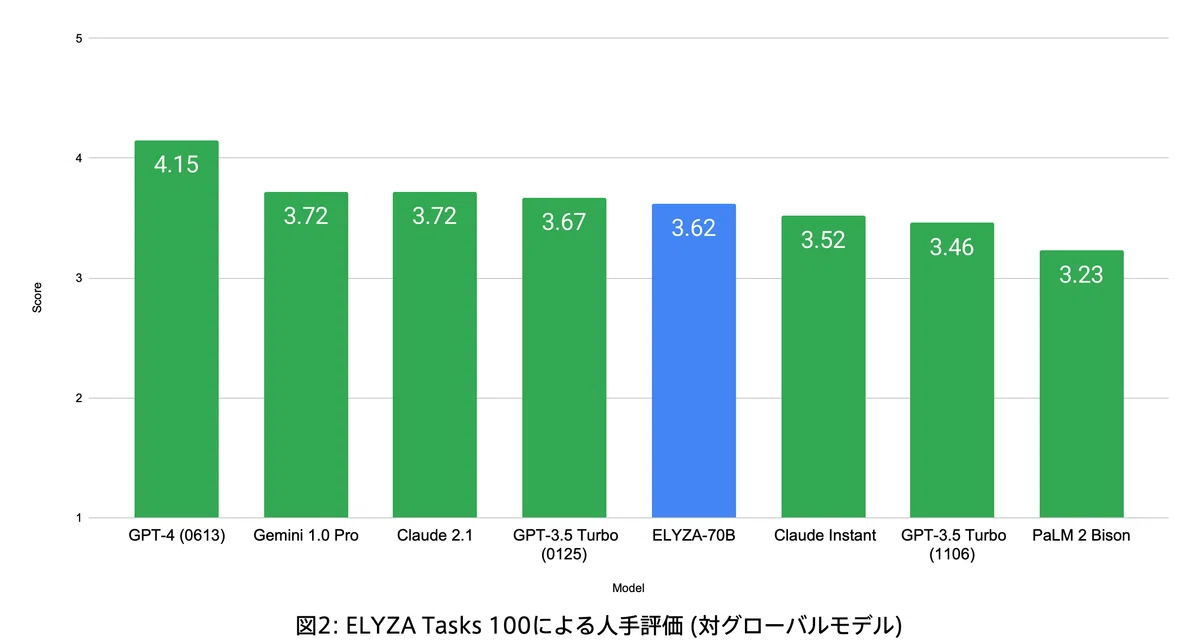
ELYZAが今回新たに開発した「ELYZA-japanese-Llama-2-70b」は「Claude Instant」や「GPT-3.5 Turbo (1106)」を上回り、その他のグローバルモデルとも遜色ないスコアを獲得しました。
国内モデルに絞った場合、前述の図1の通り、「ELYZA-japanese-Llama-2-70b」は1位の性能を誇っています。また、我々のモデルと同じく「Llama 2 70B」をベースとする他の日本語 LLM よりも優れた性能を発揮していることから、ELYZA 独自の事後学習による効果が確認できます。
Japanese MT-Bench
Japanese MT-Bench は Stability AI 社が提供しているベンチマークで、英語の MT-Bench を日本語訳して作られています。MT-Bench は LLM の対話性能を測るためのベンチマークで、8つのカテゴリに分かれた 80件の対話から応答の適切さを評価します。
評価の際は Japanese MT-Bench のリポジトリの最新のコミットのコードベースを使用し、README 通りに実施しました。(※ 評価実施に当たり加えた変更の詳細は、記事末尾に記載しています。)
以下に、日本語独自の性能比較に適した設定である、日本語非依存な math と coding カテゴリを除いた結果を示します。
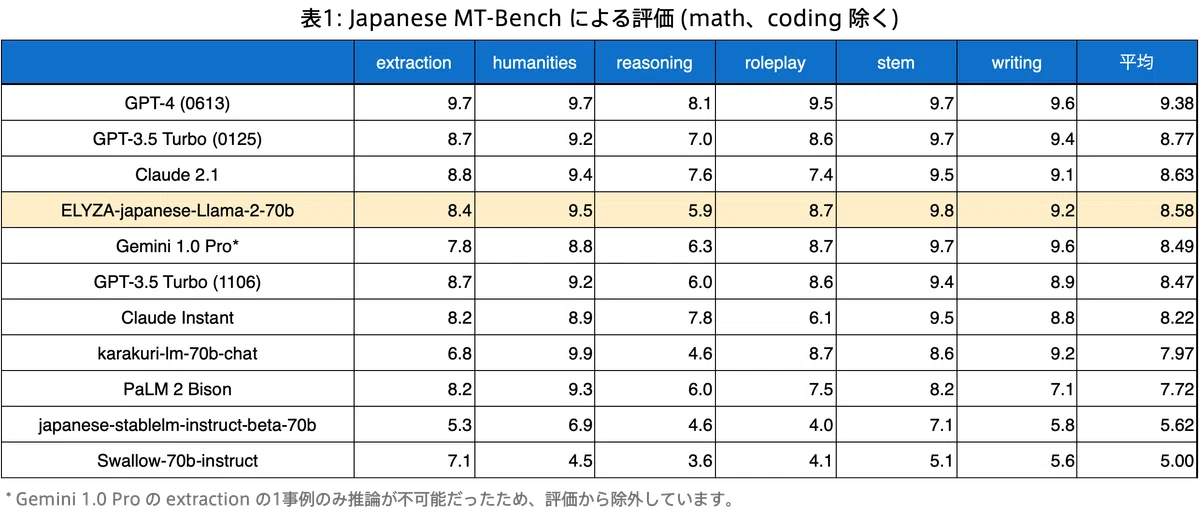
「ELYZA-japanese-Llama-2-70b」は「Gemini 1.0 Pro」や「GPT-3.5 Turbo (1106)」を総合スコア (平均) で上回るなど、ELYZA Tasks 100 と同様に Japanese MT-Bench でもグローバルモデルらと遜色ない性能であることが確認できました。また、 humanities, stem, writing カテゴリでは、総合スコア首位の「GPT-4 (0613)」とも同等のスコアを達成しています。
以下に、math と coding カテゴリも対象とした評価結果を示します。
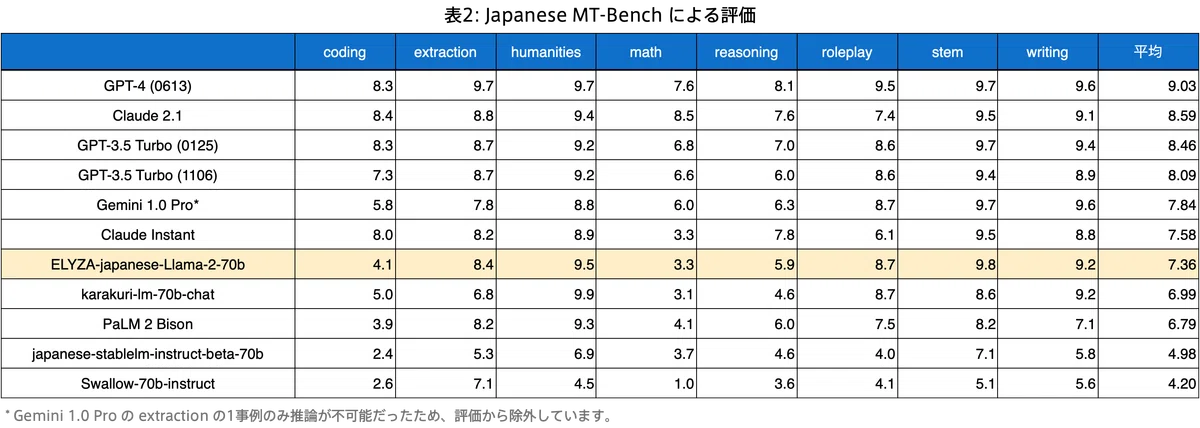
表から、ELYZAがこの度新たに開発した「ELYZA-japanese-Llama-2-70b」は依然として日本語 LLM では最高の性能を達成しているものの、日本語非依存な math と coding に関する能力に関しては順位の入れ替わるグローバルモデルも存在することから、今後改善の余地があることが分かります。
付記および今後の展望
「ELYZA-japanese-Llama-2-70b」の学習は、AI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI) の第2回 大規模言語モデル構築支援プログラムを利用して行いました。
ELYZAは「ELYZA-japanese-Llama-2-7b」シリーズから継続して「Llama 2」の日本語化に取り組み、今回の「ELYZA-japanese-Llama-2-70b」ではグローバルモデルに匹敵する性能を達成することができました。ELYZA では今後も日本語 LLM の研究開発を進め、より高性能な日本語 LLM の実現に向けて継続して投資をしてまいります。
また、今回のモデルを含む国産 LLM「ELYZA LLM for JP」シリーズは、研究開発だけに留まらず、API 提供に向けた開発も進めております。今春以降、順次提供を開始する予定です。
最後に

ELYZA(イライザ)は「未踏の領域で、あたりまえを創る」という理念のもと、この生成AI・LLM 時代のリーディングカンパニーになるべく日々奮闘しています。 国産化モデルの研究開発、これらのモデルを活用したプロダクト開発など、取り組みたいことは山積みですが、メンバーがまだまだ足りていません。
私たちの取り組みに少しでも興味を持ってくださった方がいれば、ぜひ気軽にお話しさせてください。一緒に先端技術で新しい体験をつくっていきましょう!!
● LLM 開発に興味がある AI エンジニアの方へ
ELYZA Lab メンバーとNLP/LLMの研究開発についてお話ししませんか?
https://chillout.elyza.ai/
● SWエンジニア、AIコンサルタントなど全方位で仲間を募集しています。
ELYZAの募集職種一覧はこちらを御覧ください
https://open.talentio.com/r/1/c/elyza/homes/2507
参考文献
[1] 関根聡, 安藤まや, 後藤美知子, 鈴木久美, 河原大輔, 井之上直也, 乾健太郎. ichikara-instruction: LLMのための日本語インストラクションデータの構築. 言語処理学会第30回年次大会(2024)
※ 文中に登場した Japanese MT-Bench による評価を行う際に加えた変更点を、以下に列挙しています。
・ 入力については coding, math カテゴリも含む question_full.jsonl を用いました。その際に question_id: 50 の事例に parse 不能なダブルクオーテーションが含まれていたため、それのみ修正しています。
・ OpenAI ライブラリについては最新のものだと動作しなかったため、 `openai==0.28` のバージョンを用いました。また実験環境の都合でこちらにて `use_azure=False` を指定しています。
・ judge_ja_prompts.jsonl にマルチターン用の評価プロンプトが存在しなかったため、シングルターンのみの評価としています。
・ 各モデルの出力トークン長について、デフォルトの値 (ローカルモデルだと512、APIベースのモデルだと1,024) だと足りない様子が見受けられたため、一律で 1,200 に設定しました。なお `chat-bison@001` のみ 1,024 までしか設定できなかったためそのようにしています。
・ temperature について、元コードでカテゴリごとに設定されていたため、これをそのまま使っています。
・ top-p について、「Swallow-70b-instruct-hf」と「japanese-stablelm-instruct-beta-70b」のみ README にて 0.95 と設定されていたため、それらのみデフォルト値 (0.9) から変更しています。
・prompt の形式について、極力それぞれのモデルの README と同様になるように設定しています。