

#機械学習



Metaのセグメンテーションモデル「SAM2」の論文を読む
この記事の概要Meta AIから発表されたSAM2の論文を解説しています。
SAM2とは動画に対するセグメンテーションモデルです。あるフレームでセグメントしたい物体を選択するとその物体を時間方向にセグメントしてくれます。
SAM2は自身も含むモデルでアノテーションを補助し、さらにモデルを改善していく仕組みで、動画セグメンテーション用の大規模なデーセットを構築しています。
結果、画像と動画の両







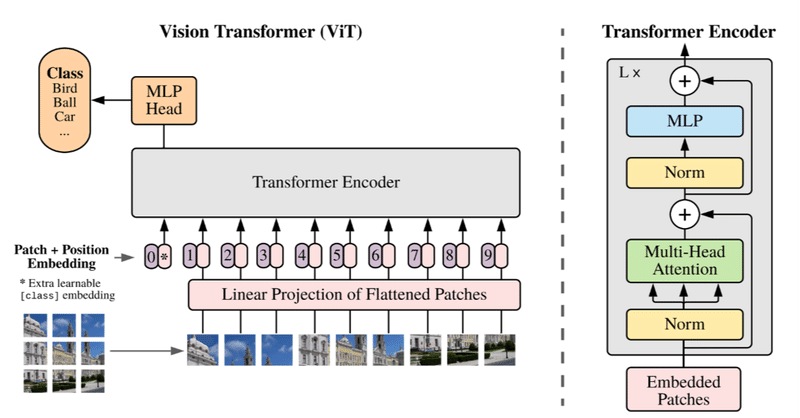
Computer Vision x Trasformerの最近の動向と見解
この記事についてこの記事では、Vision Transformer[1]登場以降のTransformer x Computer Visionの研究で、興味深い研究や洞察について述べていきます。この記事のテーマは以下の4つです。
• Transformerの急速な拡大と、その理由
• TransformerとCNNの視野や挙動の違い
• TransformerにSelf-Attentionは必須




labelme2yoloの使い方~Segmentation編~
はじめにlabelme2yoloというpythonライブラリを発見
かなり新しいライブラリなので日本語記事が皆無
なら、私が書きましょう☆彡
動作環境Python:3.11.5
ultralytics:8.0.145
labelme:5.3.1
labelme2yolo:0.1.3 ★今回の主役!!
labelme2yoloの使い方labelme2yoloとは?
labelmeで作



次世代のコンピュータビジョンツール: RoboFlow Supervisionの魅力を徹底解説!
今回は、再利用可能なコンピュータビジョンツール「RoboFlow Supervision」をご紹介します。このツールは、データセットのロードから画像やビデオ上の検出の描画、そして特定のゾーン内の検出数のカウントまで、多岐にわたるコンピュータビジョンタスクをサポートしています。
RoboFlow Supervisionの主な特徴:シンプルなインストール: Python 3.8以上の環境で、数ステッ


第4号「コンピュータビジョンの深層学習ベース化」
Control Color: Multimodal Diffusion-based Interactive Image Colorization
画像に色のヒントを与えて着色するための拡散モデルです。
どんなもの?: 高度に制御可能な対話式画像着色手法であり、無条件および条件付き画像着色を支援し、色溢れや不正確な着色を解決します。
先行研究と比べてどこがすごい?: 複数の条件(テキストプロ

特別号「構成画像検索(Composed Image Retrieval)」
はじめに: 構成画像検索とは構成画像検索とは、画像とクエリ(テキスト)を使って画像を検索することです。例えば、魚の画像と「折り紙」というワードで画像を検索すれば入力した魚に近い折り紙の画像を検索できます。
従来のよくある全部の画像の埋め込みベクトルを事前に計算しコサイン類似度で画像検索するというやり方だと、入力画像との類似画像しか検索できないという問題やクエリを追加して柔軟に検索することができな


end-to-endの文書画像認識モデルDonutをファインチューニングする
DonutはOCRを使わないend-to-endの文書理解モデルです。
Vision Encoder Decoder Modelになっており、OCRエンジンに依存せずに視覚的な文書分類や情報抽出を高い精度で行うことができます。
Donutは日本語を含む4言語で学習されたモデルnaver-clova-ix/donut-baseが公開されており、日本語で何かしたいときにファインチューニングして使えそ