
Metaのセグメンテーションモデル「SAM2」の論文を読む

この記事の概要
Meta AIから発表されたSAM2の論文を解説しています。
SAM2とは動画に対するセグメンテーションモデルです。あるフレームでセグメントしたい物体を選択するとその物体を時間方向にセグメントしてくれます。
SAM2は自身も含むモデルでアノテーションを補助し、さらにモデルを改善していく仕組みで、動画セグメンテーション用の大規模なデーセットを構築しています。
結果、画像と動画の両方において高いセグメンテーション精度で、全てのベンチマークでSOTAを達成しました。
これまでの任意セグメンテーションの取り組み
今回の新しいモデルが「SAM2」と番号がついているように、その前のモデル「SAM(Segment Anything Model)」が存在します。SAMは画像の任意の物体に対するセグメンテーションモデルです。
これはセグメントしたい物体を、ポイント・バウンディングボックスで指定して、その物体をセグメントできるモデルでした。
これまでのセグメテーションは対象に対してクラス分類を行っていました。一方、SAMはクラス分類なしで、任意の物体に対するセグメンテーションを目標に研究が行われています。

動画における課題
今回はSAMのような任意の物体に対するセグメンテーションを動画で行うことを目標にしています。ただ、画像のセグメンテーションには無い課題が存在します。
動き、変形、オクルージョン、照明の変化などの要因による外観の大きな変化
カメラの動き、ぼやけ、低解像度による低品質画像
多数のフレームに対する効率的な処理
動画セグメンテーションデータセットについて
動画セグメンテーションデータセットは既存のものもあるものの、基本的にクラス分類のためのデータセットでマスクの細分化も粗いです。動画に対する任意セグメンテーションを行うには不足していました。
今研究では、SAM2モデルと共に「SA-V」といった大規模なセグメンテーションデータセットを作成・公開しています。「SA-V」作成にはいくつか工夫点があるので後ほど解説します。
Modelについて
SAM2ではセグメンテーションのプロンプトとして、点・バウンディングボックス・セグメンテーションマスクが使えます。あるフレームにおいてプロンプトを指定すると時間方をセグメントしてくれます。
ちなみに未来だけではなくて、過去のセグメンテーションも行うこともできます。(プロンプト:ここではセグメンテーションする対象への印という意味で、テキストによる指定ではないです。)
推論のイメージは、プロンプトや過去の推論の情報を特徴量としてメモリstoreに保存して、それらを次の推論のリファレンスとして使って逐次的にセグメンテーションを行います。

簡単にモデルの構成を書くとこのようになっています。
image encoder
各フレームの画像をencodeして埋め込み特長量を取得します。
memory attention
現在のフレームの埋め込み特長量を、新しいプロンプトや過去のフレームの特徴量と予測に基づいてattentionで調整します。
過去の特徴量はmemory bankから取得します。
prompt encoder
SAMと同じものになっていてプロンプト(点・box・マスク)からオブジェクトの範囲を推測します。
mask decoder
プロンプトの更新とフレームの埋め込みを出力する2タスクを行うTransformer
曖昧なプロンプトに対しては複数のマスクを予測します。ただ、毎フレーム複数のマスクを推論した場合、曖昧さが増していく可能性があります。そのため、現在のフレームで最もIoUが高い(他のマスクと重なっている部分が最も多い)マスクを残すことにしている。(ただ、人間がSAM2を使うときは曖昧さを人間がフォローして解消することは可能です。)
元々のSAMのアーキテクチャに加えて、動画に対する推論では奥行きなどの影響で対象が常に画像上に存在するとは限らないため、現在対象が画像に見えているかを判別するhead層が付けられています。
memory encoder
mask ecoderの出力マスクをダウンサンプリング・image encoderからの特徴量と合計してメモリとなる特徴量を算出します。
memory bank
空間メモリとオブジェクトポインターのメモリを持っています。
空間メモリ
セグメント対象の過去予測のmemory encoderの出力とプロンプトをそれぞれキューに保存します
オブジェクトポインターのリスト
オブジェクトポインターはセグメンテーションされたオブジェクトに関する高レベルのセマンティック情報を持つ軽量ベクトルです。
mask decoderから得られ、オブジェクトのより抽象的な表現が可能となっている。
5. データ
SAM2では動画セグメンテーションのデータセット「SA-V」を研究内で作成しています。作成方法にも工夫があるので詳細をします。
「SA-V」のデータではマスクにセマンティックな制約を課すことはせず、オブジェクト全体とパーツ (たとえば、「人」と「その人の帽子やシャツなど」) の両方の粒度で焦点を当てています。
アノテーションに関しては、大規模で多様な動画セグメント化データセットを収集するためのデータエンジンを構築しています。データエンジンは3つのフェーズを経て、フェーズは支援に使用されるモデルに基づいて分類されてます。
フェーズ1: フレーム毎のSAM
最初のフェーズでは、画像ベースのインタラクティブ SAM を使用して、アノテータを支援します。アノテータは、SAM、および「ブラシ」や「消しゴム」などのピクセル単位の正確な手動編集ツールを使用して、6フレーム毎に動画の対象オブジェクトにマスクを作成します。
全フレームのアノテーションを最初から行う必要があるため、時間がある程必要で、実験ではフレームあたり平均37.8秒かかりました。
この作業で1.4Kの動画で16Kのマスクレットを収集しました。また、このフェーズのアノテーションデータからSA-V valセットとテストセットを作成します。フェーズ1のアノテーションを評価データセットとして使用することで、最終的な評価における SAM 2 の潜在的なバイアスを軽減しています。
フェーズ2: SAM + SAM 2 Mask
2番目のフェーズでは、SAM 2 をアノテーション支援に追加しました。このフェーズのSAM 2 はセグメントマスクのみをプロンプトとして受け入れます。(このセグメントマスクのみを受け入れるバージョンのSAM2をSAM2 Maskと呼びます。)
アノテータは、フェーズ1と同じように SAM と他のツールを使用して最初のフレームで空間マスクを生成し、次に SAM2 Maskを使用してプロンプトを他のフレームに時間的に伝播して、完全な時系列マスクを取得します。
アノテータはSAM2 Maskの予測を修正する作業を行います。
フェーズ2では、アノテーションとSAM2の再学習のループを2回行いました。フェーズ2では、63.5Kのマスクレットを収集しています。
アノテーション時間はフェーズ1から約5.1倍高速化され、フレームあたり7.4秒になっています。
アノテーション時間は改善されましたが、このフェーズでは、過去のセグメンテーションに関するメモリはないので、中間フレームのマスクを最初からつける必要があります。
フェーズ3: SAM 2
最後のフェーズでは、点やマスクなどのプロンプトを受け入れる完全な機能を備えた SAM 2 を使用します。
SAM 2 は、時間方向全体でオブジェクトのメモリを活用して、マスク予測を生成します。よって、アノテータは中間フレームで予測されたマスクを編集するために、SAM 2 に時折改良クリックを提供するだけで修正させることができます。フェーズ3では、収集されたアノテーションデータで SAM 2 を5回再学習および更新しました。SAM 2 をループに追加すると、フェーズ1から約5.1倍高速化されています(フレームあたり4.5秒)。
フェーズ3では、197.0Kのマスクレットを収集しました。
他にもアノテーションの品質と多様性を維持するために以下のような取り組みがあります。
品質検証
一部のアノテータたちは、アノテーションが全フレーム正しく一貫して追跡できているかを「満足・不満足」で検証するタスクを行なっています。不満足なマスクは、改良のためにアノテーションパイプラインに送り返されます。適切に定義されていないオブジェクトを追跡するマスクは完全に拒否されました。(おそらくあまりに悪質なアノテーションはパイプラインにも送らず捨てている。)
自動マスク生成
人間は、車や動物など顕著なオブジェクトに焦点を当てる傾向があるため、アノテーションマスクをSAM2による自動生成マスクで水増しをしています。
これは、アノテーションのカバレッジを増やすのと同時に、モデルの失敗ケースを特定するという2つの目的を果たします。
自動生成マスクに対しても品質検証を行なっていて、不満足であれば失敗ケースとして、正しくアノテーションされて学習データセットに追加されます。
このアプローチでさまざまなサイズ・背景などの位置に依らないセグメンテーションが可能となります。

人間によるマスクは対象が限られている
一方で、自動マスクを使うとさまざまな物にマスクを付けることができる
結果
画像タスク
SAMとSAM2 でSegment Anythingのタスクを37のデータセットで比較。
全てのデータセットでSAM2 our mix が最も結果が良くなりSOTAを達成した。(our mixはSAMの学習データセット + 今回の動画アノテーションデータで学習が行われたモデル)
速度も6倍ほど高速化できている。

FPSはA100での推論速度
動画タスク
これまでの動画セグメンテーションの研究はセグメント対象に、ラベルをつけてラベルを含めたセグメント精度を評価していたため、SAM2のような任意のセグメンテーションはそのままでは比較ができなかった。
そのため今回は既存のモデルと比較するため、SAM2の最初のフレームのプロンプトとしてセグメント対象にマスクをつけた上でのセグメンテーション精度を計算し比較している。
結果として、全てのベンチマークでSAM2はSOTAを達成することができた。
またA100で30~44FPSで推論することができ、リアルタイム推論も可能であることも示された。
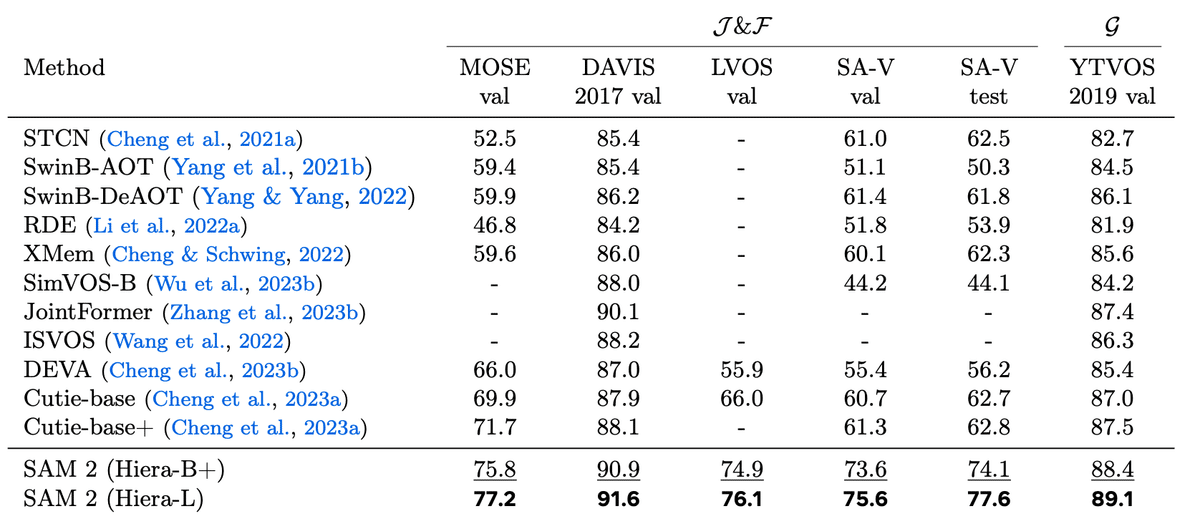
SAM2が全てのベンチマークを塗り替えてSOTAを達成している
課題
動画におけるオブジェクト追跡の困難さ
カメラショットの切り替わりでオブジェクトのセグメンテーションに失敗。
混雑したシーン、長時間のオクルージョン後、長時間の動画では、オブジェクトを見失ったり、混同したりすることがある。
細部・類似した物体や高速移動する物体が追跡困難
データエンジンの人的依存(将来的には人間がアノテーションの補正を行わずにデータセットを更新できる仕組みを作りたいらしい)
ただ、ユーザーがSAM2を使用する際はモデルが推論に失敗した場合、ユーザーが修正して新しいプロンプトを渡してあげることで結果を補正しながらセグメンテーションを行なっていくことができます。
まとめ
この記事ではSAM2の論文の一部を簡単にまとめました。SAM2自体もOpenSourceで公開されていて、今後動画編集や他の目的でのアノテーション支援などの場所で活用できそうだなと思いました。
また、データが不足しているところから大規模なデータセットを効率よく作成する部分についても面白いと思いました。
この記事が気に入ったらサポートをしてみませんか?