記事一覧



ローカルマルチモーダルを簡単に使えるAPIを公開。LLaVA-Next(旧1.6)でAPIサーバを構築
始めにOpenAIやGoogleのAIサービスはマルチモーダル対応が当たり前のようにできます。ローカルLLMでもいくつかマルチモーダルに対応したモデルがありました。めぐチャンネルでも過去にMinigpt-4によるAPIサーバの構築を試しましたが、実用的に使えるかと言うと若干の疑問があったのも事実です。今回は1月末に公開されたLLaVA-NEXT(旧-1.6)で実用に耐えるローカルマルチモーダルL

Diffusers0.27.0とAnimaginXL-3.1を試す
先週、Diffusersが0.27.0にバージョンアップしました。さらに好評のAnimaginモデルに3.1が出てきましたので試しました。0.27.0で追加された機能がありますが、まずは旧バージョンとの比較を行いました。AnimaginXLについても2.0との比較を行っています。なお、動作確認は以下の記事のDiffusersPipelineManagerとAPIサーバで行いました。
変更箇所Di

1枚のアニメ顔を感情豊かに動かすための手法---ポーズデータを抽象化して自在に動かす
詳細は別途になります。何ができるかとコードの公開です。
Talking-Head-AnimeFace-3による1枚絵からのリアルタイムな動画生成の最終版です。ポーズデータという扱いづらい配列ではなく、抽象化した指示で容易にキャラクタを動かすためのラッパーです。一つ前記事の通りにサーバを動かし、クライアント側をmultiproccesinngで並列処理することで、データ処理の各プロセスをサブプロセ

1枚絵からリアルタイムにアニメキャラを動かすーTalking-Head-AnimeFace3ー アップスケールで任意エリア拡大
はじめに前回はリアルタイムアップスケールの記事でした。前回の記事と、以前に書いた一枚絵からキャラを動かすTalkingHeadAnimefaceを組み合わて、キャラの任意の部分、例えば「胸から上」、「上半身」あるいは、「首から上」のようなエリス指定をしながらリアルタイムに拡大した動きを得るとができます。TalkingHeadAnimefaceとreal-ESRGANは生成速度に差があり、またap
- #python
- #アニメ
- #Vtuber
- #生成AI
- #1
- #アバター
- #2
- #12
- #10
- #11
- #3
- #リクエスト
- #Anime
- #4
- #5
- #6
- #サンプル
- #7
- #8
- #9
- #0
- #mode
- #サーバ
- #try
- #print
- #クロップ
- #アニメキャラ
- #AiTuber
- #FastAPI
- #アップスケール
- #pose
- #result
- #generation
- #_
- #except
- #RealESRGAN
- #TalkingHead
- #pose_dic_orgの設定
- #pose_dic
- #サブプロセスの終了
- #ここで一旦止まり
- #アップスケールとtkhプロセスの開始
- #便宜上設定している
- #Dict形式
- #画像切り出し
- #TakingHead
- #マルチプロセッシング
- #リクエスト送信
- #アップスケールマルチプロセッシングのqueue
- #形式はimg_mode指定の通り
- #packed_pose
- #Dict形式ポースデータから画像を生成し
- #tkhプロセス停止関数
- #アップスケールプロセス停止関数
- #アップスケールプロセス実行関数
- #Dict形式の初期値を得る
- #パック形式
- #PIL形式の画像を動画として表示
- #tkhプロセスの開始
- #process作成
- #process開始
- #tkhプロセス実行関数
- #Thiの酒器化
- #アップスケールプロセスの開始
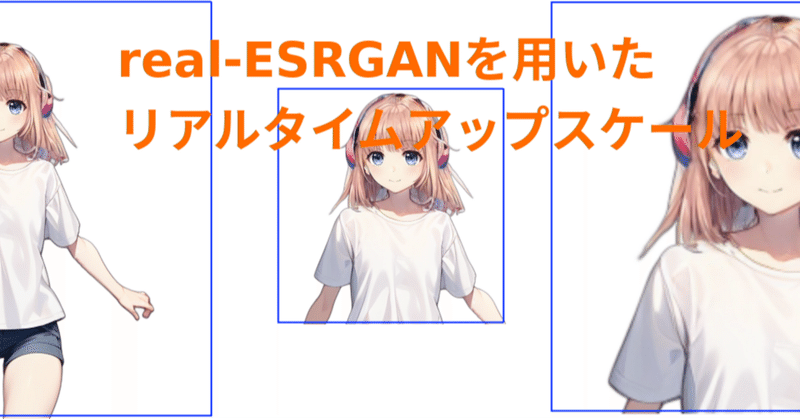
リアルタイム・アップスケール改良版
セミリアルタイムアップスケールの記事を書きましたが、再度利用場面やAPIS仕様の見直しをしました。条件によりますがRTX4070クラスでも20fpsをクリアできるようになりました。RTX4090だと40fpsも可能です。
どんな時に必要か再検討動画のアップスケールを行うことが前提ですが、生成AIで生成した動画を拡大する用途です。例えば512x512を2倍に拡大すると1024X1024になるわけ

一枚絵があれば動く。Talking-Head-Anime-3のインストールして、ポーズデータでスムーズに動かす サーバ編
引き続き、後半のサーバ編です。前回の記事で作成したTalkingHeadAnimefaceクラスを利用してFastAPIによるサーバを構築します。サーバ化の最大のメリットは完全な並列処理が可能になる点です。同一PC内でも別途サーバを準備してもクライアント側は同じなので、システム構成が柔軟にできます。ただし、通信のオーバーヘッドが生じるので生成時間は多少長くなることは避けれれません。
環境は前回

一枚絵があれば動く。Talking-Head-Anime-3のインストールして、ポーズデータでスムーズに動かすーAPI編
はじめにこの記事ではTalking Head Anime 3をプログラムから制御してキャラクタを自由に動かすための仕組みの実装と使い方について解説します。2回に分けて前編:APIクラス化(この記事)、後編:今回定義したクラスを用いてサーバ化につて2回に分けて記事にします。
Talking Head Anime 3について
Talking Head(?) Anime from A Single
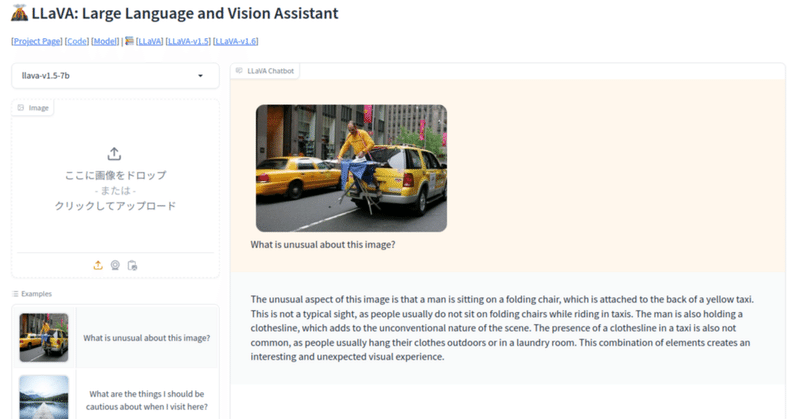
LLaVA-1.6を使ってみた。日本語もOKなマルチモーダルLLM
久しぶりにLLMの記事です。OSのお引越し作業のついでに商用可能になったというLLaVAを動かそうとしたら、1.6にバージョンアップされていて、以前に動かしたときよりも随分変わっていました。
環境リポジトリ通りにインストールします。
git clone https://github.com/haotian-liu/LLaVA.gitcd LLaVAconda create -n llava p

Diffusersで画像サーバ構築 V1.1
Diffusersが0.26.0にバージョンアップし、注目のIP-Adapetrにマルチアダプタ対応が導入されたので、自作DiffusersPipleineManagerクラスとFastAPIによるAPIサーバもv1.1 へアップデートしました。同じモデル、同じパラメータで生成される画風が0.26.0では変わってしまってしまいましたが、マルチIP-Adapetrが使えるので、環境を使い分けても良さ
もっとみる- #AI
- #AI画像生成
- #SDXL
- #mode
- #IP
- #control
- #from
- #diffusers
- #inpaint
- #openpose
- #StabeleDiffusion
- #Canny
- #pipe_openpose
- #pipe_inpaint
- #pipe_depth
- #pipe_canny
- #pipe_t2i_adapter
- #pipe_t2i
- #pipe_i2i
- #mul_ip
- #pipe_t2i_mip
- #pipe_i2i_mip
- #pipe_t2i_sip
- #pipe_i2i_sip
- #style_images
- #lcm_lora_en
- #face_image
- #freeu_list

DiffusersPipelineManagerにIP-Adapter機能を追加
DiffuserPipelineManager設定できるpipelinet2i
i2i
inpaint
ここらはVRAM消費大きい
t2i_Multi-IP-Adapter
t2i_IP-Adapter
i2i_Multi-IP-Adapter
i2i_IP-Adapter
inpaint_IP-Adapter
Control-NET Canny
Control-NET Op
- #prompt
- #style
- #model
- #image
- #LoRa
- #IP
- #self
- #LCM
- #strength
- #VAE
- #generate
- #当面
- #Multi
- #pipe
- #t2i
- #画像の生成
- #UNETの有効無効設定
- #DiffusersPipelineManagerの定義と初期化
- #generate_t2a_adapter
- #generate_controlnet
- #Depthイメージ作成クラス
- #openposeイメージ作成クラス
- #cannyイメージ作成クラス
- #Depthで使用
- #modelとpipeはデフォルトを使う
- #デフォルトpipeのロード
- #loRAのモデルとアダプタ名及びウエイトリスト作成
- #pipe名指定のエラー
- #canny_openpose
- #HuggingFaceからダウンロードする場合
- #pipelineの準備
- #mask_image
- #embe
- #compel_proc
- #lcm_lora
- #指定できるpipe名
- #pipeloneの再利用の時に参照する生成済みpipeline名指定
- #ロードするSDXLモデル名
- #VAE有効無効設定
- #VAE有効時のVAEへのパス
- #UNETの準備
- #VAEの準備
- #ControlNet名を指定してpipeを設定するとき
- #ddism
- #prompt_embeds
- #pooled_prompt_embeds
- #num_images_per_prompt
- #guess_mode
- #crops_coords_top_left
- #controlnet_conditioning_scale

シンプルAPIで構築したStable-Diffusion SDXL専用の画像生成サーバーを公開(変数を試す)-2
前回はサーバプログラムとそのテストプログラムの説明と公開をしました。今回はシリーズ2回めで、各変数の影響について見ていきます。全て
Stable-Diffusion SDXL専用画像生成サーバーを用いています。
プロンプト
説明するまでもないと思います。SDXLモデルの場合は従来のような単語を並べる方法の他に、文章を入力することも可能です。
"masterpiece, best qualit

シンプルAPIで構築したStable-Diffusion SDXL専用の画像生成サーバーを公開(全コード公開)-1
前回の記事で作成したDiffusersPipelieManagerを使い、FastAPIでラップして画像生成サーバを構築しました。DiffusersPipelineManagerはSDXLモデル専用のDiffusersクラスで構成されています。SDXL特有の処理や、画像関係の事前準備などのユーティリティクラスも提供しており、FastAPIと組み合わせることで、クライアント側で煩雑なDiffuser
もっとみる
Diffusersの複数機能も簡単に扱えるDiffusersPipelineManagerを公開 (コードの解説と使い方)
この記事についてDiffusersはStable-Diffusionを始め、音声や、3Dにも対応する、拡散モデルのためのライブラリ群です。この記事ではStable-Diffusionによる画像生成をプログラミングで操作するためにDiffusersの機能を利用し、多岐にわたるDiffusersの持つ機能を纏めてアプリ開発で便利に利用できるような機能とするためにPythonによるクラス化を行いました
- #prompt
- #style
- #model
- #image
- #LoRa
- #test
- #self
- #LCM
- #VAE
- #openpose
- #height
- #generate
- #Multi
- #pipe
- #Canny
- #Generator
- #t2i
- #画像の生成
- #pipe_openpose
- #pipeloneの再利用の時に参照する生成済みpipeline名指定
- #ロードするSDXLモデル名
- #VAE有効無効設定
- #VAE有効時のVAEへのパス
- #UNETの有効無効設定
- #UNETの準備
- #VAEの準備
- #pipelineの準備
- #ControlNet名を指定してpipeを設定するとき
- #HuggingFaceからダウンロードする場合
- #canny_openpose
- #pipe名指定のエラー
- #loRAのモデルとアダプタ名及びウエイトリスト作成
- #modelとpipeはデフォルトを使う
- #pipe_t2i_adapter
- #Depthで使用
- #モデル例
- #デフォルトpipeのロード
- #embe
- #DiffusersPipelineManagerの定義と初期化
- #generate_t2a_adapter
- #compel_proc
- #pipe_i2i
- #generate_controlnet
- #lcm_lora
- #Depthイメージ作成クラス
- #pipe_t2i
- #pipe_inpaint
- #openposeイメージ作成クラス
- #cannyイメージ作成クラス
- #指定できるpipe名
- #Diffusesのサンプルを使う
- #pipe_canny_openpose
- #実行するテストをTrueに設定
- #original_image
- #LCMを有効にしないSDXLモデル用のパイプ定義
- #ContorolNET用pipeの新規定義
- #パイプ作成
- #x_image_list
- #LoRAのロード
- #パイプラインの準備
- #org_model
- #org_vae

StreamDiffusionを外部プログラムから利用する(3)TCP/IPによる画像生成サーバの実装
連載3回目はTCP/IP通信を利用してイメージデータの受け渡しをするサンプルです。TCP/IPよりも上層のプロトコルが無いので高速通信が期待できます。次回4回目はこれまでに集めた様々な条件における生成パフォーマンスをまとめて最終とします。 力尽き、今回で最後とします。
どのようにTCP/IPを使うかPythonのSOCKET通信機能を利用してTCP/IPパケット上にデータを載せてサーバ↔クライン

StreamDiffusionを外部プログラムから利用する(2)FastAPIによるAPIの実装
StreamDiffusionを外部プログラムから利用する(2)FastAPIによるAPIの実装第1回に続き、サーバ編です。FastAPIによるサーバ実装はLLMでも手がけていて、難しくはありません。さらにDiffuserによる画像生成も基本的には画像フォーマットをpillow形式で行えば通信時のバイトデータの変換もpillowのみなので単純化出来ます。一方でStreamDiffusionでは画像
もっとみる