
一枚絵があれば動く。Talking-Head-Anime-3のインストールして、ポーズデータでスムーズに動かすーAPI編

はじめに
この記事ではTalking Head Anime 3をプログラムから制御してキャラクタを自由に動かすための仕組みの実装と使い方について解説します。2回に分けて前編:APIクラス化(この記事)、後編:今回定義したクラスを用いてサーバ化につて2回に分けて記事にします。
Talking Head Anime 3について
Talking Head(?) Anime from A Single Image はアニメの画像1枚があれば、胸から上を自由に動かすことができるAIです。発表されてから2年が経過し、最近のAIの進歩を考えるとかなり古い技術にも思えます。一方で1枚の絵から完全リアルタイムでキャラクタを高精度に動かすことは最新のAI技術を持ってしても、難しい状況に代わりはありません。筆者も様々な工夫をしましたが、Talking Head Anime 3を超えるリアルタイム生成はできていません。キャラを動かす他の方法は2Dや3Dのモデルを作成して、MMDやUnity,VRchatなどで動かすことです。ポピュラーな方法ですが、モデル作成に費用がかかる、あるいは自分で作るかですが、髪型や服装を手軽にいくらでも交換できないですし、複数のキャラクタを動かすためには動かしたいキャラクタ毎にモデルを準備しなくてはなりません。その点、Talking Head Anime 3は1枚の絵があれば自由に動かすことができるので、いくらでもキャラクタを扱うことができます。
また、わわいろさんが独自に機能拡張をして更に高精度な動きを実現されています。
夜宣伝
— あわいろ (@pale_color) January 30, 2024
1枚の立ち絵イラスト用意があればモデリングやパーツ分け不要ですぐにVTuberになったりできます!
Talking Head Anime 3 SWhttps://t.co/hKO1VfCDmz
Talking Head Anime 3 SW Plus (NDI, Spout出力対応&個人商用利用可ver.) https://t.co/7Gy2oAoIG3 https://t.co/y0amBEd2V2
Talking Head Anime 3に需要はあるのか
手軽に動かしたい、2Dや3Dの制御は大変、キャプチャして変換をするにはちょっと作業が重い、など、とにかくかんたんに動くキャラが欲しいという方々向けです。手や足は動きませんし、物理演算をするわけでもないので髪の毛は揺れませんが、上半身は十分にスムースに動いてくれるので、声をつけたりLLMと組み合わせてキャラAIを作るときの試験など、様々な用途で使えるはずです。
動かすまでの作業は簡単
もちろんAIですからそれなりの環境の準備は必要ですが、気難しいAIではありません。以下環境設定の手順です。
H/W:NVIDIAの2000シリーズ以上のGPU。大変軽いAIなので性能は問いません
事前にCUDA-Toolkitのインストールが必要です。
環境構築はAnacondaが便利ですが、VENVでも大丈夫です。
python:3.9以上です。以下はAnaconda環境でのインストール手順です。
は筆者はUbuntu20.04または22.04ですが、Windowsでも同様にできるはずです。
リポジトリのクローン
git clone https://github.com/pkhungurn/talking-head-anime-3-demo.git仮想環境作成
cd talking-head-anime-3-demo
conda create -n tkh-api python=3.11
conda activate tkh-apiモジュールのインストール
以下をインストールします。Conda環境ではない場合はScipyやnumpyのインストールも必要です。PyTorchは最新版で問題なく2.20を選択、cudaも最新で問題ないのでCUDA12.1を選び、イントールします。
pip3 install torch torchvision torchaudio
pip install SciPY
pip install opencv-python
pip install numpy
pip install pillow
pip install matplotlib
pip install python-multipart
pip install fastapi
pip install uvicornCUDA関係の確認
ここまでで、nvcc -Vで以下のメッセージが表示されれば準備OKです。最新のバージョンで動きます。
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed_Nov_22_10:17:15_PST_2023
Cuda compilation tools, release 12.3, V12.3.107
Build cuda_12.3.r12.3/compiler.33567101_0モデルのダウンロード
wget https://www.dropbox.com/s/y7b8jl4n2euv8xe/talking-head-anime-3-models.zip?dl=0data/models/ にダウンロードされたtalking-head-anime-3-models.zipをコピーして展開します。
環境のセットアップについて、Windwosの場合は以下のnpakaさんの記事が参考になります。
キャラ絵の準備
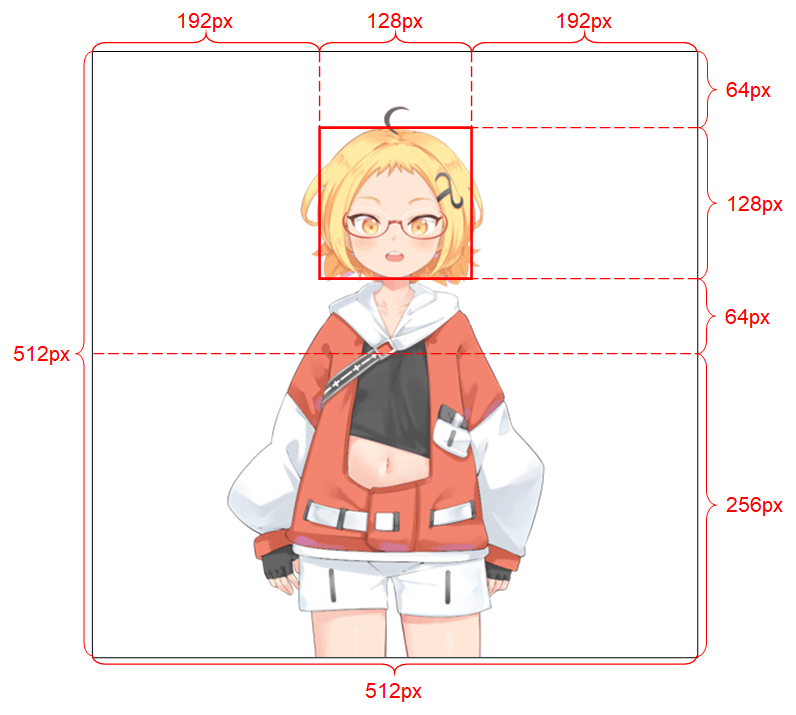
キャラクタの配置には制限があります。以下は推奨の配置です。ずれても動きますが、やや精度が低下します。背景は透過でなくてはいけません。
筆者は自動で顔エリア検出してフォームを作成するツールを準備しています。機会があれは記事にしたいと思います。Readmeには以下の記述があります。
1)解像度は 512 x 512 である必要があります。
2)アルファチャンネルが必要です。
3)人型キャラクターを 1 つだけ含める必要があります。
4)キャラクターは直立して前を向いている必要があります。
5)手は頭の下、頭から遠く離れた位置にある必要があります。
6)頭は上半分の中央に128 x 128 のボックス内におさめます
7)背景ピクセル のアルファ チャネルは 0 でなければなりません。
注)背景削除でキャラの周囲に半透明部分が残りますが問題は無いようです
ポーズデータ
リポジトリオリジナルのポーズデータ
ベタなlist形式です。以下のようになります。
current_pose3= [0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0, 0.0, 0.0, i/100, 0.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,0.0, 0.0, 0.78, 0.57, 0.63, 0.75, 0.49, 0.43,0.23, 0.65,1.0]展開して各要素の意味を調べると以下のようになっています。
#----- 展開したcurrent_poseの形式 #0 troubled_eyebrow_left=0.0,
#1 troubled_eyebrow_right=0.0,
#2 angry_eyebrow_left= 0.0,
#3 angry_eyebrow_right 0.0,
#4 lowered_eyebrow_left= 0.0,
#5 lowered_eyebrow_right 0.0,
#6 raised_eyebrow_left= 0.0,
#7 raised_eyebrow_right 0.0,
#8 happy_eyebrow_left= 0.0,
#9 happy_eyebrow_right 0.02,
#10 serious_eyebrow_left= 0.0,
#11 serious_eyebrow_right=0.0,
#12 eye_wink_left= 0.0,
#13 eye_wink_right=0.0,
#14 eye_happy_wink=0.0,
#15 eye_happy_wink=0.0,
#16 eye_suprised_left=0.0,
#17 eye_suprised_right=0.0,
#18 eye_relaxed_left=0.0,
#19 eye_relaxed_right=0.0,
#20 eye_unimpressed_left=0.0,
#21 eye_unimpressed_right=0.0,
#22 eye_raised_lower_eyelid_left=0.0,
#23 eye_raised_lower_eyelid_right=_0.0,
#24 iris_small_left=0.0,
#25 iris_small_right0.0,
#26 mouth_dropdown_aaa=0.0,
#27 mouth_dropdown_iii=0.0,
#28 mouth_dropdown_uuu=0.0,
#29 mouth_dropdown_eee=0.0,
#30 mouth_dropdown_ooo=0.0,
#31 mouth_dropdown_delta=0.0,
#32 mouth_dropdown_lowered_corner_left=0.0,
#33 mouth_dropdown_lowered_corner_right=0.0,
#34 mouth_dropdown_raised_corner_left=0.0,
#35 mouth_dropdown_raised_corner_right=0.0,
#36 mouth_dropdown_smirk=0.0,
#37 iris_rotation_x=0.0,
#38 iris_rotation_y=0.0,
#39 head_x=0.0,
#40 head_y=0.0,
#41 neck_z=0.0,
#42 body_y=0.0,
#43 body_z=0.0,
#44 breathing= 0.0
抽象的なポースデータ形式
上記のままでは操作が煩雑なので新たに2種類の形式を定義しました。
パック化したポース形式
各部位ごとに分離して人が見て容易に判断ができる形式です。
パック形式
0 eyebrow_dropdown: "troubled","angry","lowered","raised","happy","serious"
1 eyebrow_leftt, eyebrow_right: float:[0.0,0.0]
2 eye_dropdown: "wink","happy_wink","surprised","relaxed","unimpressed","raised_lower_eyelid"
3 eye_left, eye_right : float:[0.0,0.0]
4 iris_small_left, iris_small_right: float:[0.0,0.0]
5 iris_rotation_x, iris_rotation_y : float:[0.0,0.0]
6 mouth_dropdown:
"aaa","iii","uuu","eee","ooo","delta","lowered_corner" "raised_corner","smirk"
7 mouth_left, mouth_right : float:[0.0,0.0]
8 head_x, head_y : float:[0.0,0.0]
9 neck_z, float
10 body_y, float
11 body_z: float
12 breathing: float
パック化したPoseの例
pose=["happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i3/50],i3/50, 0.0, 0.0, 0.0]
更に簡略化したポーズ形式
リストを省いて文字列で記述しています。jesonでリストを型指定ぜすに送受信した場合などで見られますが、数字の演算ができないので直接この形式からは生成はできず、ポーズ形式に変換が必要です。
pose="happy,0,0,wink,0.9,0.9,0,0,0,0,aaa,0,0,0,0,0,0,0,0"
変換の例
pose=pose.split(",")
new_pose=[]
new_pose.append(pose[0])
new_pose.append([float(pose[1]),float(pose[2])])
new_pose.append(pose[3])
new_pose.append([float(pose[4]),float(pose[5])])
new_pose.append([float(pose[6]),float(pose[7])])
new_pose.append([float(pose[8]),float(pose[9])])
new_pose.append(pose[10])
new_pose.append([float(pose[11]),float(pose[12])])
new_pose.append([float(pose[13]),float(pose[14])])
new_pose.append(float(pose[15]))
new_pose.append(float(pose[16]))
new_pose.append(float(pose[17]))
new_pose.append(float(pose[18]))Dictionary形式のポーズデータ
更に抽象化を進めて、各データ毎に指定して操作ができるよう、Dictinary形式を定義しました。この形式はKEYを用いてポースデータの指定ができるので特定の部位のポースだけを変えたい場合にはとても便利です。
Dict形式
pose_dic={"eyebrow":{"menue":"happy","left":0.5,"right":0.0},
"eye":{"menue":"wink","left":0.5,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.7},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0
}
Dict形式の例
current_pose_dic=pose_dic #pose_dicの読み込み
current_pose_dic["eye"]["menue"]="wink" #wink指定
current_pose_dic["eye"]["left"]=i/(fps_time/2) #左目指定
current_pose_dic["head"]["y"]=i3/(fps_time/2) #頭ーy軸
current_pose_dic["neck"]=i3/(fps_time/2) #首
current_pose_dic["body"]["y"]=i*5/(fps_time/2) #体ーy軸指定
TalkingHeadAnimefaceクラス
プログラムから容易にポーズを変えるためのユーティリティー郡です。
指定できるポースデータは上記3種類、画像のアップロード機能は複数の画像を画像番号とuser_idで管理でき、生成ごとの画像のアップロードを省略できるとともにサーバ化時には複数ユーザによるアクセスにも対応しています。
コードの説明
初期化
モデルのロードとアップロード画像管理用のリスト初期化などを行います。
def __init__(self):
MODEL_NAME = "separable_float"
DEVICE_NAME = "cuda"
self.device = torch.device(DEVICE_NAME)
self.poser = load_poser(MODEL_NAME, DEVICE_NAME)
self.poser.get_modules()
self.torch_base_image_list=[0]*20
self.user_id_list=[0]*20
self.next_img=0ポーズデータの変換
抽象化されたパックポーズやDictポーズデータをオリジナルのベタなポーズデータに変換します。
def get_pose(self,pose_pack) #-----パック形式変換用クラス
def get_pose_dic(self,dic) #--- Dict形式変換用クラス
get_init_dic(self) #--- Dict形式のテンプレート取得
ポーズ生成
各ポーズ形式で使う生成クラスを準備しています。
def inference(self,input_img,current_pose):
#リポジトリの形式-オリジナルポーズ形式、イメージは毎回ロード
特別な処理をせず、リポジトリの生成を直接呼び出します。MOCAPなどで利用します。
def inference_img(self,current_pose,img_number,user_id):
# リポジトリの形式-オリジナルポーズ形式 イメージは事前ロード
ポーズデータは同じですが、画像は事前にロードしている画像を利用します。オーバーヘッドが少ない効率の良い生成が可能です。こちらもMOCAPなどのキャプチャデータから生成する用途向けです。
inference_pos(self,packed_current_pose,img_number,user_id):
#パック形式 イメージは事前ロード
パック化リスト形式です。プログラムから呼び出します。リストの項目を
すべて同時に指定できます。
inference_dic(self,current_dic,img_number,user_id):
#Dict形式 イメージは事前ロード
keyで指定した部分のみを動かすときに有効です。
今回のTalkingHeadAnimefaceクラスでは上記のポーズの相互変換を準備していません。現在のポーズの保持はユーザで行わなければならないので各ポーズ形式を混在させることはできません。
テスト
python poser_api_v1_2_test.py --test 1
--test 1でサンプルを選ぶことができます。
サンプル 1
ベタ書き リポジトリの形式-オリジナルポーズ形式 inference()を使用 イメージは毎回ロードする
サンプル 2
inference()を使用 Dict形式 イメージは毎回ロード
サンプル 3
inference()を使用 パック形式 イメージは毎回ロード
サンプル 4
inference_dic()を使用 DICT形式 イメージは事前ロード
サンプル 5
inference_img() オリジナルポーズのベタ書き イメージは事前ロード
サンプル 6
inference_img() パック形式 イメージは事前ロード
パック形式で連続変化させる
サンプル 7
inference_dic() DICT形式 イメージは事前ロード
DICT形式で連続変化させる
サンプル7を動かしたときの生成動画(リアルタイム生成された結果を記録した動画)
talking-head-animeface-3で作成した動画。 pic.twitter.com/HvjnOVBp79
— ゆずき (@uzuki425) February 13, 2024
準備した画像
この画像をダウンロードして、000001.pngで保存してください。

サンプル7のコード
Dicテンプレートを準備し、4stepで動かしています。各stepではkEYにより該当ポーズデータを指定し、for文のループカウンタからポーズデータを計算してKEYにより指定したポーズデータを変化させています。
#サンプル 7 inference_dic() DICT形式 イメージは事前ロード DICT形式で連続変化させる
if test==7:
print("TEST 4")
fps_time=30
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
cv2.imshow("image",imge)
cv2.waitKey() #この2行を入れると初期画像で一旦止まり、キーボードエンターで再開する
#input_image.show()
img_number=Tkh.load_img(input_image,0)
pose_dic={"eyebrow":{"menue":"happy","left":0.0,"right":0.0},
"eye":{"menue":"wink","left":0.0,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.0},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0
}
current_pose_list=[]
for i in range(int(fps_time/2)):
start_time=time.time()
current_pose_dic=pose_dic
current_pose_dic["eye"]["menue"]="wink"
current_pose_dic["eye"]["left"]=i/(fps_time/2)
current_pose_dic["head"]["y"]=i*3/(fps_time/2)
current_pose_dic["neck"]=i*3/(fps_time/2)
current_pose_dic["body"]["y"]=i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=1-i/(fps_time/2)
current_pose_dic["head"]["y"]=3-i*3/(fps_time/2)
current_pose_dic["neck"]=3-i*3/(fps_time/2)
current_pose_dic["body"]["y"]=5-i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=i/fps_time
current_pose_dic["eye"]["right"]=i/fps_time
current_pose_dic["head"]["y"]=-3+i*3/(fps_time/2)
current_pose_dic["neck"]=-3+i*3/(fps_time/2)
current_pose_dic["body"]["z"]=i*3/fps_time
current_pose_dic["body"]["y"]=-5+i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=0.0
current_pose_dic["eye"]["right"]=0.0
current_pose_dic["head"]["y"]=3-i*3/(fps_time/2)
current_pose_dic["neck"]=3-i*3/(fps_time/2)
current_pose_dic["body"]["z"]=3-i*3/fps_time
current_pose_dic["body"]["y"]=5-i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
image_show(imge)
cv2.waitKey(10000)TalkingHeadAnimefaceクラスの全ソースコード
import torch
import numpy as np
import cv2
from PIL import Image
import time
from tha3.util import extract_pytorch_image_from_PIL_image,torch_linear_to_srgb
from tha3.poser.modes.load_poser import load_poser
#generation Classのバリエーション
#
# inference(self,input_img,current_pose): #pose=リポジトリの形式、イメージは毎回ロード
# inference_img(self,current_pose,img_number,user_id): # pose=リポジトリの形式 イメージは事前ロード,複数画像対応
# inference_pos(self,packed_current_pose,img_number,user_id):# pose=パック形式 イメージは事前ロード,複数画像対応
# inference_dic(self,current_dic,img_number,user_id): # pose=Dict形式 イメージは事前ロード,複数画像対応
# ユーティリティClass
# get_pose(self,pose_pack): #パック形式 =>リポジトリの形式変換
# get_init_dic(self): #Dict形式の初期値を得る
# get_pose_dic(self,dic): #Dict形式 => リポジトリの形式変換
# load_img(self,input_img,user_id):# 画像をVRAMへ登録
class TalkingHeadAnimeface():
def __init__(self):
MODEL_NAME = "separable_float"
DEVICE_NAME = "cuda"
self.device = torch.device(DEVICE_NAME)
self.poser = load_poser(MODEL_NAME, DEVICE_NAME)
self.poser.get_modules()
self.torch_base_image_list=[0]*20
self.user_id_list=[0]*20
self.next_img=0
def get_pose(self,pose_pack):
#-----パック形式
#0 eyebrow_dropdown: str : "troubled", "angry", "lowered", "raised", "happy", "serious"
#1 eyebrow_leftt, eyebrow_right: float:[0.0,0.0]
#2 eye_dropdown: str: "wink", "happy_wink", "surprised", "relaxed", "unimpressed", "raised_lower_eyelid"
#3 eye_left, eye_right : float:[0.0,0.0]
#4 iris_small_left, iris_small_right: float:[0.0,0.0]
#5 iris_rotation_x, iris_rotation_y : float:[0.0,0.0]
#6 mouth_dropdown: str: "aaa", "iii", "uuu", "eee", "ooo", "delta", "lowered_corner", "raised_corner", "smirk"
#7 mouth_left, mouth_right : float:[0.0,0.0]
#8 head_x, head_y : float:[0.0,0.0]
#9 neck_z, float
#10 body_y, float
#11 body_z: float
#12 breathing: float
#
# Poseの例
# pose=["happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
pose=[float(0)]*45
#eyebrow
eyebrow=["troubled", "angry", "lowered", "raised", "happy", "serious"]
index=2*(eyebrow.index(pose_pack[0]))#eyebrowの指定からposeリストの位置を計算
pose[index]=float(pose_pack[1][0])
pose[index+1]=float(pose_pack[1][1])
print("eyebrow=",eyebrow[int(index/2)],pose[index],pose[index+1])
#eye
eye=["wink", "happy_wink", "surprised", "relaxed", "unimpressed", "raised_lower_eyelid"]
index=2*(eye.index(pose_pack[2]))#eyeの指定からposeリストの位置を計算
pose[12+index]=float(pose_pack[3][0])
pose[12+index+1]=float(pose_pack[3][1])
#iris
pose[24]=float(pose_pack[4][0])
pose[25]=float(pose_pack[4][1])
print("iris_small=",pose[25],pose[26])
#iris_rotation
pose[37]=float(pose_pack[5][0])
pose[38]=float(pose_pack[5][1])
print("iris_rotation=",pose[37],pose[38])
#mouth
mouth=["aaa", "iii", "uuu", "eee", "ooo", "delta", "lowered_corner", "raised_corner", "smirk"]
index=2*(mouth.index(pose_pack[6]))#mouthの指定からposeリストの位置を計算
pose[26+index]=float(pose_pack[7][0])
pose[26+index+1]=float(pose_pack[7][1])
print("mouth=",mouth[int(index/2)],pose[26+index],pose[26+index+1])
#head
pose[39]=float(pose_pack[8][0])
pose[40]=float(pose_pack[8][1])
print("head_x,y=",pose[39],pose[40])
#neck
pose[41]=float(pose_pack[9])
#body_y
pose[42]=float(pose_pack[10])
#body_z
pose[43]=float(pose_pack[11])
#breathing
pose[44]=float(pose_pack[12])
print("neck=",pose[41],"body_y=",pose[42],"body_z=",pose[43],"breathing=",pose[44])
return pose
def get_init_dic(self):
pose_dic_org={"eyebrow":{"menue":"happy","left":0.0,"right":0.0},
"eye":{"menue":"wink","left":0.0,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.0},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0,
}
return pose_dic_org
def get_pose_dic(self,dic):
#サンプル Dict形式
#"mouth"には2種類の記述方法がある"lowered_corner"と”raised_corner”は左右がある
# "mouth":{"menue":"aaa","val":0.0},
# "mouth":{"menue":"lowered_corner","left":0.5,"right":0.0}, これはほとんど効果がない
#
#pose_dic={"eyebrow":{"menue":"happy","left":0.5,"right":0.0},
# "eye":{"menue":"wink","left":0.5,"right":0.0},
# "iris_small":{"left":0.0,"right":0.0},
# "iris_rotation":{"x":0.0,"y":0.0},
# "mouth":{"menue":"aaa","val":0.7},
# "head":{"x":0.0,"y":0.0},
# "neck":0.0,
# "body":{"y":0.0,"z":0.0},
# "breathing":0.0
# }
pose=[float(0)]*45
#eyebrow
eyebrow=["troubled", "angry", "lowered", "raised", "happy", "serious"]
eyebrow_menue=dic["eyebrow"]["menue"]
index=2*(eyebrow.index(eyebrow_menue))#eyebrowの指定からposeリストの位置を計算
pose[index]=float(dic["eyebrow"]["left"])
pose[index+1]=float(dic["eyebrow"]["right"])
#eye
eye=["wink", "happy_wink", "surprised", "relaxed", "unimpressed", "raised_lower_eyelid"]
eye_menue=dic["eye"]["menue"]
index=2*(eye.index(eye_menue))#eyeの指定からposeリストの位置を計算
pose[12+index]=float(dic["eye"]["left"])
pose[13+index]=float(dic["eye"]["right"])
#iris_small
pose[24]=float(dic["iris_small"]["left"])
pose[25]=float(dic["iris_small"]["right"])
#iris_rotation
pose[37]=float(dic["iris_rotation"]["x"])
pose[38]=float(dic["iris_rotation"]["y"])
#mouth
mouth=["aaa", "iii", "uuu", "eee", "ooo", "delta","lowered_corner","raised_corner", "smirk"]
mouth_menue=dic["mouth"]["menue"]
if mouth_menue== "lowered_corner": #"lowered_corner","lowered_corner"
pose[32]=float(dic["mouth"]["left"])
pose[33]=float(dic["mouth"]["right"])
elif mouth_menue== "raised_corner": #"lowered_corner","raised_corner"
pose[34]=float(dic["mouth"]["left"])
pose[35]=float(dic["mouth"]["right"])
elif mouth_menue== "smirk": #"smirk"
pose[36]=float(dic["mouth"]["val"])
else:
index=(mouth.index(mouth_menue)) #"aaa", "iii", "uuu", "eee", "ooo", "delta"
pose[26+index]=float(dic["mouth"]["val"])
#head
head_x=dic["head"]["x"]
head_y=dic["head"]["y"]
pose[39]=float(head_x)
pose[40]=float(head_y)
#neck
pose[41]=float(dic["neck"])
#body
body_y=dic["body"]["y"]
body_z=dic["body"]["z"]
pose[42]=float(body_y)
pose[43]=float(body_z)
#breathing
pose[44]=float(dic["breathing"])
return pose
def load_img(self,input_img,user_id):
if self.next_img>19:
self.next_img=0
img_number=self.next_img
if user_id>19:
img_number=-1
return img_number #Error
self.user_id_list[img_number]=user_id
self.next_img +=1
if self.next_img>19:
self.next_img=0
self.torch_base_image_list[img_number]=extract_pytorch_image_from_PIL_image(input_img).cuda(0)
return img_number
def inference(self,input_img,current_pose):#リポジトリの形式-オリジナルポーズ形式、イメージは毎回ロード
torch_base_image = extract_pytorch_image_from_PIL_image(input_img).cuda(0)
pose = torch.tensor(current_pose, dtype=self.poser.get_dtype()).cuda(0)
with torch.inference_mode():
output_image = self.poser.pose(torch_base_image, pose)[0]
image = convert_output_image_from_torch_to_pil(output_image)
return image
def inference_img(self,current_pose,img_number,user_id):# リポジトリの形式-オリジナルポーズ形式 イメージは事前ロード
if self.user_id_list[img_number]!=user_id:
return 0 #image data was updated
pose = torch.tensor(current_pose, dtype=self.poser.get_dtype()).cuda(0)
with torch.inference_mode():
output_image = self.poser.pose(self.torch_base_image_list[img_number], pose)[0]
image = convert_output_image_from_torch_to_pil(output_image)
return image
def inference_pos(self,packed_current_pose,img_number,user_id):# パック形式 イメージは事前ロード
if self.user_id_list[img_number]!=user_id:
return 0 #image data was updated
current_pose=self.get_pose(packed_current_pose)
image = self.inference_img(current_pose,img_number,user_id)
return image
def inference_dic(self,current_dic,img_number,user_id):# Dict形式 イメージは事前ロード
if self.user_id_list[img_number]!=user_id:
return 0 #image data was updated
current_pose=self.get_pose_dic(current_dic)#current_dic==>current_pose2
image=self.inference_img(current_pose,img_number,user_id)
return image
# internal function
def convert_linear_to_srgb(image: torch.Tensor) -> torch.Tensor:
rgb_image = torch_linear_to_srgb(image[0:3, :, :])
return torch.cat([rgb_image, image[3:4, :, :]], dim=0)
def convert_output_image_from_torch_to_pil(output_image):
output_image = output_image.float()
output_image = convert_linear_to_srgb((output_image + 1.0) / 2.0)
c, h, w = output_image.shape
output_image = 255.0 * torch.transpose(output_image.reshape(c, h * w), 0, 1).reshape(h, w, c)
output_image = output_image.byte()
numpy_image = output_image.detach().cpu().numpy()
return Image.fromarray(numpy_image[:, :, 0:4], mode="RGBA")
テストプログラムの全コード
import time
from time import sleep
import numpy as np
import cv2
from PIL import Image
import argparse
from poser_api_v1_2_class import TalkingHeadAnimeface
#PIL形式の画像を動画として表示
def image_show(imge):
imge = np.array(imge)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
cv2.imshow("Loaded image",imge)
cv2.waitKey(1)
def main():
print("TEST")
parser = argparse.ArgumentParser(description='Talking Head')
parser.add_argument('--filename','-i', default='000001.png', type=str)
parser.add_argument('--test', default=0, type=int)
args = parser.parse_args()
test =args.test
print("TEST=",test)
filename =args.filename
Tkh=TalkingHeadAnimeface()
#************************* 便利な独自pose形式 *****************************
#-----パック形式
#0 eyebrow_dropdown: str : "troubled", "angry", "lowered", "raised", "happy", "serious"
#1 eyebrow_leftt, eyebrow_right: float:[0.0,0.0]
#2 eye_dropdown: str: "wink", "happy_wink", "surprised", "relaxed", "unimpressed", "raised_lower_eyelid"
#3 eye_left, eye_right : float:[0.0,0.0]
#4 iris_small_left, iris_small_right: float:[0.0,0.0]
#5 iris_rotation_x, iris_rotation_y : float:[0.0,0.0]
#6 mouth_dropdown: str: "aaa", "iii", "uuu", "eee", "ooo", "delta", "lowered_corner", "raised_corner", "smirk"
#7 mouth_left, mouth_right : float:[0.0,0.0]
#8 head_x, head_y : float:[0.0,0.0]
#9 neck_z, float
#10 body_y, float
#11 body_z: float
#12 breathing: float
#
# Poseの例
# pose=["happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
#
#-----Dict形式
#"mouth"には2種類の記述方法がある"lowered_corner"と”raised_corner”は左右がある
# "mouth":{"menue":"aaa","val":0.0},
# "mouth":{"menue":"lowered_corner","left":0.5,"right":0.0}, これはほとんど効果がない
#
#pose_dic={"eyebrow":{"menue":"happy","left":0.5,"right":0.0},
# "eye":{"menue":"wink","left":0.5,"right":0.0},
# "iris_small":{"left":0.0,"right":0.0},
# "iris_rotation":{"x":0.0,"y":0.0},
# "mouth":{"menue":"aaa","val":0.7},
# "head":{"x":0.0,"y":0.0},
# "neck":0.0,
# "body":{"y":0.0,"z":0.0},
# "breathing":0.0
# }
#*************************リポジトリの引数形式***********************
#----- 展開したcurrent_poseの形式
#current_pose= [
#0 troubled_eyebrow_left=0.0,
#1 troubled_eyebrow_right=0.0,
#2 angry_eyebrow_left= 0.0,
#3 angry_eyebrow_right 0.0,
#4 lowered_eyebrow_left= 0.0,
#5 lowered_eyebrow_right 0.0,
#6 raised_eyebrow_left= 0.0,
#7 raised_eyebrow_right 0.0,
#8 happy_eyebrow_left= 0.0,
#9 happy_eyebrow_right 0.02,
#10 serious_eyebrow_left= 0.0,
#11 serious_eyebrow_right=0.0,
#12 eye_wink_left= 0.0,
#13 eye_wink_right=0.0,
#14 eye_happy_wink=0.0,
#15 eye_happy_wink=0.0,
#16 eye_suprised_left=0.0,
#17 eye_suprised_right=0.0,
#18 eye_relaxed_left=0.0,
#19 eye_relaxed_right=0.0,
#20 eye_unimpressed_left=0.0,
#21 eye_unimpressed_right=0.0,
#22 eye_raised_lower_eyelid_left=0.0,
#23 eye_raised_lower_eyelid_right=_0.0,
#24 iris_small_left=0.0,
#25 iris_small_right0.0,
#26 mouth_dropdown_aaa=0.0,
#27 mouth_dropdown_iii=0.0,
#28 mouth_dropdown_uuu=0.0,
#29 mouth_dropdown_eee=0.0,
#30 mouth_dropdown_ooo=0.0,
#31 mouth_dropdown_delta=0.0,
#32 mouth_dropdown_lowered_corner_left=0.0,
#33 mouth_dropdown_lowered_corner_right=0.0,
#34 mouth_dropdown_raised_corner_left=0.0,
#35 mouth_dropdown_raised_corner_right=0.0,
#36 mouth_dropdown_smirk=0.0,
#37 iris_rotation_x=0.0,
#38 iris_rotation_y=0.0,
#39 head_x=0.0,
#40 head_y=0.0,
#41 neck_z=0.0,
#42 body_y=0.0,
#43 body_z=0.0,
#44 breathing= 0.0
#]
#サンプル 1 ベタ書き リポジトリの形式-オリジナルポーズ形式 inference()を使用 イメージは毎回ロードする
if test==1:
input_image = Image.open(filename)
input_image.show()
current_pose3= [0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.5,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0, 0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0,
0.0, 0.0,
0.0, 0.0,
0.767,
0.566,
0.626,
0.747,
0.485,
0.444,
0.232,
0.646,
1.0]
out_image=Tkh.inference(input_image,current_pose3)
out_image.show()
#サンプル 2 inference()を使用 Dict形式 イメージは毎回ロード
if test==2:
input_image = Image.open(filename)
input_image.show()
#サンプル Dict形式
#"mouth"には2種類の記述方法がある"lowered_corner"と”raised_corner”は左右がある
# "mouth":{"menue":"aaa","val":0.0},
# "mouth":{"menue":"lowered_corner","left":0.5,"right":0.0},
pose_dic={"eyebrow":{"menue":"happy","left":1.0,"right":0.0},
"eye":{"menue":"wink","left":0.5,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.7},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0
}
pose=Tkh.get_pose_dic(pose_dic)#Dic-> pose変換
print(pose)
out_image=Tkh.inference(input_image,pose)
out_image.show()
#サンプル 3 inference()を使用 パック形式 イメージは毎回ロード #packed_pose=>current_pose2
if test==3:
input_image = Image.open(filename)
input_image.show()
packed_pose=[
"happy", [0.5,0.0], "wink", [1.0,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,0.0], 0.0, 0.0,0.0, 0.0]
current_pose2=Tkh.get_pose(packed_pose) #packed_pose=>current_pose2
out_image=Tkh.inference(input_image,current_pose2)
out_image.show()
#サンプル 4 inference_dic()を使用 DICT形式 イメージは事前ロード
if test==4:
print("TEST 4")
input_image = Image.open(filename)
#input_image.show()
img_number=Tkh.load_img(input_image,0)
pose_dic={"eyebrow":{"menue":"happy","left":0.0,"right":0.0},
"eye":{"menue":"wink","left":0.0,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.0},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0
}
current_pose_list=[]
for i in range(20):
start_time=time.time()
current_pose_dic=pose_dic
current_pose_dic["eye"]["menue"]="wink"#pose_dicに対して動かしたい必要な部分だけ操作できる
current_pose_dic["eye"]["left"]=i*2/40 #
start_time=time.time()
out_image = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(out_image)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
##サンプル 5 inference_img() オリジナルポーズのベタ書き
if test==5:
input_image = Image.open(filename)
input_image.show()
img_number=Tkh.load_img(input_image,0)
for i in range(100):
current_pose3= [0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0, 0.0, 0.0, i/100, 0.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,0.0, 0.0, 0.78, 0.57, 0.63, 0.75, 0.49, 0.43,0.23, 0.65,1.0]
out_image=Tkh.inference_img(current_pose3,img_number,0)
image_show(out_image)
#サンプル 6 inference_img() イメージは事前ロード パック形式 #packed_pose=>current_pose2 パック形式で連続変化させる
if test==6:
input_image = Image.open(filename)
input_image.show()
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
#cv2.imshow("Loaded image",imge)
#cv2.waitKey() #この2行を入れると初期画像で一旦止まり、キーボードエンターで再開する
img_number=Tkh.load_img(input_image,0)
for i in range(50):
packed_current_pose=[
"happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
start_time=time.time()
current_pose2=Tkh.get_pose(packed_current_pose) #packed_pose=>current_pose2
out_image=Tkh.inference_img(current_pose2,img_number,0)
image_show(out_image)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(100):
packed_current_pose=[
"happy", [0.5,0.0], "wink",[1-i/50,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/50], 3-i*3/50, 0.0, 0.0, 0.0,]
start_time=time.time()
current_pose2=Tkh.get_pose(packed_current_pose)#packed_current_pose==>current_pose2
out_image=Tkh.inference_img(current_pose2,img_number,0)
image_show(out_image)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(100):
packed_current_pose=[
"happy", [0.5,0.0], "wink", [i/100,i/100], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,-3+i*3/50], -3+i*3/50,0.0, 0.0,0.0,]
start_time=time.time()
current_pose2=Tkh.get_pose(packed_current_pose)#packed_current_pose==>current_pose2
out_image=Tkh.inference_img(current_pose2,img_number,0)
image_show(out_image)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(100):
packed_current_pose=[
"happy", [0.5,0.0], "wink", [0.0,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/100], 3-i*3/100, 0.0, 0.0, 0.0,]
start_time=time.time()
current_pose2=Tkh.get_pose(packed_current_pose) #packed_current_pose==>current_pose2
out_image=Tkh.inference_img(current_pose2,img_number,0)
image_show(out_image)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
image_show(out_image)
cv2.waitKey(10000)
#サンプル 7 inference_dic() DICT形式 イメージは事前ロード DICT形式で連続変化させる
if test==7:
print("TEST 4")
fps_time=30
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
cv2.imshow("image",imge)
cv2.waitKey() #この2行を入れると初期画像で一旦止まり、キーボードエンターで再開する
#input_image.show()
img_number=Tkh.load_img(input_image,0)
pose_dic={"eyebrow":{"menue":"happy","left":0.0,"right":0.0},
"eye":{"menue":"wink","left":0.0,"right":0.0},
"iris_small":{"left":0.0,"right":0.0},
"iris_rotation":{"x":0.0,"y":0.0},
"mouth":{"menue":"aaa","val":0.0},
"head":{"x":0.0,"y":0.0},
"neck":0.0,
"body":{"y":0.0,"z":0.0},
"breathing":0.0
}
current_pose_list=[]
for i in range(int(fps_time/2)):
start_time=time.time()
current_pose_dic=pose_dic
current_pose_dic["eye"]["menue"]="wink"
current_pose_dic["eye"]["left"]=i/(fps_time/2)
current_pose_dic["head"]["y"]=i*3/(fps_time/2)
current_pose_dic["neck"]=i*3/(fps_time/2)
current_pose_dic["body"]["y"]=i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=1-i/(fps_time/2)
current_pose_dic["head"]["y"]=3-i*3/(fps_time/2)
current_pose_dic["neck"]=3-i*3/(fps_time/2)
current_pose_dic["body"]["y"]=5-i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=i/fps_time
current_pose_dic["eye"]["right"]=i/fps_time
current_pose_dic["head"]["y"]=-3+i*3/(fps_time/2)
current_pose_dic["neck"]=-3+i*3/(fps_time/2)
current_pose_dic["body"]["z"]=i*3/fps_time
current_pose_dic["body"]["y"]=-5+i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
for i in range(fps_time):
start_time=time.time()
current_pose_dic["eye"]["left"]=0.0
current_pose_dic["eye"]["right"]=0.0
current_pose_dic["head"]["y"]=3-i*3/(fps_time/2)
current_pose_dic["neck"]=3-i*3/(fps_time/2)
current_pose_dic["body"]["z"]=3-i*3/fps_time
current_pose_dic["body"]["y"]=5-i*5/(fps_time/2)
start_time=time.time()
imge = Tkh.inference_dic(current_pose_dic,img_number,0)
image_show(imge)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
image_show(imge)
cv2.waitKey(10000)
if __name__ == "__main__":
main()
まとめ
大変長いソースコードですが、ポーズデータ形式のコメント部分が半数を占めており、各クラス、各テストサンプルともに独立したコードなので難解な部分は無いと思います。次回はサーバ化について記事を書く予定です。