
1枚絵からリアルタイムにアニメキャラを動かすーTalking-Head-AnimeFace3ー アップスケールで任意エリア拡大

はじめに
前回はリアルタイムアップスケールの記事でした。前回の記事と、以前に書いた一枚絵からキャラを動かすTalkingHeadAnimefaceを組み合わて、キャラの任意の部分、例えば「胸から上」、「上半身」あるいは、「首から上」のようなエリス指定をしながらリアルタイムに拡大した動きを得るとができます。TalkingHeadAnimefaceとreal-ESRGANは生成速度に差があり、またapiサーバとすることで画像の大きさによる通信のオーバーヘッドも生じます。フレームレートを維持しつつキャラを動かすために、今回はマルチプロセッシングを利用して実装しています。
参考記事
参考記事とどこが違うのか
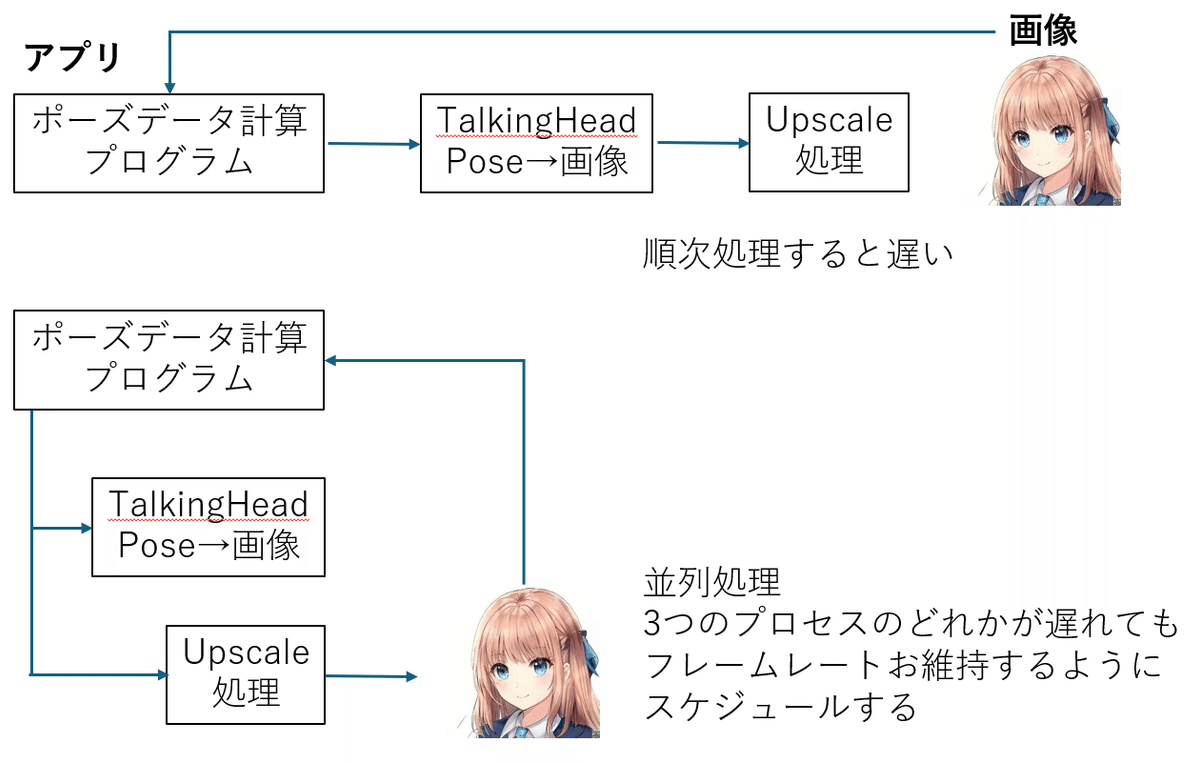
参考記事では各々の技術を個別に動かしています。それそれで意味があるのですが、キャラを自由に扱いたいとなれば、必要な部分の拡大がしたくなります。TalkingHeadAnimefaceは後者の記事にあるように動かす画像のテンプレートが決まっていて、拡大ができません。VTuberの方がされているような上半身やポートレートサイズのキャラはTalkingHeadAnimefaceの出力画像から必要な部分をクロップすればいいのですが、画像が小さくなります。そこで前者のリアルタイムアップスケールの登場です。TalkingHeadAnimefaceは生成時間が低specのGPUでも20FPS程度で動かくことができますが、そのままアップスケールを行うと、合計時間が必要で上位のGPUでも20FPSがギリギリです。キャラを動かすだけのために高価なGPUは使いたくありませんから、工夫が必要です。そこで並列処理の登場です。Pythonはいくつか並列処理が準備されていますが、今回はCPUコアを効率よく使うため、multiprocessingを用いました。以下の図をご覧ください。
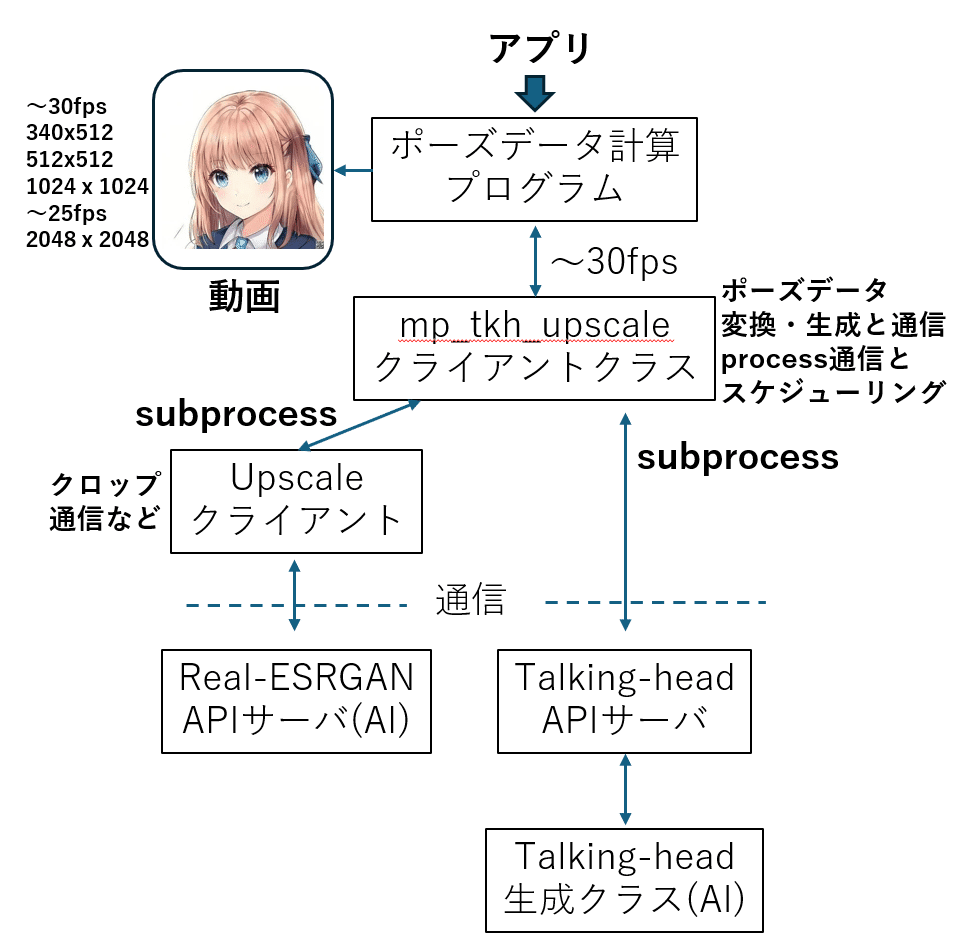
アプリに当たるテストプログラムではフレームごとのポーズの計算を行います。その後、TalkingHeadAnimefaceサーバでポーズデータから画像を生成し、生成画像から必要な部分をクロップしてreal-ESRGANを用いたアップスケーラで拡大します。ここで、TalkingHeadAnimefaceとreal-ESRGANサーバとの通信処理をテストプログラムのポーズデータの計算ルーティンから各々分離し、ポーズデータの計算//ポーズデータから画像生成//アップスケールの3種類の処理が並列に行われるよう、スケジューリングします。また途中でいずれかの処理が間に合わなかった場合はスキップできるよう配慮します。この配慮が無いと遅い処理、具体的にはアップスケールで入力画像データの受取に使うqueueが”詰まる"ってしまい、処理が停止することがあります。
各サーバ
TalkingHeadAnimefaceサーバ
アップスケールサーバ
ともに上記の記事を利用します。今回の記事では各サーバを並列に動かすmultiprocessingとスケージューリングについて書いています。
multiprocessing
ポーズ計算とTalkingHeadAnimeface及びアップスケールプロセスを生成します。このときポーズ計算処理との通信に使うqueueも定義します。送受信あるので、4本のqueueを準備しています。
初期化部分
定義しているだけです。
#アップスケールマルチプロセッシングのqueue,process初期化
self.queue_in_image = None
self.queue_out_image =None
self.proc = None
self.queue_tkh_pose =None
self.queue_tkh_image =None
self.tkh_proc =NoneTalkingHeadプロセスの準備と開始処理
ポーズ計算を行うテストプログラムからcreate_mp_tkh()が呼び出されるとqueue_thk_pose
wueue_tkh_image
を作成します。
その後、tkh_procプロセスを作成し、プロセスを開始します。実際の処理は_mp_tkh()で行われ、ポーズデータを受け取るqueue_tkh_poseを監視し、poseデータがあれば、inference_img()で画像に変換します。ここがTalkingHeadAnimefaceサーバと通信を行い、画像データを受信しています。
得られた画像はqueue_tkh_imageへputしています。
#tkhプロセスの開始
def create_mp_tkh(self):
self.queue_tkh_pose = multiprocessing.Queue() # 入力Queueを作成
self.queue_tkh_image = multiprocessing.Queue() # 出力Queueを作成
self.tkh_proc = multiprocessing.Process(target=self._mp_tkh, args=(self.queue_tkh_image,self.queue_tkh_pose)) #process作成
self.tkh_proc.start() #process開始
#tkhプロセス実行関数--terminateされるまで連続で動きます
def _mp_tkh(self,queue_tkh_pose,queue_tkh_image):
print("Tkh process started")
while True:
if self.queue_tkh_pose.empty()==False:
received_data = self.queue_tkh_pose.get()
current_pose=received_data[0]
img_number=received_data[1]
user_id=received_data[2]
out_typ=received_data[3]
result, out_image=self.inference_img(current_pose,img_number,user_id,out=out_typ)
self.queue_tkh_image.put(out_image)
time.sleep(0.002)アップスケールプロセスの準備と開始処理
入出力queueを作成し、proc作成時に渡しています。実際に#アップスケール処理が行われるのは_mp_upscale()です。テストプログラムからcreate_mp_upscale()を呼び出して初期化とプロセスの開始をします。
_mp_upscale()はqueue_in_imageを監視し、データが来ればupscale()を呼び出して拡大画像を得ます。拡大画像をqueue_out_imageへputしてループに戻ります。
#アップスケールプロセスの開始
def create_mp_upscale(self,url):
self.queue_in_image = multiprocessing.Queue() # 入力Queueを作成
self.queue_out_image = multiprocessing.Queue() # 出力Queueを作成
self.proc = multiprocessing.Process(target=self._mp_upscal, args=(url ,self.queue_in_image,self.queue_out_image)) #process作成
self.proc.start() #process開始
#アップスケールプロセス実行関数--terminateされるまで連続で動きます
def _mp_upscal(self,url ,queue_in_image,queue_out_image):
print("Process started")
while True:
if self.queue_in_image.empty()==False:
received_data = self.queue_in_image.get() # queue_in_imageからデータを取得
received_image=received_data[0]
mode=received_data[1]
scale=received_data[2]
out_image=upscale(url ,received_image, mode, scale)
self.queue_out_image.put(out_image)
time.sleep(0.001)スケージューリング
テストプログラムで計算されたフォレームごとのポーズデータをTalkingHeadプロセスに渡し、生成された画像をアップスケールプロセスに渡します。さらにアップスケールされた画像を呼び出し先へ戻します。ここで、計算サーバから一連の処理が終わる間は待ちがなく、各プロセスに処理が渡されるとテストプログラムの計算処理が次のポースデータを計算します。TalkingHeadプロセスとアップスケールプロセスは画像の大きさにより処理の速さが前後します。間に合わない場合はレクエストを飛ばす処理や、TalkingHeadプロセスによる画像が準備されていないときの処理が必要です。以下のコードのmp_dic2image_frame()で各プロセスを呼ぶための、 _mp_inference_img()と_mp_get_upscale()を順次呼び出しています。
呼び出された、_mp_inference_img()と_mp_get_upscale()は依頼データが処理さているのか処理待ちかを判断し、処理待ちであればqueueの”詰まり”を避けるためskipし、空ならqueueaへ依頼データをputします。TalkingHeadプロセスとアップスケールプロセスは各入力queueを監視しているのでデータが入ると速やかにサーバと通信して画像を取得し出力queueへ返します。_mp_inference_img()と_mp_get_upscale()は結果が得られていかqueue_tkh_imageとqueue_in_imageを見て判断し、準備されていればqueueから取得(queue_tkh_image.get() 、queue_out_image.get())します。
フレームレート正確に合わせるにはテストプログラムからの依頼、各プロセスの時間のいずれかで合わすことができます。以下では最も時間が掛かりそうなアップスケールプロセスで行っています。ポーズ計算側、あるいは更に上位の処理で行う方が見通しが良さそうです。
def mp_dic2image_frame(self,global_out_image,current_pose_dic,img_number,user_id,mode,scale,fps):
frame_start=time.time()
current_pose=self.get_pose_dic(current_pose_dic)
out_image=self._mp_inference_img(global_out_image, current_pose,img_number,user_id,out_typ="cv2")
up_scale_image = self._mp_get_upscale(global_out_image,out_image,mode,scale,fps,frame_start)
return up_scale_image
def _mp_inference_img(self,global_out_image, current_pose,img_number,user_id,out_typ="cv2"):
if self.queue_tkh_pose.empty()==True:
send_data=[current_pose , img_number , user_id,out_typ]
self.queue_tkh_pose.put(send_data)
if self.queue_tkh_image.empty()==False:
get_out_image = self.queue_tkh_image.get() # queue_in_imageからデータを取得
self.previous_image=get_out_image
else:
print("skip kh_image")
get_out_image=self.previous_image #<<<<global_out_imageは拡大後のイメージなので、前回のTKHの生成イメージが必要
return get_out_image
def _mp_get_upscale(self,global_out_image,out_image,mode,scale,fps,frame_start):
if self.queue_in_image.empty()==True:
send_data=[out_image , mode , scale]
self.queue_in_image.put(send_data)
if self.queue_out_image.empty()==False:
global_out_image = self.queue_out_image.get() # queue_in_imageからデータを取得
try:
sleep(1/fps - (time.time()-frame_start))
except:
print("Remain time is minus")
return global_out_imageこれらの処理をまとめた class TalkingHeadAnimefaceInterface():は最後に各コードとまとめて公開します
イメージのクロップ
アップスケールサーバを呼び出す時に画像のクロップも行っています。以下はtkh_up_scale.pyのKコードの一部です。upscale()の最初でクロップを行い、up_scale(url , cropped_image , scale)で通信をします。
def upscale(url ,image, mode, scale):
if mode=="breastup":
cropped_image = crop_image(image, top=55, left=128, height=256, width=256)
elif mode=="waistup":
cropped_image = crop_image(image, top=55, left=128, height=290, width=256)
elif mode=="upperbody":
cropped_image = crop_image(image, top=55, left=143, height=336, width=229)
elif mode=="full":
cropped_image = image
else:
cropped_image = crop_image(image, top=mode[0], left=mode[1], height=mode[2], width=mode[3])
return up_scale(url , cropped_image , scale)
テスト
2種類のテストを準備しました。
1:ポーズ形式が簡略化されたリスト
2:ポーズ形式が抽象化されたdictionary形式
いくつかのspepでキャラクタを左右に動かしながら目を閉じラリ開けたりさせています。
初期化
いくつかの変数の初期化及び各プロセスの起動を行います。
def main():
parser = argparse.ArgumentParser(description='Talking Head')
parser.add_argument('--filename','-i', default='000002.png', type=str)
parser.add_argument('--test', default=0, type=int)
parser.add_argument('--host', default='http://0.0.0.0:8001', type=str)
parser.add_argument('--esr', default='http://0.0.0.0:8008', type=str)
args = parser.parse_args()
test =args.test
filename =args.filename
user_id=0 #便宜上設定している。0~20の範囲。必ず設定すること
tkh_url=args.host
esr_url=args.esr + "/resr_upscal/"
#Thiの酒器化
Thi=TalkingHeadAnimefaceInterface(tkh_url) # tkhのホスト
# アップスケールのURLはプロセスで指定
#pose_dic_orgの設定。サーバからもらう
pose_dic_org = Thi.get_init_dic()
#アップスケールとtkhプロセスの開始
Thi.create_mp_upscale(esr_url)
Thi.create_mp_tkh()テスト1
inference_img() poseはパック形式形式をリポジトリの形式に変換 イメージは事前ロード,パック形式で連続変化させる
#サンプル 1 inference_img() poseはパック形式形式をリポジトリの形式に変換 イメージは事前ロード,パック形式で連続変化させる
if test==1:
fps=30
#mode="breastup" # "breastup" , "waistup" , upperbody" , "full"
#mode="waistup"
mode=[55,155,200,202] #[top,left,hight,whith] リストでクロップトしたい画像を指定できる
scale=8 # 2/4/8
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
result_out_image = imge
cv2.imshow("image",imge)
cv2.waitKey() #ここで一旦止まり、キー入力で再開する
img_number=Thi.load_img(input_image,user_id) # 画像のアップロード
print("img_number=",img_number)
for i in range(50):
start_time=time.time()
packed_current_pose=[
"happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink",[1-i/50,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/50], 3-i*3/50, 0.0, 0.0, 0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink", [i/100,i/100], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,-3+i*3/50], -3+i*3/50,0.0, 0.0,0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink", [0.0,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/100], 3-i*3/100, 0.0, 0.0, 0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(5000)テスト2
inference_dic() poseはDICT形式で直接サーバを呼ぶ イメージは事前ロード DICT形式で必要な部分のみ選んで連続変化させる
#サンプル 2 inference_dic() poseはDICT形式で直接サーバを呼ぶ イメージは事前ロード DICT形式で必要な部分のみ選んで連続変化させる
if test==2:
fps=35
#mode="breastup" #
#mode=[55,155,200,202] #[top,left,hight,whith]
mode="waistup"
scale=4 # 2/4/8
div_count=30
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
result_out_image = imge
cv2.imshow("image",imge)
cv2.waitKey() #ここで一旦止まり、キー入力で再開する
img_number=Thi.load_img(input_image,user_id) # 画像のアップロード
pose_dic=pose_dic_org #Pose 初期値
current_pose_list=[]
for i in range(int(div_count/2)):
start_time=time.time()
current_pose_dic=pose_dic
current_pose_dic["eye"]["menue"]="wink"
current_pose_dic["eye"]["left"]=i/(div_count/2)
current_pose_dic["head"]["y"]=i*3/(div_count/2)
current_pose_dic["neck"]=i*3/(div_count/2)
current_pose_dic["body"]["y"]=i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=1-i/(div_count/2)
current_pose_dic["head"]["y"]=3-i*3/(div_count/2)
current_pose_dic["neck"]=3-i*3/(div_count/2)
current_pose_dic["body"]["y"]=5-i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=i/div_count
current_pose_dic["eye"]["right"]=i/div_count
current_pose_dic["head"]["y"]=-3+i*3/(div_count/2)
current_pose_dic["neck"]=-3+i*3/(div_count/2)
current_pose_dic["body"]["z"]=i*3/div_count
current_pose_dic["body"]["y"]=-5+i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=0.0
current_pose_dic["eye"]["right"]=0.0
current_pose_dic["head"]["y"]=3-i*3/(div_count/2)
current_pose_dic["neck"]=3-i*3/(div_count/2)
current_pose_dic["body"]["z"]=3-i*3/div_count
current_pose_dic["body"]["y"]=5-i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(5000)各プロセスの停止
これをしないとプロセスが残ります。
#サブプロセスの終了
Thi.up_scale_proc_terminate()
Thi.tkh_proc_terminate()
print("end of test")コードの全て
サーバ側は冒頭の記事を利用しています。動く順に並べています。
テストプログラム
python poser_client_tkhmp_upmp_v1_3_upscale_test.py --test 2
のようにテスト番号を指定します。パラメータはハードコードされてるので適時変更してください。
import numpy as np
import cv2
from PIL import Image
import argparse
from time import sleep
import time
from poser_client_tkhmp_upmp_v1_3_class import TalkingHeadAnimefaceInterface
from tkh_up_scale import upscale
#PIL形式の画像を動画として表示
def image_show(imge):
imge = np.array(imge)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
cv2.imshow("Loaded image",imge)
cv2.waitKey(1)
def main():
parser = argparse.ArgumentParser(description='Talking Head')
parser.add_argument('--filename','-i', default='000002.png', type=str)
parser.add_argument('--test', default=0, type=int)
parser.add_argument('--host', default='http://0.0.0.0:8001', type=str)
parser.add_argument('--esr', default='http://0.0.0.0:8008', type=str)
args = parser.parse_args()
test =args.test
filename =args.filename
user_id=0 #便宜上設定している。0~20の範囲。必ず設定すること
tkh_url=args.host
esr_url=args.esr + "/resr_upscal/"
#Thiの酒器化
Thi=TalkingHeadAnimefaceInterface(tkh_url) # tkhのホスト
# アップスケールのURLはプロセスで指定
#pose_dic_orgの設定。サーバからもらう
pose_dic_org = Thi.get_init_dic()
#アップスケールとtkhプロセスの開始
Thi.create_mp_upscale(esr_url)
Thi.create_mp_tkh()
#サンプル 1 inference_img() poseはパック形式形式をリポジトリの形式に変換 イメージは事前ロード,パック形式で連続変化させる
if test==1:
fps=30
#mode="breastup" # "breastup" , "waistup" , upperbody" , "full"
#mode="waistup"
mode=[55,155,200,202] #[top,left,hight,whith] リストでクロップトしたい画像を指定できる
scale=8 # 2/4/8
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
result_out_image = imge
cv2.imshow("image",imge)
cv2.waitKey() #ここで一旦止まり、キー入力で再開する
img_number=Thi.load_img(input_image,user_id) # 画像のアップロード
print("img_number=",img_number)
for i in range(50):
start_time=time.time()
packed_current_pose=[
"happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink",[1-i/50,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/50], 3-i*3/50, 0.0, 0.0, 0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink", [i/100,i/100], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,-3+i*3/50], -3+i*3/50,0.0, 0.0,0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(100):
start_time=time.time()
packed_current_pose=[
"happy", [0.5,0.0], "wink", [0.0,0.0], [0.0,0.0], [0.0,0.0], "ooo", [0.0,0.0], [0.0,3-i*3/100], 3-i*3/100, 0.0, 0.0, 0.0,]
result_out_image,result = Thi.mp_pack2image_frame(result_out_image,packed_current_pose,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(5000)
#サンプル 2 inference_dic() poseはDICT形式で直接サーバを呼ぶ イメージは事前ロード DICT形式で必要な部分のみ選んで連続変化させる
if test==2:
fps=35
#mode="breastup" #
#mode=[55,155,200,202] #[top,left,hight,whith]
mode="waistup"
scale=4 # 2/4/8
div_count=30
input_image = Image.open(filename)
imge = np.array(input_image)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
result_out_image = imge
cv2.imshow("image",imge)
cv2.waitKey() #ここで一旦止まり、キー入力で再開する
img_number=Thi.load_img(input_image,user_id) # 画像のアップロード
pose_dic=pose_dic_org #Pose 初期値
current_pose_list=[]
for i in range(int(div_count/2)):
start_time=time.time()
current_pose_dic=pose_dic
current_pose_dic["eye"]["menue"]="wink"
current_pose_dic["eye"]["left"]=i/(div_count/2)
current_pose_dic["head"]["y"]=i*3/(div_count/2)
current_pose_dic["neck"]=i*3/(div_count/2)
current_pose_dic["body"]["y"]=i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=1-i/(div_count/2)
current_pose_dic["head"]["y"]=3-i*3/(div_count/2)
current_pose_dic["neck"]=3-i*3/(div_count/2)
current_pose_dic["body"]["y"]=5-i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=i/div_count
current_pose_dic["eye"]["right"]=i/div_count
current_pose_dic["head"]["y"]=-3+i*3/(div_count/2)
current_pose_dic["neck"]=-3+i*3/(div_count/2)
current_pose_dic["body"]["z"]=i*3/div_count
current_pose_dic["body"]["y"]=-5+i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
for i in range(div_count):
start_time=time.time()
current_pose_dic["eye"]["left"]=0.0
current_pose_dic["eye"]["right"]=0.0
current_pose_dic["head"]["y"]=3-i*3/(div_count/2)
current_pose_dic["neck"]=3-i*3/(div_count/2)
current_pose_dic["body"]["z"]=3-i*3/div_count
current_pose_dic["body"]["y"]=5-i*5/(div_count/2)
result_out_image,result = Thi.mp_dic2image_frame(result_out_image,current_pose_dic,img_number,user_id,mode,scale,fps)
print("Genaration time=",(time.time()-start_time)*1000,"mS")
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(1)
cv2.imshow("Loaded image",result_out_image)
cv2.waitKey(5000)
#サブプロセスの終了
Thi.up_scale_proc_terminate()
Thi.tkh_proc_terminate()
print("end of test")
if __name__ == "__main__":
main()
マルチプロセッシング対応のクライアント側APIクラス
poser_client_tkhmp_upmp_v1_3_class.py
import numpy as np
import cv2
from PIL import Image
import time
from time import sleep
import requests
import pickle
import multiprocessing
from tkh_up_scale import upscale
#generation Classのバリエーション
#
# inference(self,input_img,current_pose): #pose=リポジトリの形式、イメージは毎回ロード
# inference_img(self,current_pose,img_number,user_id): # pose=リポジトリの形式 イメージは事前ロード,複数画像対応
# inference_pos(self,packed_current_pose,img_number,user_id):# pose=パック形式 イメージは事前ロード,複数画像対応
# inference_dic(self,current_dic,img_number,user_id): # pose=Dict形式 イメージは事前ロード,複数画像対応
# mp_pose2image_frame # マルチプロセス版 pose→イメージ+クロップ+UPSCALE
# mp_pack2image_frame # マルチプロセス版 pose_pack→イメージ+クロップ+UPSCALE
# mp_dic2image_frame # マルチプロセス版 pose_dict→イメージ+クロップ+UPSCALE
# ユーティリティClass
# get_pose(self,pose_pack): #パック形式 =>リポジトリの形式変換
# get_init_dic(self): #Dict形式の初期値を得る
# get_pose_dic(self,dic): #Dict形式 => リポジトリの形式変換
# load_img(self,input_img,user_id):# 画像をVRAMへ登録
# create_mp_upscale(self,url) # upscaleプロセスの開始
# proc_terminate(self) # upscaleプロセスの停止
# mp_pose2image_frame # マルチプロセス版 pose→イメージ+クロップ+UPSCALE
# mp_pack2image_frame # マルチプロセス版 pose_pack→イメージ+クロップ+UPSCALE
# mp_dic2image_frame # マルチプロセス版 pose_dict→イメージ+クロップ+UPSCALE
class TalkingHeadAnimefaceInterface():
def __init__(self,host):
userid=0
self.url=host#Talking-Head-Animefaceのサーバホスト
#アップスケールマルチプロセッシングのqueue,process初期化
self.queue_in_image = None
self.queue_out_image =None
self.proc = None
self.queue_tkh_pose =None
self.queue_tkh_image =None
self.tkh_proc =None
self.previous_image = np.zeros((512, 512, 3), dtype=np.uint8)#upscaleが最初に呼び出される時に画像ができていないので初期値を設定
def get_init_dic(self):
response = requests.post(self.url+"/get_init_dic/") #リクエスト
if response.status_code == 200:
pose_data = response.content
org_dic =(pickle.loads(pose_data))#元の形式にpickle.loadsで復元
return org_dic
def get_pose(self,pose_pack):
#-----パック形式
#0 eyebrow_dropdown: str : "troubled", "angry", "lowered", "raised", "happy", "serious"
#1 eyebrow_leftt, eyebrow_right: float:[0.0,0.0]
#2 eye_dropdown: str: "wink", "happy_wink", "surprised", "relaxed", "unimpressed", "raised_lower_eyelid"
#3 eye_left, eye_right : float:[0.0,0.0]
#4 iris_small_left, iris_small_right: float:[0.0,0.0]
#5 iris_rotation_x, iris_rotation_y : float:[0.0,0.0]
#6 mouth_dropdown: str: "aaa", "iii", "uuu", "eee", "ooo", "delta", "lowered_corner", "raised_corner", "smirk"
#7 mouth_left, mouth_right : float:[0.0,0.0]
#8 head_x, head_y : float:[0.0,0.0]
#9 neck_z, float
#10 body_y, float
#11 body_z: float
#12 breathing: float
#
# Poseの例
# pose=["happy",[0.5,0.0],"wink", [i/50,0.0], [0.0,0.0], [0.0,0.0],"ooo", [0.0,0.0], [0.0,i*3/50],i*3/50, 0.0, 0.0, 0.0]
pose_pack_pkl = pickle.dumps(pose_pack, 5)
files = {"pose":("pos.dat",pose_pack_pkl, "application/octet-stream")}#listで渡すとエラーになる
response = requests.post(self.url+"/get_pose/", files=files) #リクエスト
if response.status_code == 200:
pose_data = response.content
pose =(pickle.loads(pose_data))#元の形式にpickle.loadsで復元
result = response.status_code
return pose
#アップスケールプロセスの開始
def create_mp_upscale(self,url):
self.queue_in_image = multiprocessing.Queue() # 入力Queueを作成
self.queue_out_image = multiprocessing.Queue() # 出力Queueを作成
self.proc = multiprocessing.Process(target=self._mp_upscal, args=(url ,self.queue_in_image,self.queue_out_image)) #process作成
self.proc.start() #process開始
#アップスケールプロセス実行関数--terminateされるまで連続で動きます
def _mp_upscal(self,url ,queue_in_image,queue_out_image):
print("Process started")
while True:
if self.queue_in_image.empty()==False:
received_data = self.queue_in_image.get() # queue_in_imageからデータを取得
received_image=received_data[0]
mode=received_data[1]
scale=received_data[2]
out_image=upscale(url ,received_image, mode, scale)
self.queue_out_image.put(out_image)
time.sleep(0.001)
#アップスケールプロセス停止関数--terminate
def up_scale_proc_terminate(self):
while not self.queue_out_image.empty():
self.queue_out_image.get_nowait()
while not self.queue_in_image.empty():
self.queue_in_image.get_nowait()
self.proc.terminate()#サブプロセスの終了
print("Upscale process terminated")
#tkhプロセスの開始
def create_mp_tkh(self):
self.queue_tkh_image = multiprocessing.Queue() # 入力Queueを作成
self.queue_tkh_pose = multiprocessing.Queue() # 出力Queueを作成
self.tkh_proc = multiprocessing.Process(target=self._mp_tkh, args=(self.queue_tkh_image,self.queue_tkh_pose)) #process作成
self.tkh_proc.start() #process開始
#tkhプロセス実行関数--terminateされるまで連続で動きます
def _mp_tkh(self,queue_tkh_pose,queue_tkh_image):
print("Tkh process started")
while True:
if self.queue_tkh_pose.empty()==False:
received_data = self.queue_tkh_pose.get()
current_pose=received_data[0]
img_number=received_data[1]
user_id=received_data[2]
out_typ=received_data[3]
result, out_image=self.inference_img(current_pose,img_number,user_id,out=out_typ)
self.queue_tkh_image.put(out_image)
time.sleep(0.002)
#tkhプロセス停止関数--terminate
def tkh_proc_terminate(self):
while not self.queue_tkh_pose.empty():
self.queue_tkh_pose.get_nowait()
while not self.queue_tkh_image.empty():
self.queue_tkh_image.get_nowait()
self.tkh_proc.terminate()#サブプロセスの終了
print("Tkh process terminated")
#Dict形式ポースデータから画像を生成し、アップスケールまで行う
# global_out_image :現在のイメージ
# current_pose :動かしたいポーズ
# img_number :アップロード時に返送されるイメージ番号
# user_id :画像の所有者id
# mode :クロップモード 早い<breastup・waistup・upperbody・full<遅い
# scale :画像の倍率 2/4/8 大きい指定ほど生成が遅くなる
# fps :指定フレームレート。生成が指定フレームレートに間に合わない場合は現在イメージ返送される
def mp_pose2image_frame(self,global_out_image,current_pose,img_number,user_id,mode,scale,fps):
frame_start=time.time()
result,out_image=self.inference(current_pose,img_number,user_id,"cv2")
up_scale_image,result = self._mp_get_upscale(global_out_image,out_image,mode,scale,fps,frame_start)
try:
sleep(1/fps - (time.time()-frame_start))
except:
print("Remain time is minus")
return up_scale_image,result
def mp_pack2image_frame(self,global_out_image,packed_current_pose,img_number,user_id,mode,scale,fps):
frame_start=time.time()
current_pose=self.get_pose(packed_current_pose) #packed_pose=>current_pose
out_image=self._mp_inference_img(global_out_image, current_pose,img_number,user_id,out_typ="cv2")
up_scale_image,result = self._mp_get_upscale(global_out_image,out_image,mode,scale,fps,frame_start)
if fps!=0:
try:
sleep(1/fps - (time.time()-frame_start))
except:
print("Remain time is minus")
return up_scale_image,result
def mp_dic2image_frame(self,global_out_image,current_pose_dic,img_number,user_id,mode,scale,fps):
frame_start=time.time()
current_pose=self.get_pose_dic(current_pose_dic)
out_image=self._mp_inference_img(global_out_image, current_pose,img_number,user_id,out_typ="cv2")
up_scale_image ,result= self._mp_get_upscale(global_out_image,out_image,mode,scale,fps,frame_start)
if fps!=0:
try:
sleep(1/fps - (time.time()-frame_start))
except:
print("Remain time is minus and sleep=0")
return up_scale_image,result
def _mp_inference_img(self,global_out_image, current_pose,img_number,user_id,out_typ="cv2"):
if self.queue_tkh_pose.empty()==True:
send_data=[current_pose , img_number , user_id,out_typ]
self.queue_tkh_pose.put(send_data)
if self.queue_tkh_image.empty()==False:
get_out_image = self.queue_tkh_image.get() # queue_in_imageからデータを取得
self.previous_image=get_out_image
else:
print("-----Talking Head Skip")
get_out_image=self.previous_image #<<<<global_out_imageは拡大後のイメージなので、前回のTKHの生成イメージが必要
return get_out_image
def _mp_get_upscale(self,global_out_image,out_image,mode,scale,fps,frame_start):
result=True
if self.queue_in_image.empty()==True:
send_data=[out_image , mode , scale]
self.queue_in_image.put(send_data)
if self.queue_out_image.empty()==False:
global_out_image = self.queue_out_image.get() # queue_in_imageからデータを取得
else:
result=False
print("+++++ Upscale skip")
#try:
# sleep(1/fps - (time.time()-frame_start))
#except:
# print("+++++ Upscale Remain time is minus")
return global_out_image,result
def get_pose_dic(self,dic):
#サンプル Dict形式
#"mouth"には2種類の記述方法がある"lowered_corner"と”raised_corner”は左右がある
# "mouth":{"menue":"aaa","val":0.0},
# "mouth":{"menue":"lowered_corner","left":0.5,"right":0.0}, これはほとんど効果がない
#
#pose_dic={"eyebrow":{"menue":"happy","left":0.5,"right":0.0},
# "eye":{"menue":"wink","left":0.5,"right":0.0},
# "iris_small":{"left":0.0,"right":0.0},
# "iris_rotation":{"x":0.0,"y":0.0},
# "mouth":{"menue":"aaa","val":0.7},
# "head":{"x":0.0,"y":0.0},
# "neck":0.0,
# "body":{"y":0.0,"z":0.0},
# "breathing":0.0
# }
#print("++++++ dic=",dic)
current_dic = pickle.dumps(dic, 5)
files = {"pose":("pos.dat",current_dic, "application/octet-stream")}#listで渡すとエラーになる
response = requests.post(self.url+"/get_pose_dic/", files=files) #リクエスト
if response.status_code == 200:
pose_data = response.content
pose =(pickle.loads(pose_data))#元の形式にpickle.loadsで復元
result = response.status_code
return pose
def load_img(self,input_img,user_id):
print("load_img")
images_data = pickle.dumps(input_img, 5)
files = {"image": ("img.dat", images_data, "application/octet-stream")}
data = {"user_id": user_id}
response = requests.post(self.url+"/load_img/", files=files, data=data) #リクエスト送信
if response.status_code == 200:
response_data = response.json()
print("response_data =",response_data)
img_number=response_data["img_number"]
else:
img_number=-1
return img_number
def inference(self,input_img,current_pose,out="pil"):#基本イメージ生成、イメージは毎回ロード
start_time=time.time()
images_data = pickle.dumps(input_img, 5)
current_pose2 = pickle.dumps(current_pose, 5)
files = {"image": ("img.dat",images_data, "application/octet-stream"),
"pose":("pos.dat",current_pose2, "application/octet-stream"),
"out":("out.dat", out, "application/octet-stream")}#listで渡すとエラーになる
response = requests.post(self.url+"/inference_org/", files=files) #リクエスト
if response.status_code == 200:
image_data = response.content
image =(pickle.loads(image_data))#元の形式にpickle.loadsで復元
result = response.status_code
return result, image
def inference_pos(self,packed_pose,img_number,user_id,out="pil"):#イメージは事前ロード
packed_pose = pickle.dumps(packed_pose, 5)
files={"pose":("pos.dat",packed_pose, "application/octet-stream"),}
# "img_number":img_number,
# "user_id": user_id,}#listで渡すとエラーになる
data = {"user_id": user_id,"img_number":img_number,"out":out}
response = requests.post(self.url+"/inference_pos/", files=files, data=data) #リクエスト送信
if response.status_code == 200:
image_data = response.content
image =(pickle.loads(image_data))#元の形式にpickle.loadsで復元
result = response.status_code
return result, image
def inference_dic(self,current_dic,img_number,user_id,out="pil"):#イメージは事前ロード
data = {"img_number":img_number,"user_id": user_id,"out":out}
current_dic2 = pickle.dumps(current_dic, 5)
files={"pose":("pos.dat",current_dic2, "application/octet-stream")}#listで渡すとエラーになる
response = requests.post(self.url+"/inference_dic/", data=data,files=files) #リクエスト送信
if response.status_code == 200:
image_data = response.content
image =(pickle.loads(image_data))#元の形式にpickle.loadsで復元
result = response.status_code
return result, image
def inference_img(self,current_pose,img_number,user_id,out="pil"):#イメージ事前ロード用生成 イメージは事前ロード
data = {"current_pose":current_pose,"img_number":img_number,"user_id": user_id,"out":out}
response = requests.post(self.url+"/inference_img/", data=data) #リクエスト送信
if response.status_code == 200:
image_data = response.content
image =(pickle.loads(image_data))#元の形式にpickle.loadsで復元
result = response.status_code
return result, imageアップスケールサーバ通信とクロップト
tkh_up_scale.pyのコードです。
import time
from time import sleep
import numpy as np
import cv2
from PIL import Image
import argparse
import pickle
import requests
#PIL形式の画像を動画として表示
def image_show(imge):
imge = np.array(imge)
imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
cv2.imshow("Loaded image",imge)
cv2.waitKey(1)
# ++++++++++++++ up scale ++++++++++++++++
def up_scale(url , img , scale=4):
#_, img_encoded = cv2.imencode('.jpg', img)
images_data = pickle.dumps(img, 5)
files = {"image": ("img.dat", images_data, "application/octet-stream")}
data = {"scale": scale}
response = requests.post(url, files=files,data=data)
all_data =response.content
up_data = (pickle.loads(all_data))#元の形式にpickle.loadsで復元
return up_data #形式はimg_mode指定の通り
def main():
print("TEST")
parser = argparse.ArgumentParser(description='Talking Head')
parser.add_argument('--filename','-i', default='000002.png', type=str)
parser.add_argument('--mode', default="full", type=str)#full,breastup,waistup,upperbody
parser.add_argument('--scale', default=4, type=int)#2,4,8
parser.add_argument("--host", type=str, default="0.0.0.0", help="サービスを提供するip アドレスを指定。")
parser.add_argument("--port", type=int, default=50008, help="サービスを提供するポートを指定。")
args = parser.parse_args()
host="0.0.0.0" # サーバーIPアドレス定義
port=8008 # サーバー待ち受けポート番号定義
url="http://" + host + ":" + str(port) + "/resr_upscal/"
mode = args.mode
scale= args.scale
print("upscale=",mode,"scale=",scale)
filename =args.filename
print("filename=",filename)
image = Image.open(filename)#image=512x512xαチャンネル
imge = np.array(image)
cv2_imge = cv2.cvtColor(imge, cv2.COLOR_RGBA2BGRA)
upscale_image = upscale(url ,cv2_imge, mode, scale)
cv2.imshow("Loaded image",upscale_image)
cv2.waitKey(1000)
def crop_image(image, top, left, height, width):
# 画像を指定された位置とサイズで切り出す
cropped_image = image[top:top+height, left:left+width]
return cropped_image
def upscale(url ,image, mode, scale):
if mode=="breastup":
cropped_image = crop_image(image, top=55, left=128, height=256, width=256)
elif mode=="waistup":
cropped_image = crop_image(image, top=55, left=128, height=290, width=256)
elif mode=="upperbody":
cropped_image = crop_image(image, top=55, left=143, height=336, width=229)
elif mode=="full":
cropped_image = image
else:
cropped_image = crop_image(image, top=mode[0], left=mode[1], height=mode[2], width=mode[3])
return up_scale(url , cropped_image , scale)
if __name__ == "__main__":
main()
まとめ
いずれ、付随するいくつかのプログラム(=背景削除、TalkingHeadテンプレート自動キャラクタアライメント)とサーバ側の各コードとともにGitHubへまとめて公開する予定です。