
最近、人工知能による自然言語処理が爆発的に進化しているのでまとめてみた。【後編】

1章から3章までは、主に汎用言語モデルについて紹介してきました。汎用言語モデルとは、要約、翻訳、文書分類、質問応答など様々な言語処理タスクに対応した汎用的な言語モデルで、BERT、T5、GPT-3、PaLMなどは、すべて汎用言語モデルです。これまで紹介した言語モデルの中では、MetaのNLLB-200だけが、翻訳機能に特化した単機能特化型言語モデルです。
4章以降では、主にこうした単機能特化型の言語モデルを紹介します。
4.テキストからの画像生成
最初に、単機能特化型の言語モデルの中でも、2021年にOpenAIが発表したDALL-E以降、次々と新しいモデルが発表されて盛り上がっているテキストからの画像生成について解説します。
① 4種類の画像生成モデル
まず、テキストからの画像生成だけにとどまらず、一般的に、ディープラーニングを利用して自動的に画像を生成する画像生成モデルとしては、大きく分けて以下の4種類のモデルがあります。
(1) 変分オートエンコーダー(VAE)
VAEは、入力データを特徴量に圧縮し、その特徴量をまた元のデータに戻すという仕組みのオートエンコーダーの一種で、この特徴量に確率分布を導入することにより、未知のデータを確率的に生成できるようにしたモデルです。
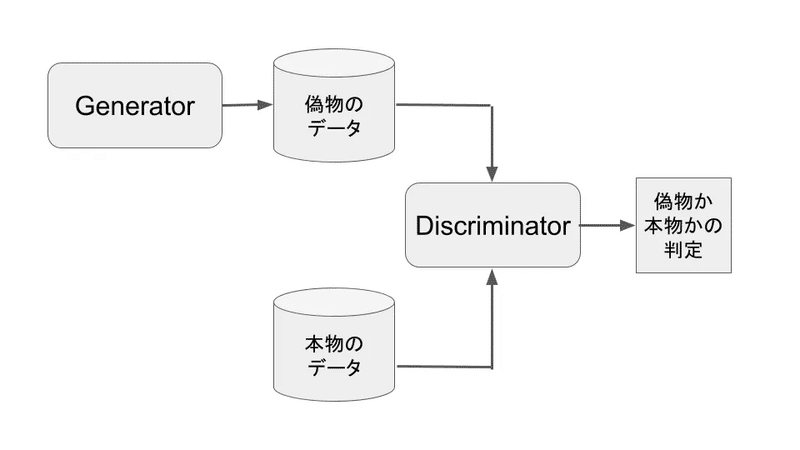
(2) 敵対的生成ネットワーク(GAN)
GANは、ジェネレーター(生成器)とディスクリミネーター(識別器)という2つのネットワークから構成されています。画像を生成する場合は、生成器が訓練データを基に本物そっくりな画像を出力し、識別器がその画像が本物か偽物かを判定します。生成器は識別器を欺こうと学習し、識別器はより正確に判定しようと学習します。GANは、このように2つのネットワークが相反する目的のために競い合うことで、生成する画像の精度を上げていくモデルです。
(3) フローベース生成モデル
フローベース生成モデルは、正規化フローという手法を活用し、確率分布を明示的にモデル化することによって、複雑な分布に基づいた新しいサンプルを生成できるようにしたモデルです。
(4) 拡散モデル
拡散モデルは、元データに徐々にノイズを加えて、完全なノイズ(ガウシアンノイズ)になるまでのプロセスを逆転し、ノイズを徐々に除去することによってデータを復元するプロセスをモデル化して、新しいデータの生成に利用するモデルです。
拡散モデルは、トレーニングの安定性と生成画像の品質の高さで、最近、注目を浴び、DALL-E 2やImagenなどの最新の画像生成モデルで採用されています。

下の矢印がノイズを除去していくリバースプロセス
② GANによる画像生成
DALL-Eの公開以前に、テキストから画像を生成する画像生成モデルとして最も使われていたのは、GANを利用したモデルです。
GANは、2014年にイアン・グッドフェロー氏らによって発表された深層生成モデルで、特に画像生成の分野で大きく発展し、本物の写真と区別がつかないような実在しない人物の顔画像を自動的に生成したことなどによって、世の中を驚かせました。
以下の画像は、「This person does not exist」というサイトで公開されているStyleGANによって生成された実在しない人物の顔画像の例です。(ページを更新すると、新しい画像に切り替わります。)

テキストから画像を生成するGANは沢山開発されていますので、その内のいくつかを紹介します。
(1) GAN-INT-CLS(2016年)
2016年に発表されたGAN-INT-CLS は、テキストから画像を生成するタスクに初めてGANを利用した画像生成モデルです。64×64ピクセルの画像を生成できましたが、出力される画像データは、入力するテキストデータと比べて圧倒的に情報量が多いため、生成器の学習能力に限界があって、高解像度の画像を生成できないという課題がありました。
(2) StackGAN(2017年)
2017年に発表されたStackGANは、GANを2段構成にすることにより、高解像度の画像生成を可能にしたモデルです。1段階目のGANで、テキストに合わせた64×64ピクセルの低解像度の画像を生成し、2段階目のGANでより高解像度の256×256ピクセルの画像を生成する仕組みになっています。
(3) AttnGAN(2017年)
Microsoftが2017年に発表したAttnGANは、重要な単語に着目して効率的な機械学習を行うAttention機構の仕組みを使用して、単語レベルの情報まで活用することにより、これまでよりもテキストの指示に忠実に従った画像を生成できるようにしたモデルです。

③ OpenAIのDALL-EからDALL-E 2まで
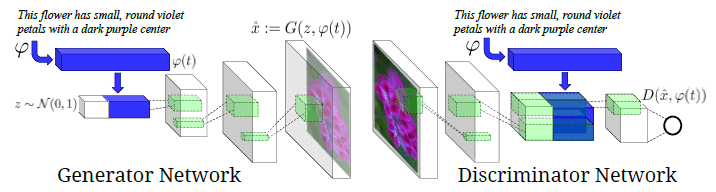
(1) DALL-E(2021年1月)
DALL-Eは、2021年1月にOpenAIが発表したテキストから画像を生成する画像生成モデルです。DALL-Eの画像生成の仕組みは以下の通りです。
【学習時】
学習用の256×256ピクセルの画像データをVQ-VAEで32×32の特徴量に圧縮し、画像を説明するキャプションのテキストデータとペアにして学習用のサンプルを作成します。そして、このサンプルを使って、GPT-3の120億パラメーターモデルで、画像データの特徴量とテキストデータを関連付ける機械学習を行います。
DALL-Eの学習には、2億5千万組のサンプルが用意されました。また、VQ-VAEは、特徴量を有限個のベクトルで表現するVAEの一種です。
【画像生成時】
入力されたテキストデータを学習済みのGPT-3に渡し、テキストデータの内容に合った画像データの特徴量を生成します。そして、VQ-VAEを使って、この特徴量を画像に復元します。
DALL-Eは、以下の例のように、テキスト内の複数の要素を組み合わせて、これまでにない画像を高精度に描き出すことができます。

(2) CLIP(2021年1月)
DALL-Eと同時にOpenAIが発表したCLIP は、ユーザーが自由に分類カテゴリーを設定して分類することができる画像分類モデルで、テキストに対する画像の類似度を出力します。CLIPは、ネット上のWebサイトから集めた4億ペアの画像とテキストで学習し、初見のデータセットでもうまく分類することができます。
CLIP は、非常に有能なマルチモーダルモデルとして、コンピュータービジョン関連の様々な分野のタスクに応用されました。また、2021年7月にライアン・モールトン氏が発表したCLIPとVQGANを組み合わせたテキストからの画像生成モデルは、非常に高品質な芸術的画像を数多く生み出したことで話題になりました。

(3) GLIDE(2021年12月)
2021年12月にOpenAIが開発したGLIDE(Guided Language-to-Image Diffusion for Generation and Editing)は、最大35億のパラメーターを持つ拡散モデルを採用した画像生成モデルで、DALL-Eよりも複雑なテキストの指示に忠実に従った高解像度の画像を生成できます。また、画像の一部をマスキングしてテキストで指示すると、その部分を指示通り修正した画像を生成することができます。

(4) DALL-E 2(2022年4月)
2022年4月にOpenAIは、CLIPと拡散モデルを組み合わせた画像生成モデルのDALL-E 2を発表しました。
DALL-E 2は、事前学習したモデルを利用して、入力されたテキストからCLIPの画像特徴量を生成し、この特徴量から拡散モデルを利用したデコーダーで高解像度の画像を生成する2段階モデルとなっています。
なお、CLIPの画像特徴量とは、CLIPで画像を分類する際に、画像データを特徴量に圧縮したもので、DALL-E 2の場合は、逆プロセスで、この画像特徴量から画像データを生成します。
この手法により、出力画像の多様性と高い解像度を両立しています。また、GLIDEと同様に、写真や画像の一部を指定して修正することもできます。

先月(2022年7月)から、DALL-E 2ベータ版が公開され、ウェイトリストに登録して、招待メールが届いたユーザーから順次利用できるようになりました。1クレジットで4枚の画像生成が可能で、初月は50クレジット、2か月目以降は毎月15クレジットが無料で付与され、それ以上利用する場合は有料となります。以下のページからウェイトリストに登録できますので、是非、試してみてください。
筆者の場合は、1週間弱で招待メールが届き、DALL-E 2を使えるようになりました。以下の画像が実際にDALL-E 2に作成させてみた画像です。プレゼンの表紙や挿絵に使える画像が簡単に作成できるので重宝しそうです。
ちなみに入力したワードは「Photo-style image of artificial intelligence at the moment of consciousness generation.」です。

④ GoogleのImagenとParti
(1) Imagen(2022年5月)
2022年5月にGoogle Brainチームは、テキストから画像を生成する画像生成モデルのImagenを発表しました。
Imagenは、MS COCO(Microsoft Common Objects in Context)などの画像データセットを用いたベンチマークテストで、DALL-E 2やその他の画像生成モデルよりも高い性能を示しました。

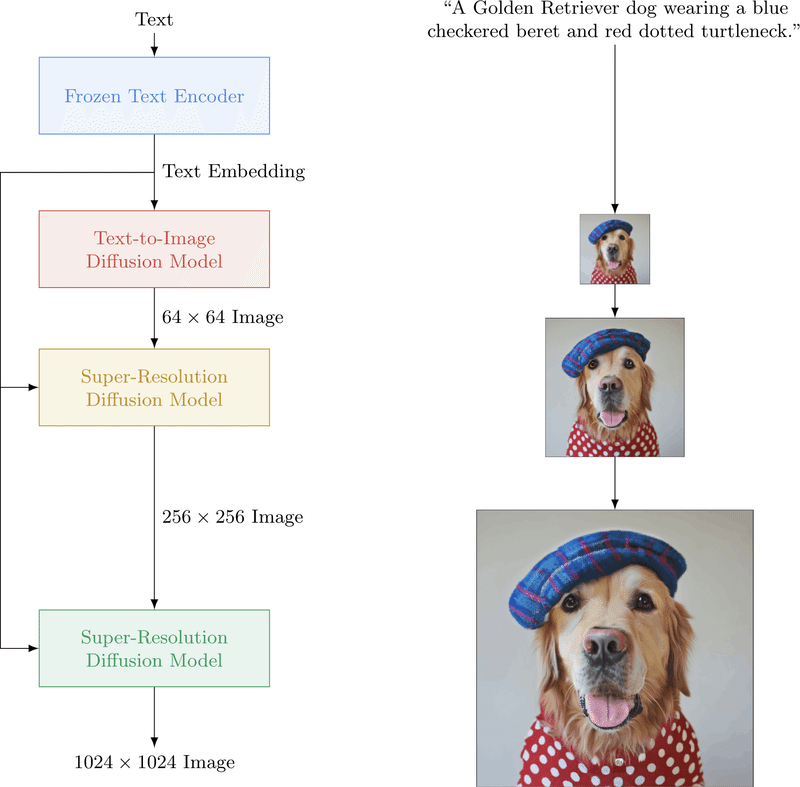
Imagenは、以下の3つのプロセスで画像を生成します。
学習済みの巨大言語モデル(今回の場合はT5)を利用したテキストエンコーダーで、入力したテキストを特徴量に変換します。
U-Net形式の拡散モデルを利用した「テキスト→画像」モデルで、1.で得られた特徴量から、64×64ピクセルの低解像度画像を生成します。
さらに、U-Net形式の拡散モデルを2回通すことで、64×64ピクセルの低解像度画像を1024×1024ピクセルの高解像度画像にアップサンプリングします。
Google Brainチームは、画像生成の性能向上のために、テキストを画像に変換する拡散モデルのサイズを大きくするよりも、言語モデルのパラメーター数を増やした方が効果的だと主張しています。
また、最終段階の解像度アップのための拡散モデル用に、従来のU-Netよりも効率的なEfficient U-Netを開発しました。
なお、Googleは、現時点では、Imagenは公共の使用には適していないので一般公開はしないと言っています。
生成した画像が本物の写真と区別が付かないほど自然で高画質なために、フェイクニュースやリベンジポルノに悪用される恐れがあり、また、選別していないWebサイトから収集したデータを利用しているため、差別的な主張や暴力的な表現などの倫理的に問題のあるデータが含まれている可能性があり、バイアスの問題が解決できていないためです。
Googleは、今後も社会的・文化的バイアスについて調査し、こうした問題に取り組んでいくと主張しています。
(2) Parti(2022年6月)
Imagenを発表した翌月(2022年6月)、Google研究所は、またもや新しい画像生成モデルを発表しました。新しい画像生成モデルは、Parti(Pathways Autoregressive Text-to-Image model)と言い、今度は拡散モデルではなく、自己回帰モデルを採用しています。
自己回帰モデルとは、ある時点におけるモデルの出力がそれ以前のモデルの出力に依存するような数理モデルで、GPT-3などの巨大言語モデルもTransformerを利用して、ある単語の次に出てくる単語を予測する自己回帰モデルとなっています。
また、Partiは、長くて複雑なテキストによる指示に対しても、忠実に従った画像を生成し、写真のようなリアルな画像を描き出すことができます。
Partiの200億パラメーターモデルは、MS COCOを用いたベンチマークテストで、DALL-E 2やImagenを超える性能を示し、ファインチューニングしたバージョンでは、さらに高い性能を達成しました。

Partiは、自己回帰モデルと画像トークナイザーの2段階のモデルで構成されています。
自己回帰モデルには、最大200億のパラメーターを持つTransformerモデルのエンコーダーとデコーダーの両方を使用します。この自己回帰モデルを大規模化することによって、画像品質が向上します。
画像トークナイザーにはViT-VQGANを使用して、学習用のサンプル画像を画像トークンに変換し、画像トークンから元の画像に復元する事前学習を行います。なお、ViT-VQGANは、③(2)で紹介したCLIPとVQGANを組み合わせた画像生成モデルのCLIP部分を画像認識モデルのVision Transformer(ViT)で置き換えたものです。
テキストから画像を生成するには、最初に、自己回帰モデルの事前学習済みのテキストエンコーダーを使って、入力されたテキストをテキストトークンのシーケンス(配列)に変換します。
次に、この自己回帰モデルで、テキストトークンのシーケンスを画像トークンのシーケンスに変換します。
最後に、画像トークナイザーを使って、画像トークンのシーケンスから、出力する画像を生成します。
DALL-E 2やImagenの出現により、これからの画像生成モデルは拡散モデルが主流になるかと思われたのですが、Partiは、シンプルな自己回帰モデルであるにもかかわらず、パラメーターを増やしてモデルを大規模化することによって、これらの拡散モデルを超える最高品質の画像生成を実現していることが特徴です。

5.マルチモーダルAI
マルチモーダルAIとは、文字情報(テキスト)以外に、画像、動画、音声など複数種類のデータを組み合わせて処理できるAIモデルのことです。ここまで紹介してきた汎用言語モデルの中では、GoogleのPathwaysと中国の悟道2.0及びM6がテキスト以外に画像、音声データも処理できるマルチモーダルAIです。また、第4章で紹介したテキストから画像を生成する画像生成モデルも、テキストと画像を扱うマルチモーダルAIです。
マルチモーダルAIが発展すると、テキストよりも情報量の多い画像や動画からの学習も可能となって、人工知能の学習がさらに進み、より汎用人工知能の実現に近づける可能性があります。
こうした観点から、汎用人工知能の開発を究極の目的とするGoogleのDeepMindチームは、特に積極的にマルチモーダルAIの開発に努めています。
① Flamingo(2022年4月)
2022年4月にDeepMindチームは、1つの機械学習モデルだけで、テキスト、画像、動画を同時に組み合わせて理解できるマルチモーダルAIのFlamingoを発表しました。
Flamingoは、DeepMindが2022年4月に発表した700億のパラメーターを持つ言語モデルのChinchillaを利用し、これに、画像や動画などのビジュアル学習要素を加えて事前学習を行い、800億のパラメーターを持つ新しい視覚言語モデルとして開発しました。
Flamingoは、質疑応答や文章生成などの一般的な自然言語処理タスク以外に、画像や動画とテキストを組み合わせたタスクを実行することができます。また、Flamingoに新しいタスクを行わせたいときは、タスクの例を数個、追加学習しただけで、そのタスクが実行できるようになります。
例えば、Flamingoに動物の画像と、その動物の名前と生息場所を説明する文章の組合せを数個学習させた上で、フラミンゴの画像を与えると、「これはフラミンゴです。カリブ海地域や南アメリカで見かけられます。」という文章を出力します。
Flamingoは、視覚的な質問応答や画像及び動画へのキャプション付与などの画像・動画理解のベンチマークテストの多くで、タスク例を数例示すだけの少数学習でも、数千倍のタスク固有のデータでファインチューニングされたモデルの性能を上回る結果を記録しています。

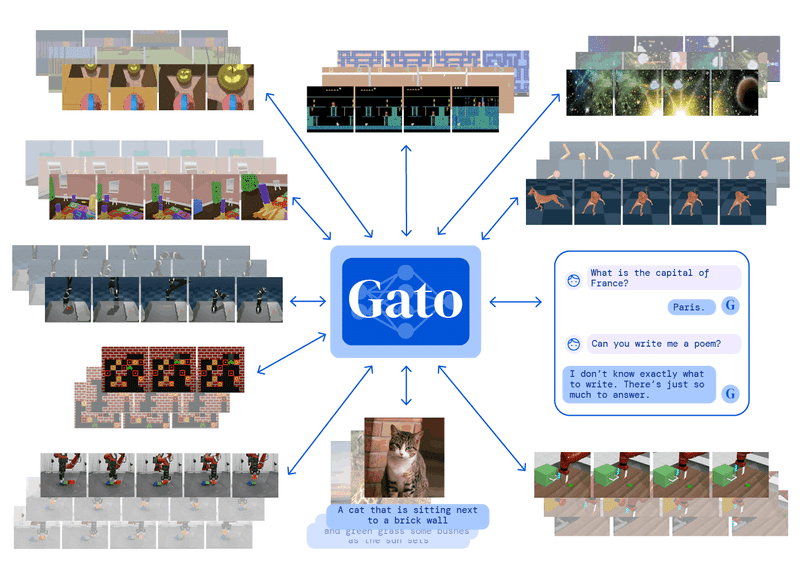
② Gato(2022年5月)
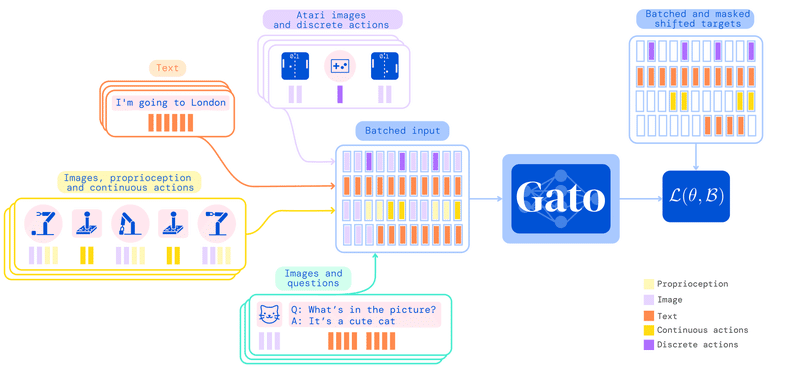
DeepMindチームの快進撃は続きます。2022年5月に同チームが発表したGatoは、テキストや画像などの出力だけでなく、様々なアクションまでも実行できる多機能なマルチモーダルAIです。
具体的にはGatoは、1つの機械学習モデルだけで、ビデオゲームをプレイしたり、画像にキャプションを付けたり、チャットをしたり、ブロックを積み上げるロボットアームを制御したりすることができ、全部で604種類のタスクを実行する能力を持っています。
Gatoは、PaLMやFlamingoなどの機械学習モデルと同様にTransformerモデルを採用しています。
具体的な仕組みとしては、まず、ビデオゲームの画像データ、チャットの文字列、ロボットアームの動きなどの異なるタスクのデータをそれぞれ、トークン(単語や運動ベクトルなどの最小の単位)に分割します。
そして、これらのトークンを区別せずに、1つのTransformerのニューラルネットワークで学習します。
最終的に、この学習成果を利用して、目標となるテキストやアクションなどの予測を行います。
Gatoによる個別のタスクの処理能力は、専用のプログラムより劣っているものも多いのですが、Gatoの開発は、汎用性が高い人工知能プログラムを作ることを目的としており、今後、コンピューティングパワーを増やしていけば、短所は補えると開発者は考えているようです。
6.自動プログラミング
GPT-3のような大規模言語モデルが台頭してくる以前の自動プログラミング技術の開発は、構文が簡単な独自のプログラミング言語を用いてコードを生成するものがほとんどで、PythonやC言語のような一般的なプログラミング言語を対象とすることは難しいとされてきました。
また、近年、プログラミングの知識があまりなくても、マウス操作などで用意された部品を組み合わせることによって簡単なアプリを開発できるローコード開発やノーコード開発と呼ばれるアプリ開発手法も見られるようになってきましたが、アプリ開発の自由度や拡張性に課題があると言われてきました。
① GPT-3によるコードの自動生成
2020年5月にOpenAIが発表した巨大言語モデルのGPT-3は、文章生成、翻訳、対話などの自然言語処理タスクを実行できますが、それ以外に、日常使う言葉(自然言語)からコードを自動生成することもできます。
具体的には、自然言語でのユーザーからの指示に応じて、PythonやC言語のような一般的なプログラミング言語でコードを自動生成することができます。また、ユーザーが途中まで書いたコードの続きをGPT-3に書かせたり、コードの内容をGPT-3に説明させたりすることも可能です。
自然言語からコードを自動生成できるGPT-3の出現は、これまでの自動プログラミングの歴史を大きく変えるものになりました。
② GitHub Copilot(2021年6月)
2021年6月に、Microsoft傘下のソフトウェア開発プラットフォームであるGitHubは、OpenAIと協力して、ユーザーが途中まで入力したコードの続きを自動で補完してくれるプログラミングサポートツールのGitHub Copilotを公開しました。
なお、当初は、テクニカルプレビュー版として無料で提供されていましたが、2022年6月からは正式サービスとして有料(例外として、学生などは無料)で提供されています。
GitHub Copilotは、MicrosoftのコードエディターのVSCodeやVisual Studio、JetBrainsの製品などに対応しています。
ユーザーが開発ツール上でコードを途中まで入力すると、そのコードの文脈やコーディング規約に沿ったコード候補をGitHub Copilotが提案します。また、ユーザーがコメントを入力した場合も同様に、コメントに合わせたコード候補を提案します。そして、提案を受け入れるかどうかは、ユーザーが選択できます。
対応しているプログラミング言語は数十種類に及び、特に、Python、JavaScript、Rubyなどの言語だと、精度の高い推測結果が得られるようです。
GitHubによると、コードファイルの内容のうち平均27%以上がGitHub Copilotによって生成されており、Pythonなどでは約40%に達していたそうです。
なお、GitHub Copilotは、GPT-3をベースとして、OpenAIが開発した自動コード生成システムのOpenAI Codexを利用しています。
③ OpenAI Codex(2021年8月)
2021年8月にOpenAIは、英語などの文章からコードを自動生成するAIシステムのOpenAI Codexのベータ版APIの提供を開始しました。
OpenAI Codexは、コードを自動補完するGitHub Copilotの基盤システムとなっており、Pythonなど10以上のプログラミング言語に対応しています。
OpenAI Codexでは、実行したい命令を普通の文章で入力すれば、対応するコードを自動生成してくれます。OpenAIでは、簡単なゲームの作成、データセットの分析、PythonからRubyへのプログラミング言語の変換、算数の問題の解答作成などのデモ動画を公開しています。
OpenAI Codexは、事前学習済みのGPT-3をベースとして、GitHubの公開リポジトリー(ファイル等の保存場所)から集めた数十億行のPythonコードなどで学習を行いました。なお、OpenAI Codexは、120億のパラメーターを持っています。
OpenAIの研究チームは、OpenAI Codexを評価するために、新たに164問のプログラミング問題から構成されるベンチマークテストのHumanEvalを開発しました。評価結果は、1回で正解したものが28.7%、100回解いた中に正解があった問題が77.5%となっています。
OpenAI Codexのベータ版のAPIを試してみるには、以下のOpenAIのサイトからWAITLISTに登録してください。招待メールが届き次第、無料で使用できます。
④ AlphaCode(2022年2月)
2022年2月にGoogleのDeepMindチームがコードを自動生成するAIシステムのAlphaCodeを開発し、競技プログラミングコンテストで上位54.3%以内に相当する成績を収めたと発表しました。
AlphaCodeは、OpenAIが開発したOpenAI Codexを改良して、競技プログラミングのコード作成が可能になるまで精度を向上させたモデルです。
AlphaCodeは、最大414億のパラメーターを持ち、これはOpenAI Codexの約4倍のサイズとなっています。
AlphaCodeの具体的な仕組みは以下の通りです。
最初に、Githubで公開されている大量のコードを利用して、AlphaCodeモデルに事前学習を行わせ、その後、競技プログラミングコンテストで実際に出題された問題などのデータセットでファインチューニングします。
ファインチューニング済みのAlphaCodeモデルによって、与えられた問題の解答となるコード候補を大量に作成し、それらの候補をフィルタリングして、有望なコードを選び出すことによって、精度の高いプログラミングを実現しています。
競技プログラミングの問題は難易度が高いので、正確な比較はできませんが、OpenAI Codexより、かなり精度が向上しているものと考えられます。
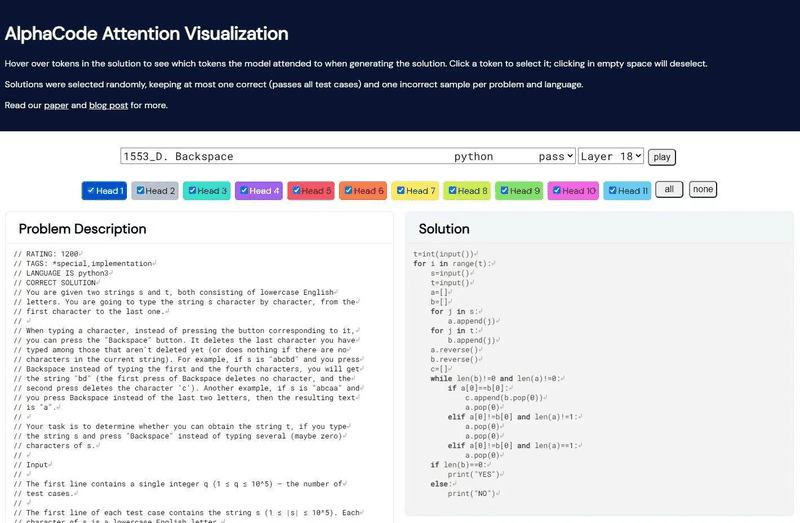
実際にAlphaCodeがプログラムを書いていく様子は、以下のDeepMindのサイトで見ることができます。プログラム作成を開始するには、ドロップダウンリストから問題を選んで、「play」ボタンを押してください。
〇 AlphaCode Attention Visualization
Microsoft系のOpenAI Codexは、実用的なプログラミングサポートツールのGitHub Copilotとして有料提供され、上手くマネタイズを実現しています。
これに対し、DeepMindのAlphaCodeは、それより高い性能を示しながら、汎用人工知能に向けた研究開発の一環として、あまりマネタイズを考えずに開発を進めているように見え、それぞれの企業・組織の特徴が表われているようです。
7.文章の要約
文章の要約には、大きく分けて2通りのアプローチがあります。抽出型要約と抽象型要約です。
抽出型要約は、文章内から最も文章の内容を代表できる重要な部分を抽出することによって要約文を生成する手法です。
抽象型要約は、人が要約文を作成するときのように、文章全体の意味を汲み取った(抽象化した)上で、適切な要約文を生成する手法です。
① 抽出型要約
エンコーダー抽出型要約のアルゴリズムは、まず文章中の部分ごとに重要か重要でないかという分類問題を解き、それから重要な部分だけを並べて要約文を生成するという仕組みになっています。
抽象型要約のメリットは、元の文章からそのまま抜き出しているので、文の内容や表現が破綻することが少ないことなどです。
一方、デメリットとしては、抽出されなかった部分の情報が全く入ってこないので、重要な情報がごっそり抜け落ちている場合があること、文章の最後に重要な結論が書かれていることが多いことなどから、文章の位置だけで抽出する部分を判断してしまいやすいという位置バイアスの問題などがあります。
抽出型要約のモデルとしては、事前学習済みのBERTを利用して分類問題タスクを処理するBERTベースのBERTSum、DiscoBERTや、グラフベースのTextRankなどがあります。
② 抽象型要約
抽象型要約は、文章全体の意味を捉えて要約文を生成するため、抽出型要約のように分類問題として解くことはできません。
抽象型要約のアプローチを取るには、入力文にない単語の情報を持っておいて、適切にそれらを出力に反映する必要があり、それを可能にしたのがエンコーダー・デコーダーモデルなどのニューラル言語モデルです。
エンコーダー・デコーダーモデルは、入力文を、その意味を表す特徴量に変換し、その特徴量を基に要約文を生成します。そのため、入力文に含まれていない情報も、学習データの中にあれば、要約文に反映させることができます。
抽象型要約は、うまくいけば、文章全体を上手にまとめた自然な要約文を生成できますが、入力文とあまり関係のない不要な情報が混入して、不正確な要約が出力される場合も多く、要約文の品質が不安定になりやすいという問題がありました。
しかし、近年では、表現力の優れた大規模言語モデルをトレーニングすることによって抽象型要約の品質を改善する手法が数多く提案され、自然な要約文を生成できるモデルが増えています。
抽象型要約のモデルとしては、T5、BART、PEGASUSなどがあり、基本的にすべてエンコーダー・デコーダーモデルとなっています。
③ BERTSum(2019年3月)
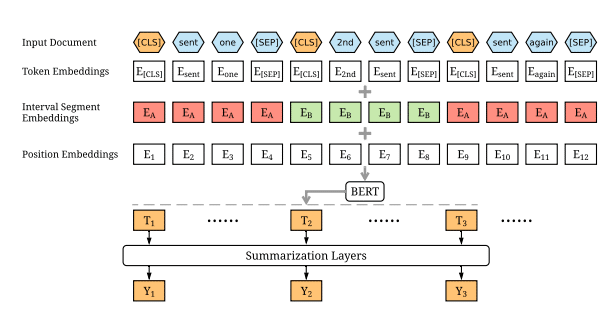
BERTSumは、BERTを事前学習モデルとして利用した初めての抽出型要約モデルとして2019年3月に発表されました。
BERTSumでは、事前学習済みのBERTを用いて、入力された文章を語句に分けて、文章内のそれぞれの語句の重要性を得点付けします。そして、BERTの出力した語句の重要性に関する情報を要約層に入力して要約文の生成を行います。要約層にはTransformer層を重ねたものが使われています。
なお、抽出型要約モデルのBERTSumは、BERTSumEXTとも呼ばれ、他に抽象型要約モデルのBERTSumABSもあります。
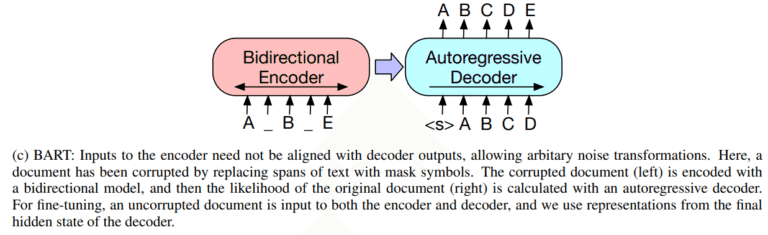
④ BART(2019年10月)
BART(Bidirectional Auto-Regressive Transformer)は、2019年10月にMeta(旧Facebook)が発表した、双方向エンコーダーのBERTとGPT-3のような自己回帰型デコーダーを組み合わせたSeq2Seq(Sequence-to-Sequence)型の汎用言語モデルで、抽象型要約以外に、機械翻訳、文章生成、文書分類など様々な自然言語処理タスクに対応することができます。
文章要約の場合は、入力された文章をBERTで特徴量に変換し、自己回帰型デコーダーがこの特徴量から要約文を生成します。
BARTは、特に文章の要約で高い性能を発揮したため、BARTの登場以降は、エンコーダー・デコーダーモデルの抽象型要約モデルが主流になりました。
⑤ PEGASUS(2019年12月)
2019年12月にGoogle Brainチームは、抽象型要約モデルのPEGASUS(Pre-tranning with Extracted Gap-sentenses for Abstractive Summarization)を発表しました。PEGASUSも、T5やBARTと同じようにTransformerベースのエンコーダー・デコーダーモデルです。
BERTなどの言語モデルでは、通常、文章中のマスクされた単語を予測するMLM(Masked Langage Model)というタスクが事前学習の際に用いられますが、PEGASUSの場合は、文章要約用に、文章単位の特徴を抽出できるようにするために、MLMに加えて、文章単位でマスクされた文章を予測するGSG(Gap Sentence Generation)というタスクが追加されているのが特徴です。
また、ファインチューニングに必要なデータ数を抑える工夫もされていて、比較的少ないデータの学習で他の手法と遜色ない精度の要約が可能です。
なお、PEGASUSの技術は既に、製品化されたGoogleドキュメントの自動要約機能に採用されています。

⑥ 日本語の文章要約サービス
日本語文章の要約については、無料で文章要約が試せるWebサイトは、いくつかありますが、文章要約モデルの公開は、あまり行われていないようです。以下に、日本語文章の要約を試せる主なWebサービスを挙げておきます。
三文タンテキ(バズグラフ) 文章とURLで入力でき、3文で要約します。
自動要約ツール(User Local) 3行、5行、10行の要約が選択でき、重要部分のハイライト表示もできます。
ELYZA DIGEST(ELYZA) 文章とURLで入力でき、3行で要約します。ELYZAは、東大の松尾研究室発のAIスタートアップです。

各社は、どのような言語モデルや技術を利用しているのかを公表していませんが、ELYZAは、BERT以降のアルゴリズムを活用した日本語特化の大規模言語AI「ELYZA Brain」を開発したとのことです。

8.その他の単機能特化型言語モデル
① MUM(検索アルゴリズム)
Googleは、2019年に自社のGoogle検索にBERTの技術を導入しましたが、2021年5月の開発者会議「Google I/O 2021」で、BERTの次のステップとなる新しい検索アルゴリズムのMUM(Multitask Unified Model)を発表しました。
MUMもBERTと同様にTransformerモデルを採用していますが、BERTの1,000倍強力だと言われています。また、MUMは、日本語を含む75の言語でトレーニングされています。
MUMの特徴は、(1) 自然言語での検索を強化、(2) 多言語に対応、(3) マルチモーダルに対応の3点です。
(1) 自然言語での検索を強化
MUMは、最近の自然言語処理技術の成果を活用して、ユーザーの方で検索ワードを工夫しなくても、普段の会話のような質問からユーザーの意図を汲み取って、求める答えを返してくれる親切な検索エンジンを目指しているようです。
例えば、「以前、アダムズ山に登ったことがあるけど、来年の秋に富士山に登りたい。前とは違ってどんな準備をすればいいの?」のような複雑で曖昧な質問に対し、MUMは質問の意図を理解して、「アダムズ山と富士山を比較すること」「登山の準備には、トレーニングや適切な装備の購入が必要であること」などを把握し、「アダムズ山と富士山はほぼ同じ標高」「富士山は秋に雨が降りやすい」「防水ジャケットが必要」といった質問者の必要とする情報を的確に提示することができます。
また、MUMは、ユーザーが必要とするかもしれない関連情報を併せて提示する機能も備えています。例えば、「Things to consider」は、知っておくとよい関連情報をまとめて提示する機能です。また、検索結果を絞り込み、より掘り下げた詳しい結果を表示する「Refine this search」機能や、検索ワードを拡張して、より幅広い検索結果へ導く「Broaden this search」機能なども実装されます。
(2) 多言語に対応
検索した内容に対する答えや情報が、必ずしも検索に使用した言語で書かれたWebサイトにあるとは限りません。そのような場合に、MUMは、他言語のサイトからも情報を集めて、ユーザーの求める情報に近い回答を提示することができます。
(3) マルチモーダルに対応
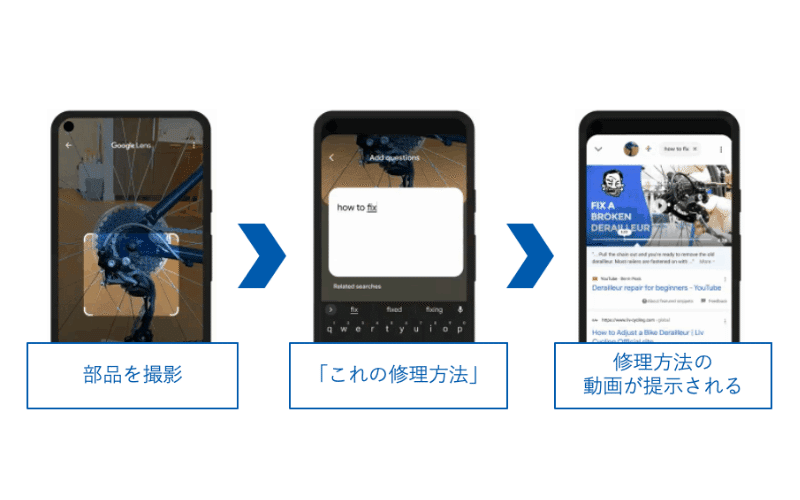
MUMは、テキストだけではなく、画像や動画と組み合わせたマルチモーダルな検索が可能です。
例えば、Googleレンズと連携し、壊れた自転車のパーツを撮影して、「修理方法」と検索することにより、修理に関するブログや記事、解説動画などを検索することができます。また、YouTubeなどの動画コンテンツの中に出てくる内容についても、MUMを導入して検索できるようにしていく予定とのことです。
キーワードを考えなくても、普段の言葉のままで検索できるようになれば、Google検索の使い方が変わってくると思います。その場合、入力する文字数が多くなるので、音声で検索できた方がよいですね。いずれにせよ、Google検索は益々便利なものになり、手放せないものとなりそうです。
② LaMDA(対話AI)
T5、GPT-3、PaLMなど大抵の汎用言語モデルは、対話タスクにも対応できます。また、チャットボットなど対話機能に特化した人工知能モデルの開発も以前より行われてきました。
しかし、2022年6月に「人工知能が意識や感情を持ったのか」と騒ぎになったGoogleの対話型人工知能LaMDAの公開された対話記録を見ると、これまでの対話システムとはレベルが違うように感じられます。まるで人工知能が人格を持っているかのように、会話内容及びその背景事情に対する深い理解、高度な判断力と洞察力、論理の一貫性などが感じ取れます。
LaMDA(Language Model for Dialogue Applications)は、2021年5月にGoogleが発表した、対話に特化した自然言語処理用の言語モデルです。
LaMDAは、Transformerモデルを採用しており、まず、最大1,370憶のパラメーターを使って、1兆5,600億語の公開対話データや公開Web文書などの大量のテキストで事前学習を行います。
次に、人手で注釈を付けた応答データで、応答案を作成する「生成器」と応答案の安全性と会話品質を評価する「分類器」をトレーニングするファインチューニングを行います。
ユーザーとの対話の際のLaMDAの処理の流れは以下の通りです。
生成器が直前のユーザーの発言に対応した複数の応答案を作成する。
すべての応答案を分類器で評価し、安全性スコアと会話品質スコアを算出する。安全性とは、暴力的な表現や差別的な表現などの有害な結果を排除することであり、会話品質は、 Sensibleness(思慮深さ、常識があること)、 Specificity(具体的であること)、 Interestingness(興味深さ)の3点で評価する。
最初に安全性スコアの低い応答案を除外し、残った応答案を会話品質スコアによって順位付けする。
最も順位の高い応答案を最終的な応答として出力する。
さらに、LaMDAの分類器を使用して、安全性の低い学習データや会話品質の低い学習データをフィルタリングして、高品質で安全な応答作成の精度を高めています。
2022年5月にも、Googleは、LaMDAの新しいバージョンであるLaMDA 2を発表し、近日中にLaMDA 2を搭載したスマートホン用のアプリのAI Test Kitchenを提供すると発表しました。
AI Test Kitchenには、ユーザーが入力した架空の場所で起こりそうな出来事を答える機能、To Doリストを自動作成する機能、特定の話題について質問応答する機能などが含まれています。
Googleは、人工知能のバイアスの問題についてかなり慎重で、現在のところ、自由に対話可能なLaMDAを公開していませんが、2022年6月にGoogleのエンジニアによって公表された対話記録の実力が本物かどうか、早く確かめてみたいものです。
それが本物であれば、人工知能の開発の歴史を大きく変えるような重要な技術となるでしょう。
③ Minerva(数学や科学の問題を解くAI)
2022年6月にGoogleは、同社が開発した最新の巨大言語モデルのPaLMをベースに開発したMinervaが数学や科学の問題を解く正答率で、人工知能による過去最高の成績を達成したと発表しました。
Minervaは、数学や科学の問題のような定量的推論の問題が解ける人工知能です。定量的推論は、人工知能が人間レベルの性能にはるかに及ばない分野の一つです。
数学や科学の問題を解くには、自然言語と数学的表記を用いて問題を正しく解析すること、関連する数式や定数を思い出すこと、数値計算や記号操作を使って段階的に解いていくことなど、様々なスキルを組み合わせる必要があるからです。
これまで、人工知能によるMATH(米国の高校レベルの数学問題を集めたデータセット)正答率の最高成績(SOTA)は6.9%にすぎず、5400億のパラメーターを持つPaLMでも8.8%でした。これに対して、MinervaのMATH正答率は50.3%に達し、過去のSOTAを大幅に上回りました。
また、MinervaのGSM8k(小学生の算数問題のデータセット)正答率は78.5%(SOTAは74.4%)で、MMLU-STEM(高校・大学レベルの工学、化学、数学、物理学等の問題のデータセット)正答率は75.0%(SOTAは54.9%)と、いずれもこれまでのSOTAを上回っています。

Minervaの機械学習モデルの構造自体はPaLMと同じですが、それに加えて、論文公開サイトのarXivから入手した118ギガバイトの科学論文とLaTeX形式で記述された数式などを含むWebページで学習することによって、数式の理解や定量的推論の能力を向上させています。
PaLMのような巨大言語モデルでは、プロンプト(最初に入力する文字列)に、いくつかの例題と回答例を入力するだけで、言語モデルが新しいタスクに対応することができます。さらに、この回答例を入力する際に、最終的な答えを出すまでの解き方も一緒に入力すると、言語モデルは、解き方も含めて答えを出力するようになります。言語モデルの推論能力を強化するこのような手法を「思考の連鎖」(chain of thought)や「スクラッチパッドプロンプティング」と呼びます。
PaLMベースであるMinervaに定量的推論の問題を解かせるに当たっても、この「思考の連鎖」の手法が使われています。Minervaのプロンプトに例題と回答例を入力する際に、答えを出すまでの詳細な手順を一緒に入力することにより、複雑な問題も解けるようになりました。

Minervaは、同じ問題を何度も解いて、複数の解答を作成し、異なる解答が出てきたときは、最も多い解答を最終解答とする多数決方式で最終解答を決めており、これもMinervaが正答率を上げるテクニックの一つとなっています。
Minervaに関しては、学習したパターンに従って、確率的に数式の混じった文章を生成しているだけで、数学の問題を本当に理解して解いている訳ではないという批判もありますが、また一つ、人工知能にはできないとされてきたハードルを乗り越えようとしているのは確かです。
こうして、人工知能が次々とハードルを乗り越えていけば、いずれ近いうちに、人工知能は人間の能力を全面的に超え、シンギュラリティに到達するのでしょうか。
【参考図書】
3冊とも今年出版されたPreferred Networks共同創業者の岡野原大輔氏の著作です。どれも、最近、爆発的に進化しているAI技術の基礎から最新動向までが網羅的に学べる本だと思います。
この記事が気に入ったらサポートをしてみませんか?