
最近、人工知能による自然言語処理が爆発的に進化しているのでまとめてみた。【中編】

2.自然言語処理の主要プレイヤー
① Google
現在、自然言語処理の世界を牽引しているリーダーは、TransformerとBERTを開発したGoogleです。
Googleグループには、世界トップクラスの人工知能研究チームが2つあります。一つは、Google Brainチームで、もう一つは、英国のデミス・ハサビス氏が代表を務める人工知能開発ベンチャーを買収してできたDeepMindチームです。
Google Brainは、Googleエンジニアのジェフ・ディーン博士やスタンフォード大学のアンドリュー・ウン教授らが中心となって設立した研究チームで、現在は、Google研究所の傘下に入っています。また、ディープラーニングの父と呼ばれるジェフリー・ヒントン教授も現在、同チームを率いるメンバーに参加しています。
Google Brainは、Transformerなどの自然言語処理技術のほか、機械学習用のソフトウェアライブラリーであるTensorFlow、機械学習を利用した癌発見支援システム、ロボット用の機械学習アルゴリズムなども開発しています。

DeepMindは、2010年にデミス・ハサビス氏が中心となって、ロンドンで設立した人工知能開発ベンチャーで、2014年にGoogleに買収され、2015年にGoogleの親会社であるAlphabetの完全子会社となりました。同社は、2016年にプロの囲碁棋士に勝利した囲碁AIのAlphaGoを開発したことで有名です。
印象としては、DeepMindの方が汎用的な人工知能の実現を目指して、より将来的な研究開発を行っているように見えますが、DNAのアミノ酸配列情報からタンパク質の立体構造を予測する人工知能の「AlphaFold 2」を実用化するなど、DeepMindにも実用化を果たした研究があります。
また、最近、DeepMindは、汎用的人工知能の開発の観点から言語モデルの研究にも力を入れているようで、Google Brainと研究分野が重なったり、共同研究を行ったりもしています。

② OpenAI
Googleの対抗馬として、GPT-3などの大規模言語モデルやDALL-EのようなAIアプリケーションなどの最先端の人工知能研究開発の成果を次々と発表しているのがOpenAIです。
OpenAIは、2015年にイーロン・マスク氏を始めとするIT投資家によって設立された「汎用人工知能が人類全体に利益をもたらすこと」を使命とした非営利団体です。
しかし、2019年に子会社として営利企業のOpenAI LPを創設し、Microsoftからの出資を受け入れて、同社とGPT-3の独占ライセンス契約を結ぶなど、同社との結びつきを深めています。また、マスク氏は2018年に取締役を辞任しています。

なお、Microsoft自体も、BERTの改良版であるMT-DNNや大規模言語モデルのMT-NLGを開発するなど、従来から人工知能による自然言語処理に積極的に取り組んできました。
今後は、Microsoftの人工知能開発戦略において、OpenAIが重要な役割を果たすことになりそうです。
③ Meta
昨年(2021年)10月、メタバース企業への移行を目指して改名したMeta(旧Facebook)も、巨大言語モデルのOPT-175BやNLLB-200を開発するなど、自然言語処理を含む人工知能技術の開発に積極的に取り組んでいます。
また、TensorFlowとシェアを二分する機械学習用のソフトウェアライブラリーのPyTorchも、Metaが開発元になっています。
なお、2013年にMetaは、ディープラーニング研究の第一人者であるニューヨーク大学のヤン・ルカン教授を招いて、人工知能研究所のFAIR(現Fundamental AI Research)を立ち上げました。その際、ルカン教授は、開発したソフトウェアをオープンソースとして共有し、誰でも使えるようにすることを条件として求めたそうです。

④ その他
Google、Microsoft、Metaなどの主要プレイヤーは、大学や各種研究機関の研究者と連携して研究開発を進めています。
自然言語処理分野で有名な研究機関としては、Microsoftの共同創設者であるポール・アレン氏が設立したアレン人工知能研究所などがあります。同研究所は、言語モデルのELMoを開発したことで有名です。
米国以外では、中国の取組が目立っており、BERTを超える性能を発揮した言語モデルのERNIEを開発したBaiduを始め、Alibaba、Tencent、HUAWEI、ByteDanceなども積極的にこの分野の人工知能開発に取り組んでいます。
また、韓国ネット企業のNAVERも、日本のLINEと協力して、大規模言語モデルのHyperCLOVAの開発を行っています。

3.大規模言語モデルの開発
① 言語モデルBERTの改良
(1) Googleを中心としたBERTの改良モデル
2018年10月にGoogleがBERTを発表した後、BERTの改良版が立て続けに発表されました。
2019年2月にMicrosoftは、自社で開発していた言語モデルとBERTの技術を組み合わせた「MT-DNN」を発表しました。MT-DNNは、11種類の自然言語処理タスクのうち9つでBERTを上回る成績を出しました。
これに対し、2019年6月にGoogleがTransformer-XLを導入して、BERTより長い文章を扱えるようにした「XLNet」を発表し、同年7月には、Meta(旧Facebook)がハイパーパラメーターの調整や学習用データ量の増加によって、BERTの精度を大幅に上回る「RoBERTa」を発表しました。また、同年9月には、GoogleがBERTを軽量化した「ALBERT」を発表しました。
さらに、2019年10月にGoogleは、Transformerのエンコーダーとデコーダーの両方を使用し、入力と出力の両方を文字情報に統一して転移学習を行う「T5」(Text-to-Text Transfer Transformer)を発表しました。「転移学習」とは、機械学習において、ある領域の学習済みモデルを別の領域に転用する仕組みです。
T5は、質問解答、要約、翻訳などの様々な自然言語処理タスクに一つのモデルだけで対応することが可能であり、多くのベンチマークテストで最高性能(SOTA)を達成しました。
また、T5は、未知の質問に対して、事前学習時にインプットされたデータを基に、そのデータを考慮に入れた入れた回答を返すという革新的な機能を備えています。英語ですが、実際に「T5 trivia」というサイトでT5とクイズ対決をすることができます。

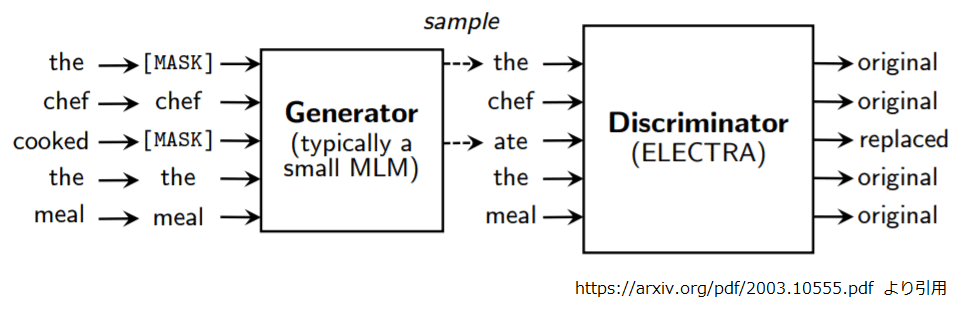
その後、2020年5月にGoogleは、GAN(敵対的生成ネットワーク)の手法を取り入れてBERTの事前学習手法を改良し、より少ない学習データで効率的な事前学習ができるようにした「ELECTRA」を発表しました。
(2) 中国版BERTのERNIE
中国では、2019年3月にBaiduが、BERTが中国語を扱う上での問題点を解決した「ERNIE」を発表しました。
その問題点とは、中国語が英語のように、単語ごとにスペースで区切られていないことです。これを、言語モデルがマスキングによる穴埋め問題(MLM:Masked Language Model)を学習する際に、単語として連続する文字列をすべてマスキングするように変更することによって、解決しました。
単語がスペースで区切られていないのは日本語も同じなので、日本語を扱う上でも、とても参考になるはずです。

Baiduは、2019年7月に「ERNIE 2.0」、2021年7月に「ERNIE 3.0」を発表しており、ERNIE 3.0は、自然言語処理の標準ベンチマークであるGLUEを更に高難度にしたSuperGLUEでSOTAを達成し、人間の平均スコアも上回りました。
また、ERNIE 3.0は、文字情報のみで学習する他の言語モデルと異なり、様々な知識を体系的に連結してグラフ構造にした知識グラフデータも学習データに加えることによって、非常に一貫性のある応答を出力することができると説明されています。

② Transformerの改良
(1) Efficient Transformers
Transformerの計算量は、入力する文字列などのシーケンスの長さの2乗に比例しており、シーケンスが長いと、機械学習時のコストやメモリー容量に大きな負担がかかります。そのため、Transformerには、あまり長い文章を扱うことができないという弱点がありました。
これを解決するために、アルゴリズムを改善して、計算効率やメモリー効率を高めた数多くのTransformerモデルの改良版(Efficient Transformers)が提案されています。
2019年1月にGoogleは、一つの文章を複数のセグメントに分けることによって、より長い文章を扱えるようにした「Transformer-XL」を開発し、自然言語処理モデルのXLNetにも、このモデルを利用しました。
その後、Attentionを向ける先を限定して、長いシーケンスを扱えるようにした「Sparse Transformer」(OpenAI)、100万ワードの文章をわずか16GBのメモリーで処理できるようにメモリー効率を改善し、小説一冊を丸ごと読み込めるようにした「Reformer」(Google)、重要な単語から重要な単語へのみ注意を向けるようにAttentionを工夫した「Longformer」(アレン人工知能研究所)など次々と新しいEfficient Transformersが誕生しました。
さらに、2020年7月にGoogleは、これまでの最大8倍の1セグメント当たり4,096項目のシーケンス長を処理できる「BigBird」を発表しています。

多すぎて説明しきれませんが、Efficient Transformersとして提案されたものとしては、他にMemory Compressed Transformer、Image Transformer、Set Transformer、Axial Transformer、ETC、Routing Transformer、Sinkhorn Transformer、Linformer、Synthesizer、Performer、Linear Transformer、Compressive Transformerなどがあります。
また、2021年6月にGoogleのDeepMindは、Transformerの構造を利用して、文字情報以外に音声や画像など様々な種類のデータを処理できるマルチモーダルモデルの「Perceiver」を開発しました。同モデルは、画像分類や音声認識のタスクで、10万個以上のベクトルを持つ入力シーケンスを扱うことができるそうです。
(2) Attentionは不要?
このように、自然言語処理の世界では、ほぼ天下を統一した感じがするTransformerですが、画像認識モデルでは、Transformerを導入した「Vision Transformer(ViT)」が最高性能(SOTA)を達成した後に新しい動きが始まっています。

2021年3月に、Googleの研究者がTransformerのAttention機構を多層パーセプトロン(MLP)に置き換えたシンプルな構造の「MLP-Mixer」でも、最高性能に匹敵する画像分類性能を発揮できることを示し、さらに、同年11月には、Attention機構を入力値の平均値を出力するだけのプーリング層に置き換えた「PoolFormer」でも十分な性能を発揮できることが分かりました。
このことから、画像認識AIに重要なのはTransformerの構造(アーキテクチャー)自体であって、Attentionでなくても、情報共有の仕組みさえあればよいという結論に至り、Transformerの構造を一般化した「MetaFormer」というコンセプトが提案されて、研究が進んでいます。
また、自然言語処理の分野でも、AttentionをMLPに置き換えても高い性能を維持できるという実験結果が出てきました。このような新しい動きが波及して、今後、自然言語処理の分野でも、Transformerの見直しが行われるのでしょうか。

③ GPTシリーズ
(1) GPT
「GPT」は「Generative Pre-trained Transformer」の略で、2018年6月にOPenAIが発表した自然言語処理モデルです。GPTは、1億1,700万のパラメーターを持ち、Transformerのデコーダーのみを使ったTransformerブロックを12層重ねて使用しています。
GPTは、特定のタスクに特化した教師あり学習は行わず、大量の学習データで大規模な言語モデルを事前学習させることにより、個別タスクの実行前に与えられるタスクの例が少なくても、高い精度が出せるようにした汎用的な言語モデルで、文章分類や質問応答などの様々な自然言語処理タスクに対応できます。
GPTは、各種の自然言語処理タスクで高い精度を達成し、特に文章生成では、非常に良い結果を残しました。

(2) GPT-2
2019年2月にOpenAIは、15億4,200万のパラメーターを持つ「GPT-2」を発表しました。モデルの構造は、GPTとほぼ同じですが、Transformerブロックを最大48層重ねて使用しており、ネット上で自動収集した40ギガバイトのWeb文書で事前学習を行っています。
GPT-2は、文章の翻訳、質問応答、要約などに対応し、与えられた文章に続いて自動的に文章を作成することもできます。
長い文章を作成する場合は、同じ言葉を反復したり、無意味な文章になったりしますが、SNSの文章のような短い文章であれば、人間が書いたものと区別がつかないレベルの文章を作成することができます。
OpenAIは、悪用を危惧して、発表当初、GPT-2のソースコードの公開を拒否し、その後も、パラメーターの数を減らしたモデルなどを公開してきましたが、2019年11月には、15億4,200万のパラメーターを持つフルモデル版を公開しました。

(3) GPT-3
2020年5月にOpenAIは、GPT-2の100倍以上の1,750億のパラメーターを持つ「GPT-3」を発表しました。モデルの構造はGPT-2とほぼ同じですが、Transformerブロックを最大96層重ねて使用しており、GPT-2の1,100倍以上の約45テラバイトの大量のテキストデータで事前学習しています。
GPT-3の特徴は、ファインチューニング無しでも、高精度な自然言語処理が行えることです。通常の言語モデルでは、事前学習したモデルに、特定のタスクに合わせた専門的なデータを使用した追加学習を行わせることによって精度を向上させていますが、GPT-3の場合は、このファインチューニングを行わなくても、かなりよい精度を発揮できます。
GPT-3は、自然言語処理のタスクの内容や例を示すだけで、それに応じたタスクを実行することができます。GPT-3では、その利用方法として、Zero-Shot、One-Shot、Few-Shotの3種類の方法を挙げています。
Zero-Shotとは、タスクの内容を示すだけで、タスクを実行させる方法で、「英訳せよ」と「犬==>」と入力すると、「dog」と回答します。
One-Shotの場合は、タスクの一例を示して、「英訳せよ」「犬==>dog」「猫==>」と入力すると、「cat」と回答します。
Few-Shotの場合は、タスクの例が少し増えて、「英訳せよ」「犬==>dog」「猫==>cat」「猿==>monkey」「鳥==>」と入力すると、「bird」と回答します。
なお、Few-Shotを設定しただけで、ファインチューニングを行ったモデルの精度を上回ったという事例も報告されています。

ファインチューニングを行ったモデルの最高性能(SOTA)を上回っています。
GPT-3は、特に文章生成の精度が高く、人間によって書かれた文章と見分けのつかないような自然な文章を生成することができます。
この点に関して、GPT-3を使って作成された偽ブログ記事がほとんどの人に気づかれずにニュースサイトで1位になったという事例やGPT-3を使用したチャットボットが約1週間誰にも気づかれずに掲示板で会話をし続けたという事例も報告されています。
偽ブログやフェイクニュースを簡単に作成できるという危険性は、GPT-2のときからささやかれていたことですが、GPT-3になって、更にそのレベルが上がっているようです。
現在、GPT-3は、様々なアプリケーションで利用され始めています。
例えば、2021年8月にOpenAIは、GPT-3を利用して、人々が通常話す自然言語からソースコードを自動生成するAIシステムの「OpenAI Codex」のベータ版の公開を開始しました。
また、OpenAIによると、2021年3月時点で、300以上のGPT-3のAPIを利用したアプリケーションが開発され、1日平均で45億語を生成しているとのことです。
◆GPT-3の試し方
GPT-3は、無料で簡単に使ってみることができますので、興味のある方は、是非試してみてください。
以前は、ウェイティングリストに登録申請して、承認メールが届くまで数か月待つ場合もあったのですが、現在は、アカウント登録してすぐに使用できます。
先ずは、以下のOpenAIのサイトの最初の「GET STARTED」をクリックして、アカウントを作成します。
そこで登録したメールアドレス宛に認証メールが届きますので、クリックして認証してください。その後、必要事項を入力し、登録した携帯電話番号にショートメッセージで届く認証コードを入力すれば、アカウント登録完了です。

ログイン後、「Playground」で簡単に、GPT-3を試してみることができます。左上の「Playground」をクリックし、テキストエリアに文字列を入力して、左下の「Submit」をクリックするだけで、GPT-3が様々な回答を返してくれます。
短い文章や文の書き出しを入力すると、GPT-3が続きの文章を作成してくれます。日本語でも対応してくれますが、内容が変だったり、途中で英語に変わるなどのおかしな動きをしたりすることが多いので、英語で入力した方がよいでしょう。
ちなみに、日本語で、「吾輩は猫である。名前はまだない。」と入力したときは、夏目漱石の「吾輩は猫である」の小説の続きを正確に返してきました。「ハリーポッターと賢者の石」の書き出しを英語で入力したときも同様でした。
それ以外にも、翻訳、要約、GPT-3との対話、映画タイトルを絵文字で表現するなど、様々な使い方ができますので、ログイン後の画面の赤いエリア「Examples」をクリックして、色々な使い方の例を調べてみてください。49種類の「Prompt」(GPT-3にタスクを教えるために最初に入力する文字列)のサンプルが載っており、サンプルが載っているページの右上の「Open in Playground」をクリックすると、最初からPromptのサンプルが記入された状態でPlaygroundを使用することができます。

なお、2022年7月時点では、アカウント登録時に有効期限約3か月の18ドル分の無料クレジットがもらえますが、使用期限や使用上限を超えて利用する場合には有料になります。これまでの使用料や使用期限は、右上のアカウント名のプルダウンメニューから「Manage account」を選択して見ることができます。お試し程度であれば、無料クレジット分だけで十分でしょう。
また、プログラムでGPT-3のAPIを使用したいなど、もっとしっかりGPT-3を利用したい人は、プルダウンメニューの「View API keys」からAPI keyを取得してください。
(4) InstructGPT
2022年1月にOpenAIは、GPT-3よりもユーザーの意図に従った対応を行い、加害性も少ない言語モデル「InstructGPT」を発表しました。
GPT-3は、人間が書いたような自然な文章を作成できることで話題を呼びましたが、学習に使用したWebデータには、差別的なものや暴力的なものも含まれているため、一般的に望ましくない結果が出力されてしまうことがあります。
InstructGPTは、ラベル付けしたデータセットで、ラベルを付けた人が好む出力を予測するトレーニングを行うことにより、こうした問題を解消しました。その結果、InstructGPTは、GPT-3と比較して、間違った答えを真似することが少なくなり、加害性も少なくなっているということです。

(5) GPT-4
GPTシリーズの次世代バージョンである「GPT-4」が今年(2022年)の夏以降にリリースされると言われています。
また、GPT-4は、これまでで最高性能の汎用的な言語モデルとなり、GPT-3までと同様にテキストのみを処理するユニモーダルモデルのままであって、InstructGPTのように人間の評価を組み込んだ、より倫理的なAIになるだろうと予想されています。
④ 大規模言語モデルの開発競争
(1) GoogleのSwitch Transformerなど
2020年5月に、1,750億のパラメーターを持つOpenAIのGPT-3が登場して以降、言語モデルの大規模化が続いています。
2020年6月には、Googleが6,000億のパラメーターを持つ「GShard」を発表しました。
さらに、Googleは、2021年1月に、最大1兆6,000億のパラメーターを持つ「Switch Transformer」をオープンソース化しました。Switch Transformerは、MoE(Mixture-of-Experts)という仕組みを導入することにより、パラメーター数を大幅に増やしつつ計算量を抑制し、自然言語処理のベンチマークテストでT5を超える性能を出しながら、学習時間を大幅に短縮することに成功しました。

(2) 中国の悟道2.0とM6
これに対抗して、2021年6月に北京智源人工知能研究院が1兆7,500億のパラメーターを持つ「悟道2.0」(WuDao2.0)を発表しました。
なお、北京智源人工知能研究院は、2018年に北京市が中心となって、北京大学、精華大学、中国科学院、Baidu、ByteDanceなどの人工知能開発を得意とする大学、研究機関及び民間企業の人材を集めて設立された研究センターです。
悟道2.0は、画像や音声など様々な入力情報を利用するマルチモーダルAIで、顔認識、エッセイや詩歌の創作、文章に基づく画像作成などを行うことができます。また、世界が公認するAI能力ランキングの9項目でトップの地位を獲得したとのことです。

また、2021年11月に中国のAlibaba DAMO Academy(達磨院、Alibabaの研究開発部門)が世界最大の10兆のパラメーターを持つ「M6」(MultiModality-to-MultiModality Multitask Mega-transformer)を発表しました。
M6は、悟道2.0と同じように、作画、文章作成、質疑応答などができるマルチモーダルAIで、2021年1月に100億のパラメーターを持つモデルが開発され、段々とパラメーター数を増やしていって、2021年5月には1兆に達していました。

(3) MicrosoftとNVIDIAのMT-NLG
2021年10月にMicrosoftは、NVIDIAと共同で、5300億のパラメーターを持つ「MT-NLG」(Megatron-Turing Natural Language Generation)を開発しました。GPT-3の登場以前に、Microsoftは172億のパラメーターを持つ「Turing NLG」、NVIDIAは83億のパラメーターを持つ「Megatron-LM」という言語モデルを発表しており、MT-NLGは、これらの言語モデルの後継モデルということになります。
MT-NLGは、MicrosoftのDeepSpeedとNVIDIAのMEGATRON-LMという両社の最先端の機械学習ソフトウェア技術を利用し、Microsoft Azure NDv4 やNVIDIA Seleneなどのスーパーコンピューターを使ってトレーニングを行いました。まさに両社の総力を挙げた大規模言語モデルとなっています。

(3) DeepMindのChinchillaなど
2021年12月にGoogleのDeepMindは、2800億のパラメーターを持つ「Gopher」を発表しました。Gopherは、MassiveTextと呼ばれる10.5テラバイトの英語テキストデータを、テキスト品質や重複排除などの観点からフィルタリングしてできたデータセットを使ってトレーニングを行い、124種類の評価タスクの内の100のタスクで現在の最高記録を凌駕しました。
さらに、2022年4月にDeepMindは、700億のパラメーターを持つ新しい言語モデルの「Chinchilla」を発表しました。Chinchillaは、言語モデルのパラメーターのサイズとトレーニングに使用されるデータ量のバランスを見直すことによって、幅広い個別評価タスクで、Chinchillaよりも多くのパラメーターを持つGPT-3、Gopher及びMT-NLGの性能を上回りました。DeepMindは、このようにして、言語モデルの性能を向上させるのが大規模化だけではないことを証明しました。

(4) GoogleのPaLM
2022年4月にGoogleは、自然言語処理に関する複数種類のタスクを処理できる5,400億のパラメーターを持つ「PaLM」(Pathways Language Model)を発表しました。
「Pathways」は、1つの機械学習モデルで最大数百万種類のタスクに対応できるという万能の人工知能で、Googleは今回、Pathwaysシステムを使って、自然言語による質問応答や文章生成などができる言語モデルのPaLMを実装しました。
PaLMは、Webページ、書籍、ニュース記事などから収集した7800億ワードの多言語(ただし、約78%が英語)の文章を使って、AI専用チップのTPU v4をこれまでで最多の6144個搭載した巨大スーパーコンピューターでトレーニングを行いました。
また、プロンプト(AIにタスクを教えるために最初に入力する文字列)に、「思考の連鎖」に関する例文を入力するという手法によって、ディープラーニング方式の言語モデルの弱点と言われる論理的推論を強化することができます。
PaLMは、一つのモデルで質問応答や翻訳、ソースコードの生成と修正、ジョークの解説といった様々なタスクを処理することができ、英語以外の多言語によるタスクにも対応可能です。
PaLMは、29の自然言語処理タスクのうち、28のタスクでSOTA(最高性能)を達成し、150以上の新しい言語モデリングタスクからなるBIG-benchのベンチマークテストでは、人間の平均スコアを超える成績を達成しました。2022年7月現在、最高性能の言語モデルではないかと言われています。

(5) MetaのNLLB-200など
2022年5月にMetaがGPT-3に匹敵する1,750億のパラメーターを持つ「OPT-175B」(Open Pretrained Transformer 175B)を公開しました。
OPT-175Bは、人間の指示に従って文章を作成したり、数学の問題を解いたり、会話したりすることができます。
また、GPT-3と同等の性能を維持しつつ、トレーニングに必要なカーボンフットプリント(CO2排出量)は、GPT-3の1/7で済みます。
さらに、OpenAIなどが悪用を恐れて公開していなかった学習済みモデル本体やモデルをトレーニングするためのプログラム一式を研究者に無償で公開したことが注目されています。
2022年7月にMetaは、200種類もの言語翻訳が可能な「NLLB-200」(No Language Left Behind 200)を発表しました。Metaでは、学習済みのモデル本体以外に、評価データセットのFLORES-200やモデル学習コードもオープンソースにしました。
NLLP-200の翻訳精度(BLEUスコア)は、従来の最高水準を平均44%上回り、アフリカやインドの一部の言語については、70%以上高い精度を記録しました。
Metaでは、NLLB-200モデルのオープンソース化を推進し、このモデルを採用したアプリをSDGsの取組などに活用する非営利団体に最大20万ドルの助成金を提供すると発表しました。NLLB-200の開発成果は、Metaが運営するFacebookとInstagramだけではなく、Wikipediaの翻訳の改善にも活用されています。
また、Metaは、こうした多言語の翻訳機能が、世界中の多くの人々がメタバースにアクセスして自由に交流できるようにするために役立つと主張しています。

(6) その他の大規模言語モデル
大規模言語モデルの開発は、アメリカや中国以外にも広がってています。
2021年5月、韓国で検索エンジン事業などを運営するNaverは、韓国語データでトレーニングした2,040億のパラメーターを持つ「HyperCLOVA」を構築中であると発表しました。
また、2021年8月、イスラエルのスタートアップ企業であるAI21 Labsは最大1,780億のパラメーターを持つ「Jurassic-1」を発表しました。なお、AI21 Labsは、自動運転システム開発ベンチャーのMobileye創業者のアムノン・シャシュア ヘブライ大学教授らが設立した自然言語処理に特化したAI開発ベンチャーです。
Jurassic-1は、同社の開発者向けプラットフォームであるAI21 Studioでオープンベータ版として公開中であり、AI21 Studioに登録して利用することができます。
⑤ 大規模言語モデルの課題
(1) 常識推論能力
GPT-3で、文章生成などを試してみると、文法的に間違いがなくて、一見、自然な文章に見えますが、内容は支離滅裂で意味が分からないということがよくあります。
「ある日、もりの中」(←最初の入力文 以下は全部GPT-3による文章生成)
そこは、風に揺られていた
緑の木々の下で
「ねぇ!」
彼は、手をかかえて走った。
「お前、この先に何があるんだ?」
「それは私たちの未来だ。」
彼は、手を伸ばして掴んだ。
「今まで…この町で過ごしてきた幾日幾時とか…全部を忘れろ!」
彼は、手を伸ばして掴んだ。
「これからは…新しい冒険のスタートだ!」
そこで、彼は笑った。
そして、彼は歌った。
「君は僕の太陽。」
それから、彼は走った。
「今まで…この町で過ごしてきた幾日幾時とか…全部を忘れろ!」彼は、手を伸ばして掴んだ。「これからは…新しい冒険のスタートだ!」そこで、彼は笑った。そして、彼は歌った。「君は僕の太陽。」それから、彼は走った。
「ペットの犬の名前は何がいい?」(←最初の入力文 以下は全部GPT-3による文章生成)
赤ちゃんの命名会は、これまでにない深刻な問題に遭遇しました。 私は「多くの親が私たちの子供を呼んでいる名前を見るだろう」と思っています。 それはおもしろかった? ママとパパは、「夢」と「生き物」の2人の男の子と1人の女の子を産んでいるが、彼らの毎日の生活に大きな影響を及ぼすこともあります。 家族的な愛情の中で背中を与えられた子供の思考文化は:家族全体の間で互いにつながっているので、家族全体に影響を及ぼすこともあります。
命名会に出席した親たちは、私たちの子供の命名会に対して次のような提言をしました。 私は男の子の命名会の時間が過ぎる前に産んだ女の子の生後2週間目で『チャオ』と呼んだ。 私は子供が生まれてから数日後、私は自分の部屋で「チャオー! ダンダン~」と叫き始めました。 今でも子供の頃の毎日の習慣は忘れていません。
これは、大規模言語モデルによる文章生成の方法に原因があると見られています。大規模言語モデルは、大量のテキストデータから文章のパターンを学習し、そのパターンを基に、次に来るべき単語を予測することによって、それらしい文章を作成しています。
そのため、人間であれば、当然に持っている常識や背景知識が欠けており、文章の表す意味内容を正確に理解することができていないのです。
例えば、「冷蔵庫にチーズを入れると溶けるか?」という質問に、GPT-3は正しく答えることができません。この問題に答えるには、「チーズは温めると溶けるが、冷やしても溶けない。そして、冷蔵庫は、ものを冷やす道具である。」という常識を備え、「今回の質問では、チーズを冷やしているのだから溶けない。」と推論する必要があります。
このような現実世界に関する基本的な常識に基づいて推論する能力を「常識推論能力」と言い、この能力を大規模言語モデルに持たせることが大きな課題となっています。
最近の大規模言語モデルは、大量のテキストデータを学習することによって、文章の裏に隠された基本的な常識や背景知識をある程度、理解するようになってきましたが、まだ十分ではありません。
これを解決するために、様々な常識や知識をデータベースにまとめた「知識ベース」やこうした知識のつながりをグラフ構造で表した「知識グラフ」を活用する試みも始まっています。
中国の言語モデルの開発は、あまり詳しい情報が入ってこないのですが、Baiduが開発したERNIE 3.0は、知識グラフデータを学習データに加えることによって、非常に一貫性のある回答を返すことができるようになったと説明されています。
また、推論能力を高めるための取組としては、GoogleのPaLM開発の際の取組に注目しています。PaLMの開発と併せて発表された論文によれば、プロンプト(AIにタスクを教えるために最初に入力する文字列)に「思考の連鎖」に関する例文を入力するという手法により、論理的推論を強化することができたということです。

さらに、今年(2022年)6月に「人工知能が意識や感情を持ったのか」と騒ぎになったGoogleの対話型人工知能LaMDAの公開された対話記録を見ると、まるで人工知能が人格を持ったかのような、会話の内容に対する深い理解とストーリーの一貫性が感じられます。
LaMDAの対話記録が特に良い結果だけを抜き出したものかどうかは分かりませんが、これが本物だとすると、大規模言語モデルの常識推論能力の獲得について、何か大きな進展があったのでしょうか。
(2) バイアスの問題
ネット上のWebサイトなどを利用して学習データを集めると、どうしても差別的な主張や暴力的な表現などの倫理的に問題のあるデータが含まれてしまうため、そのようなデータで学習した言語モデルによって、社会通念上、望ましくない偏った内容や表現の文章が生成されてしまうことがあります。
こうしたバイアスの問題は、世界中の言語モデル開発者が重要課題として認識しており、OpenAIによるInstructGPTの開発など、倫理的に問題のある表現を排除する取組が行われています。
具体的には、学習データをフィルタリングして、問題のあるデータを取り除くという手法や、偏った内容や表現の文章を生成しないように、人間が評価したラベル付きのデータを使って言語モデルに学習させる手法などが取られています。
しかしながら、差別的な表現などは、一見してすぐに分からないような形で文章の中に潜んでいる場合もあり、完全に排除することは、なかなか難しいようです。

(3) 応答の根拠と信頼性
GTP-3に文章生成を行わせた場合、一見、まともな文章のように見えても、それが根拠のある事実なのか、作り話なのかよく分からないことがあります。また、こうした事実かどうか分からない文章が外部に出回ると、フェイクニュースとなってしまう危険性があります。
こうしたことを避けるために、例えば、Googleでは、言語モデルがユーザーの質問に対する応答案を作成する際に、外部の情報検索システムで信頼性の高い応答を検索し、その情報を作成する応答案に反映することによって、応答にできるだけ根拠を持たせるという方法が検討されています。
(4) 巨大言語モデルの運用・開発コストの問題
巨大言語モデルの運用については、基盤となる計算機資源などのインフラ整備コストや膨大な学習データとパラメーターを使用したトレーニングのための運用コストなどが掛かり、なかなか実運用に踏み切れないという問題があります。
Googleを始め、米国や中国の言語モデル開発企業も、言語モデルのアルゴリズム改善などによる計算コストの削減に取り組んでいますが、やはり大規模な計算機資源が必要なために相当なコストが掛かります。
また、品質の高い学習データを集めることも大変で、そのために多くの費用が掛かります。こうした学習データを言語モデル自ら作り出して、性能を上げていくことはできないのだろうかと思っています。
OpenAIは、現在、GPT-3を最初のアカウント登録時は無料ですが、基本的に有料課金制で公開しています。また、OpenAIは、今月(2022年7月)、画像生成AIのDALL-E 2も同様に最初は無料で、その後は有料課金制にして一般公開を開始しました。
もともと非営利だったOpenAIが最も積極的に有料課金制に取り組んでいるのは皮肉な面もありますが、運用経費を賄っていくには必要な取組なのでしょう。
また、言語モデルの大規模化が進んで、莫大な計算機資源や運用コストの負担が必要になったために、Google、Microsoft、Metaなどの米国の巨大IT企業か中国の組織でなければ、高性能な言語モデルの開発が難しくなってきています。
現在のところは、これらの大規模言語モデルがオープンに利用できるようになっていますが、今後、これらの技術や情報が一部の企業や国に独占されるようなことになった場合に、世界にどのような影響があるのか、よく考えておかなければならないでしょう。
この記事が気に入ったらサポートをしてみませんか?