
最近、人工知能による自然言語処理が爆発的に進化しているのでまとめてみた。【前編】

近頃、Google翻訳やDeepL翻訳などの機械翻訳が実用レベルになり、人間が書いたような文章を作成できるGPT-3が話題になるなど、人工知能による自然言語処理が注目されるようになってきました。
特に最近は、入力された文章に合わせて絵を描く「DALL・E 2」、自動でコンピュータープログラムを作成する「AlphaCode」、人工知能が意識や感情を持ったのかという騒動を巻き起こした対話型AIの「LaMDA」など、自然言語処理分野で毎週のように驚くような研究開発成果が発表されています。
あまりに進化が速すぎるので、今、この分野が一体どんなことになっているのか混乱している方も大勢いるのではないでしょうか。そこで、人工知能による自然言語処理が近年どのように進化してきたのか、また、現在どういう状況になっているのかについて整理してみました。
1.自然言語処理の歴史(TransformerとBERTまで)
① リカレントニューラルネットワーク (1986年)
ニューラルネットワークで文章データを扱う場合、機械学習の結果を用いて、入力された言葉から次にくる言葉を順番に予測していくことによって文章を作成していきます。
しかし、例えば、「日本で一番高い山は富士山です。」という文章データを考えた場合に、直前の「山は」という言葉だけから次に来る「富士山」という言葉を予測することは難しく、「日本で一番高い」という言葉を記憶しておいて初めて、次にくる言葉が「富士山」だろうと予測することができます。
このように、文章データなどの時系列データを扱うには、過去の情報を反映できる仕組みが必要であり、そのために考案されたのが回帰型(リカレント)構造を持つ「リカレントニューラルネットワーク」(RNN)です。
RNNは、入力層、隠れ層、出力層という3つの層で構成されており、入力層でデータを受け取って、出力層で結果(文章データの場合は次に来る予測ワードの出現確率)を出力します。また、隠れ層は、入力層からの情報に加えて、前の時刻の隠れ層からの情報も受け取って処理します。
このように、隠れ層が自らの出力した情報を再度受け取る仕組みを回帰型構造と言い、この仕組みによって、過去の情報を加味したデータの処理を行うことが可能となります。毎回、継ぎ足して使う老舗のうなぎ屋の秘伝のタレみたいですね。

RNNは、Transformerの登場以前は、機械翻訳などの自然言語処理や音声認識などに幅広く利用されていました。
② LSTM(1997年)
文章データなどの時系列データを処理する場合には、短期的記憶に当たる直前の情報のみではなく、長期的記憶に当たる相当前の情報も必要になる場合があります。ところが、RNNでは長期的記憶が損なわれてしまうという問題がありました。
そこで、RNNにゲート機構を追加することで、この問題を解決したのが、LSTM (Long Short-Term Memory)です。
LSTMでは、RNNの隠れ層を、「記憶セル」と「入力ゲート、出力ゲート及び忘却ゲートの3つのゲート」で構成されたLSTMブロックに置き換えています。記憶セルは、下図cの長期的記憶を記憶し、忘却ゲートは、長期的記憶cに直前の短期的記憶hを加えて、どの記憶を忘れて、どの記憶を長期的記憶として残すかを制御します。
この仕組みによって、LSTMは、必要な長期的記憶を残して学習できるようになりました。

LSTMは、Transformerの登場以前は、自然言語処理や音声認識、音声合成などの時系列データの処理において、最も使われているモデルの一つでした。
③ Seq2Seq (2014年)
Seq2Seqは「Sequence-to-Sequence」の略で、あるシーケンス(文字列や画像の特徴量など)を別のシーケンスに変換するRNNモデルの一種です。機械翻訳、文章要約、画像キャプションの付与などの分野で大きな成功を収め、2016年後半からGoogle翻訳でも使用されました。
Seq2seqは、エンコーダーとデコーダーから構成されており、エンコーダーは入力データをその特徴を表すベクトルに変換し、デコーダーはその特徴ベクトルを新しいデータに変換して出力します。
Seq2seqのエンコーダーとデコーダーには、RNNやLSTMがよく利用されています。

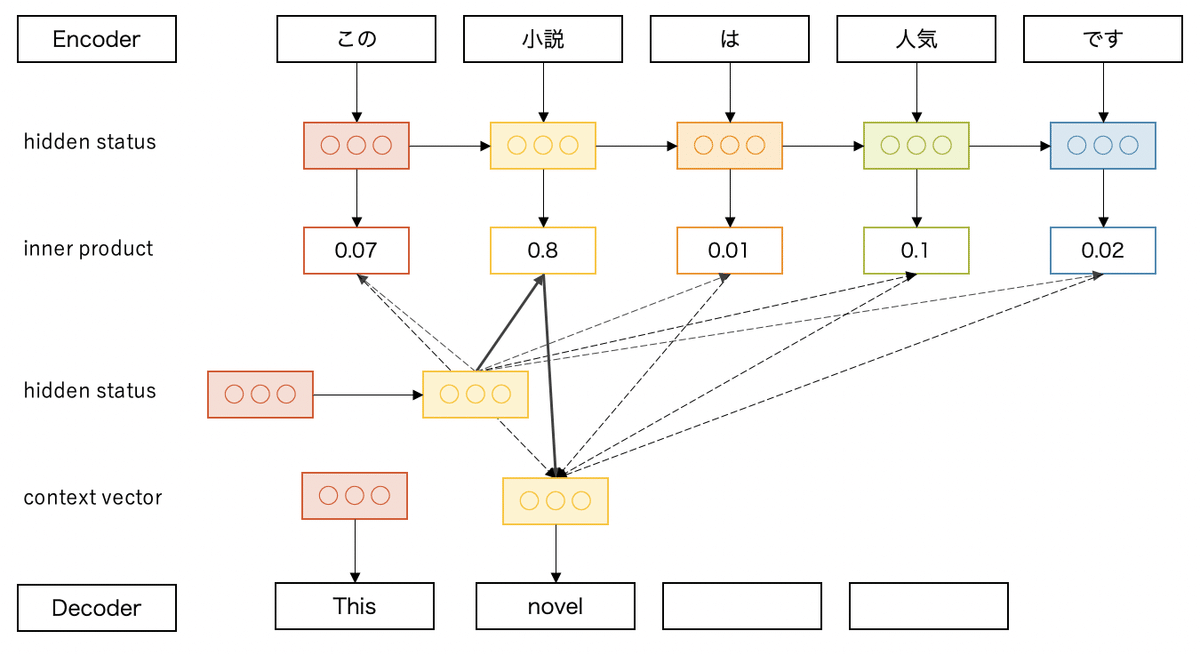
④ Attention (2015年)
Attentionは、対象となるデータの重要な部分(自然言語処理の場合は単語)に注意を向けさせて、効率的に機械学習を行う仕組みです。
Seq2Seqモデルは、短い文章であれば高精度に文章解析を行えますが、文章が長くなると精度が落ちるという欠点がありました。これは、Seq2Seqのエンコーダーで変換される特徴ベクトルの長さが決まっているため、長い文章を入力すると、情報があふれて過去の情報が失われてしまうのが原因です。
従来のSeq2Seqでは、最後の特徴ベクトルの情報だけをデコーダーに渡していましたが、Attentionでは、この問題を解決するために、すべての特徴ベクトルの情報をデコーダーに渡し、それらの情報の重要度を計算して、重要度の高い情報のみをデコーダーで利用するようにしています。
このように、Attentionの仕組みは、Seq2Seqモデルの中でRNNやLSTMと一緒に利用されて、長い文章の解析の精度を上げるのに貢献しました。
また、Attentionは、画像の中の重要な部分に注意を向けさせるために、画像認識でも利用されるようになりました。
⑤ Transformer (2017年6月)
Googleは、2017年6月に、その後の自然言語処理の世界を一変させた画期的な論文「Attention Is All You Need」を発表しました。
この論文でGoogleは、RNNやLSTMを使わずにAttention機構のみを用いた「Transformer」と呼ばれる多層ニューラルネットワークモデルを紹介し、Attention機構だけで従来以上の性能を発揮できることを示しました。
これまでのSeq2Seqなどの自然言語処理モデルでは、時系列データを処理するためにRNNやLSTMを利用していましたが、これらはデータを順番に処理する必要があるため、学習に時間がかかりました。ところが、Transformerモデルでは、時系列データを逐次処理する必要がないため、GPU(画像処理用の演算装置)を利用した学習の並列化が容易になり、大量のデータセットでのトレーニングが可能となりました。
この後、後述⑦のBERTを始めとするTransformerベースの大規模な事前トレーニング済み自然言語処理モデルが次々と開発され、言語理解のベンチマークテストで圧倒的な成果を見せつけました。こうして、自然言語処理の分野では、RNNやLSTMに替わってTransformerベースのモデルが主流になりました。
また、画像認識の分野でも、これまで畳み込みニューラルネットワーク(CNN)が主流だったのですが、2020年9月にGoogleが開発したCNNを一切使わないTransformerベースのVision Transformer(ViT)が最高性能(SOTA)を達成し、研究者の注目を集めています。
さらに、画像生成の分野でも、2021年2月に誕生したCNNの代わりにTransformerを組み込んだ敵対的生成ネットワーク(GAN)のTransGANがSOTAを達成しました。

⑥ ELMo(2018年2月)
ELMo(Embeddings from Language Models)は、2018年に米国のアレン人工知能研究所が発表した言語モデルで、BERTに大きな影響を与えたと言われています。また、ELMoの発表以降、しばらく言語モデルにセサミストリートのキャラクターの名前を付けるのが流行しました。

ELMoは、大量の文章データを使って事前学習を行う際に、文を文頭から読んでいく順方向と文末から読んでいく逆方向の双方向から読み進めることで、文脈を考慮した単語の意味の把握を可能にしています。
例えば、「bank」という単語には、「銀行」という意味と「土手」という意味があり、「A bank is a financial institution where you deposit your money.」という文を考えた場合に、順方向に読んで、初めて「bank」と言う単語が出てきたときには、どちらの意味かは分かりません。
しかし、逆方向から読むと、「financial」「deposits」「money」など金融に関係する単語が先に出てきますので、「bank」は「銀行」という意味で使われているのだと判断できます。
ELMoは、順方向と逆方向のそれぞれ2層のLSTMから構成されています。

⑦ BERT (2018年10月)
BERTは「Bidirectional Encoder Representations from Transformers」の略で、翻訳、文書分類、質問応答等の様々なタスクに対応できるTransformerベースの自然言語処理モデルです。

BERTは、Transformerのエンコーダー部分のみを利用しています。
BERTは最初に、ラベルの付いていない大量の文章データから汎用的な言語ルールを事前学習します。
この事前学習は、文章の穴が開いたところに入る単語を当てる穴埋め問題のMLM(Masked Language Modeling)と、2つの文を選んで、それらが連続した文かどうかを当てるNSP(Next Sentence Prediction)の2種類の方法で行われます。
次に、事前学習済みモデルをベースに、個別タスクに合わせてファインチューニング(微調整)を行います。ゼロからの学習と比べて、少量のラベル付き学習データで、短時間で学習することができます。
また、事前学習済みモデルは、様々なタスクのファインチューニングで再利用することができます。
BERTは、自然言語処理の標準ベンチマークである GLUE (General Language Understanding Evaluation)で圧倒的なスコアを達成し、人間のスコアをも上回ったことで、話題になりました。
BERT登場以降は、BERTを改良したXLNet やRoBERTaなどのTransformerベースの言語モデルが次々と登場しました。
