
”保険簿”というプロダクトにおけるOCR×ChatGPT(LLM)の活用について。/IB開発チームインタビューmini

保険簿(ほけんぼ)公式note編集部です!
保険簿アプリを運営・開発しているIBのチーム&メンバーインタビューvol.2。今回はそのミニ版として、開発チームに保険簿アプリにおけるOCRとChatGPT(LLM)の活用について解説してもらいました。
保険簿アプリとは?
まずは編集部から、保険簿アプリについて簡単に説明します。
「保険簿」は加入している保険の請求もれを防ぐことを目的とした、保険管理アプリです。株式会社IBが加入者と保険業界の間に立ち、中立的に運営を行っています。保険の販売は一切行いません。

保険簿の基本機能
・保険のデータ化:保険の書類を撮影/PDFをアップロードするだけで登録
・データの共有:登録した保険データを家族と共有
・請求の可能性を診断:起きた事象から請求できる可能性のある保険データを自動でピックアップ
・保険の期限通知:満期/終期、見直し/解約予定を通知
その他にも補償の可視化、保険の年間スケジュール、保険料のグラフ表示などなど、契約中の保険の管理に役立つ機能を備えています。
ミッションとプロダクト理念
IBのミッションは「保険の請求もれをなくす」です。保険簿アプリはそのミッション達成のための仕組みとして提供しており、請求もれ防止に繋がるかを前提としてプロダクトの設計を行っています。
”保険の請求もれ”という社会課題、そして保険簿の機能をさらに詳しく知りたい方は、こちら▽の記事もぜひご覧ください。
そんな保険簿のプロダクトを創る開発チーム。
取り扱う部分は多岐にわたるため、今回は開発チームのタスクの中でも、ChatGPT(LLM)を利用しているOCRに関わる領域に絞ってメンバーに話を聞いています。
ここからは開発チームの山室(yamamuro🦇)に文章をバトンタッチしてお届けします!
1.IBの開発チームと、OCRのタスクについて
山室:保険書類の画像を送信するだけですべての保険契約を一括管理できる「保険簿」というモバイルアプリを提供する、株式会社IBの開発チームは、「ユーザーが安心して使えるプロダクトを創る」というビジョンのもと、正社員3名(CTO、バックエンドエンジニア、モバイルエンジニア)と業務委託メンバー3名という構成で、2週間に1回のリリース頻度を目標に、アジャイル開発を行っています。
このnoteでは、保険簿アプリを提供する上で欠かせない「OCR : Optical Character Recognition」という文字認識(+ 情報の構造化)のタスクについて紹介します。
保険簿アプリは次のような流れで、送られた保険書類の画像をアプリ上へデータ反映しています。
▼「保険簿」アプリでの保険のデータ化の流れ
① ユーザーが登録した保険書類の画像/ファイルが社内システムに届く
② OCRとAIを使って必要な保険情報を自動でデータ化
③ 内容をInsuranceDataBaseチームでダブル・トリプルチェック
④ ユーザーへ反映完了
上記のフローのうち、「②OCRとAIを使って必要な保険情報を自動でデータ化する」タスクこそが本noteで取り扱う部分です。
このタスクの精度を向上させることで、「③のInsuranceDataBaseチームでのチェックコスト」が抑えられ、「データ反映までの時間」を短縮させることができるため、精度を継続的に確認しながらアジャイル開発のなかでOCRのワークフローの改善を行っています。
2.これまで取り組んできたこと
山室:保険書類の画像から情報を抽出し構造化するOCRのタスクに対し、今年の4月までは下記のような方法でデータ化されていました。
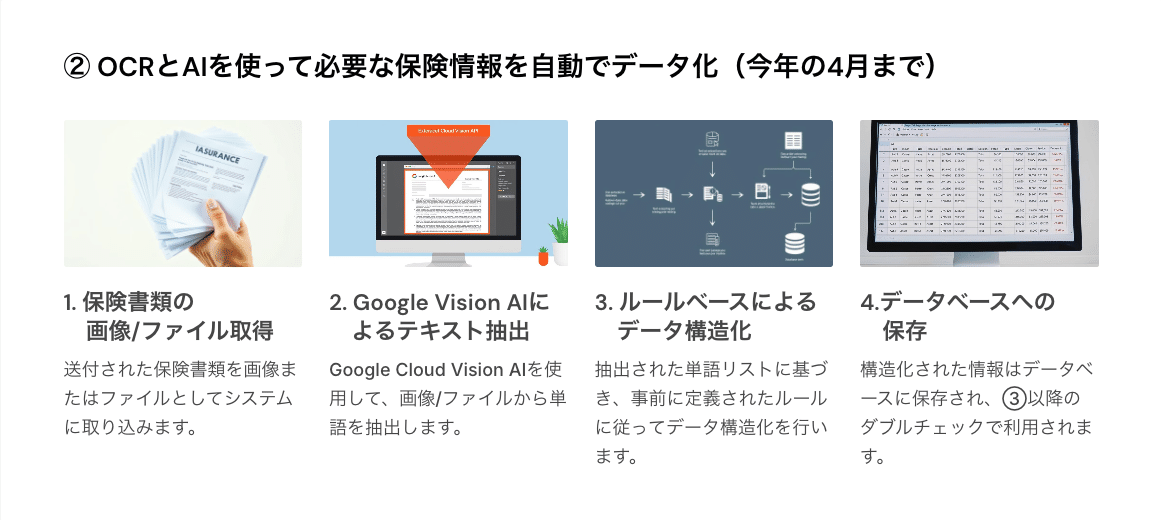
ただ、すべての保険会社の保険書類を取り扱っているため、各社バラバラのフォーマットで送られてくる保険情報の構造化に対しては、ルールベースでの対応には限界がありました。とくに、保険会社名が記載されていないものや商品や保障名が整理されていない書類に対しては、十分なパフォーマンスを発揮できていませんでした。そのような課題感に対し、ChatGPTの検証を始めたのが今年度でした。
ChatGPT(LLM)がもたらしたパラダイムシフトはとても大きく、日進月歩で進化を続けています。IBのメンバーの中でも、Github Copilotというペアプログラマーを連れてコードを書いたりといった業務利用はありましたが、23年度はアプリと社内システムのリプレイスもあり、着手が開始したのは24年度の頭でした。ワークフローを変更する上でいくつか選択肢がありましたが、言語処理学会第30回年次大会 (NLP2024) 参加レポート - estie inside blog を参考に、類似したタスクで一定のパフォーマンスを発揮していた「OCR + LLMによる2段階の情報抽出 = 上の図の3.の部分をChatGPTで代替」の検討・リリースを、以下のプロセスで進めました。

上記のようなプロセスで進めることにより、スタートアップらしいスピード感で本番リリースまで至れたこと、リリース後も期待値通りのパフォーマンスを発揮できているのは、一定の収穫があったと考えています。
しかしながら、ユーザへの即時反映で間違った保険情報を提示することにより信頼性を損ねるリスクが一定あることや、ダブルチェックが未だ必要な状態といった課題はあるため、OCRのタスクをより良くしていく動きは続けていきます。
3.これから挑戦したいこと
山室:これまで、ルールベースからChatGPTへのロジック変更により、OCRのタスクの性能を改善してきたわけですが、挑戦すべき課題はまだあります。
LLMのモデルを高性能にしていくには、知識データベースを与えて検索機能を拡張する「RAG」か、独自のデータでモデルを追加学習させる「ファインチューニング」のいずれかが取れる策です。LLMの高性能化のためにはインプットトークン数にまだ余裕はあるものの、IBの技術的な資産として、すべての保険会社の保険商品を網羅したInsuranceDataBaseがあり、そのデータ数を加味すると「RAG」の利用がベストであると開発チームの中では認識が一致しています。また、Google社の提供するnotebookLMでの検証の過程ではありますが十分なパフォーマンスを発揮してくれる期待感を抱いているところです。

これからは、LLMが参照する知識としてInsuranceDataBaseをいかに準備し、どのようなプロンプトでタスクを解かせるか、そしてこのワークフローをどんなシステム構成で構築するかといった点に、挑戦していきます。
🪧補足
InsuranceDataBaseとは、WEBで公開されている各保険会社の商品約款などを利用してIB独自に調査・作成しているDataBaseのことです。
▷InsuranceDataBase作成の裏側について:InsuranceDataBaseチームインタビュー
また、本noteで紹介した開発フローを含め、弊社では登録された個人情報の第三者提供は一切行っておりません。
▷セキュリティに関して:サービスサイト内よくある質問へ
***
最後までご覧いただきありがとうございました。
本記事で保険簿に興味を持ってくださった方は、この機会にぜひインストールいただけると幸いです。一つでも保険に加入されている方は、いざというときの請求もれを防ぎ家族の負担を減らすためにも、ぜひ保険簿をご利用ください。

▽IB会社サイト/保険簿サービスサイト
▽おすすめ記事
▽【保険代理店向け】公式LINE

/
スキやSNSでのシェアなど
保険簿の応援よろしくお願いします!
\
この記事が気に入ったらサポートをしてみませんか?