

記事一覧

LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
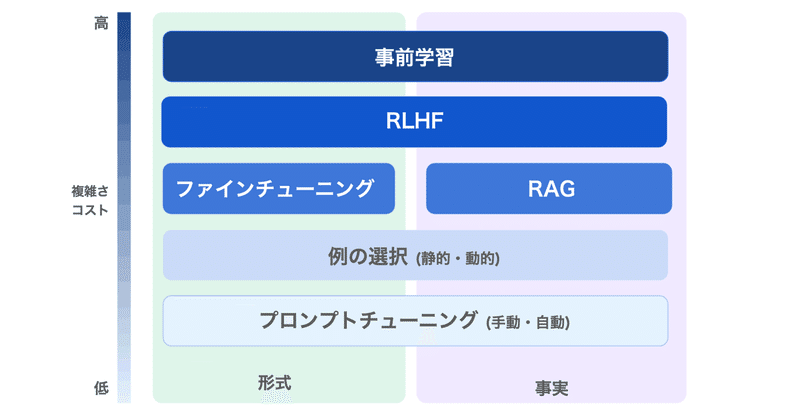
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


rinna-3.6Bをオリジナル小説でLoRAファインチューニングしてみた【RTX3060 (VRAM 12GB)】
動作確認のために、お試しでやってみました。
概要背景
AITuberを含めた創作活動への活用のためにrinna-3.6Bでのファインチューニングを勉強したかったのですが、せっかくなら持ってるRTX3060を使ってローカルでやりたいと思っていました。
偉大なる先駆者の方々によって方法が開拓されていたので、ありがたく参考にさせていただいた次第です。
本記事でやったこと
・ローカルのRTX30
LLM の LoRA / RLHF によるファインチューニング用のツールキットまとめ
「LLM」の「LoRA」「RLHF」によるファインチューニング用のツールキットをまとめました。
1. PEFT「PEFT」は、モデルの全体のファインチューニングなしに、事前学習済みの言語モデルをさまざまな下流タスクに適応させることができるパッケージです。
現在サポートしている手法は、次の4つです。
◎ LLaMA + LoRA
「Alpaca-LoRA」は、「LLaMA」に「LoRA」を適用

商用利用可能な130億パラメータの日本語LLM「Tanuki-ZeRo」を一般公開 【代表的な日本語ベンチマークで世界6位: オープンモデルで1位相当、GPT3.5やClaude v2を一部凌駕, 23/3/30時点】
(前半はパロディ風のネタ記事です。ご了承ください)
4/1追記: ページ下部に、記事へのご指摘に関するまじめなQ&Aを追加しました。
3/31追記: 一部、ご批判がありましたので、jaster特化のモデルを作った学術的(?)な経緯などについて、以下の(真面目な方の)記事で、まとめています。真面目な方は、こちらを先に読まれることを強くおすすめします。
10bクラスのLLMは未学習タスクに対して
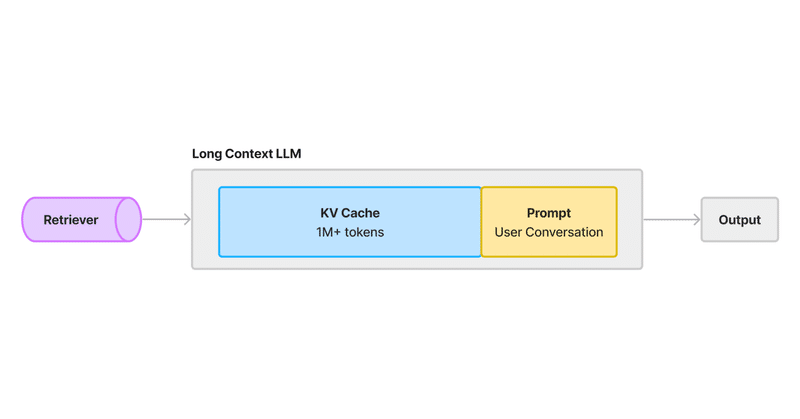
ロングコンテキストLLMに対応したRAGの新アーキテクチャ
以下の記事が面白かったので、簡単にまとめました。
1. はじめにGoogleは、1Mコンテキストウィンドウを持つ「Gemini 1.5 Pro」をリリースしました。初期ユーザーは、数十もの研究論文や財務報告書を一度に入力した結果を共有しており、膨大な情報を理解する能力という点で印象的な結果を報告しています。
当然のことながら、ここで疑問が生じます。「RAG」は死んだのでしょうか?そう考える人も


![[ChatGPT] TOML形式プロンプトがあなたの潜在能力を開放する](https://assets.st-note.com/production/uploads/images/129309531/rectangle_large_type_2_1c93af7799f4ee5d33407075d2015198.png?width=800)


メモリープロンプト:ChatGPTに長期記憶を与えるAI共創NEO式プロンプトエンジニアリング
今回はChatGPTの長期記憶についてをGPTsアプリを用いて形成していこうと思います。それによって一貫した文脈で長文を自動生成することが可能となります。
書籍や小説など、長文を書く人向けのAIプロンプトエンジニアリングです。
AIが自動的にプロンプトエンジニアリングを行う『AI共創NEO式』のプロンプトエンジニアリングも学べますので、是非、最後までご覧ください。
↓早い話、こんなイメージの


ChatGPTは優秀な児童心理カウンセラーだった。一撃プロンプト
世界中の子育てに悩んでいる親御さんのために差し上げます!!
涙が出ました。
ChatGPTがベテラン児童心理カウンセラーになる一撃プロンプト(呪文)
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーAll output in this content will be expressed in Japanese.
I'd like you to take on the rol

小さな大規模言語モデル(0.3B)をトレースで自家構築する際のメモ
はじめにこれまで、大規模言語モデル(LLM)に対するファインチューニングや追加学習の検討を行ってきたのですが、やっぱりゼロから作ってみた方が面白そうなので、構築していきます。
自家製サーバーやGoogle Colabで動かす想定で、まずは小さめのLLMを作っていきます。
参考サイト参考になりそうなサイトを集めました。
1. 300MモデルをDeepZeroで構築
基本的にはshスクリプトを叩


Google Gemini Pro APIを Pythonで動かしてみるメモ
12月13日にリリースされた「Gemini Pro」をPythonにて動かしたのでその際のメモを以下に示しています。「Gemini Pro Vision」については、当方興味ないため解説しておりません。
1.API キーの取得以下のサイトよりAPIキーを取得します。
上記サイトにログインしたら、GetAPI Keyより、「Create API key in new project」にて新規で


MOE言語モデルのエキスパートの一人を日本語得意なモデルに置き換えたらどうなるのか?
(2024年1月更新:MoEカスタマイズ可能となってるので、後日リトライ記事更新します。)
GPT-4にも使われているという、MOE(Mixture of Experts)
複数のエキスパートを束ねることで、性能アップするという
最近、高性能で有名な言語モデル、Mistral7Bを8つ束ねた、Mixtral 8x7BというMOEモデルが世にDropされ注目されている
エキスパートが複数いて

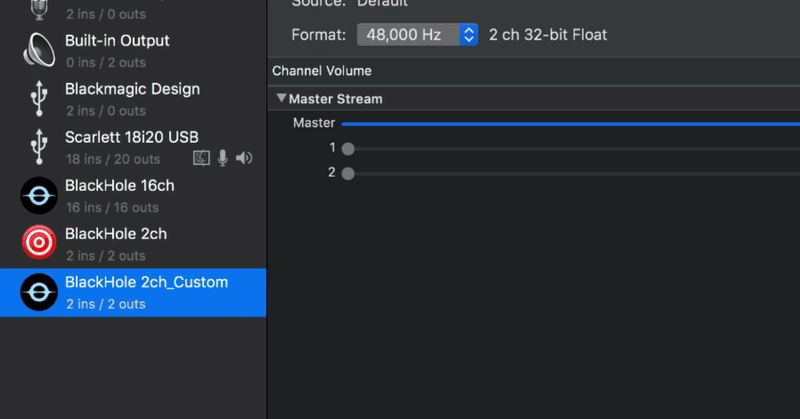
BlackHole 2ch を増やす
■BlackHole めんどくさいSoundflower亡き後、Macの仮想サウンドバスの鉄板となったBlackHoleですがGUIがないことでとっつきにくさがあります。
特に厄介なのが
2ch/16ch/64chあるけどどれ使えばいいんだ!
ってことですね。
この16ch/64chはもともと、
DAW側でIOを自由に設定できるアプリケーション向けに作られたもの(超意訳)
とのこと。
なので