
MOE言語モデルのエキスパートの一人を日本語得意なモデルに置き換えたらどうなるのか?

(2024年1月更新:MoEカスタマイズ可能となってるので、後日リトライ記事更新します。)
GPT-4にも使われているという、MOE(Mixture of Experts)
複数のエキスパートを束ねることで、性能アップするという
最近、高性能で有名な言語モデル、Mistral7Bを8つ束ねた、Mixtral 8x7BというMOEモデルが世にDropされ注目されている
エキスパートが複数いて、得意なエキスパートに振り分けると聞いて
8人の賢者が、問題を分担して説いている様子を思い浮かべていた

いざ Mixtral8x7Bを使ってみると、日本語が弱い!
そこで、思った。
エキスパートを何人か、日本語が得意なMistral7B互換モデルに差し替えたらどうだろう?
そういえば、stabilityaiが、Mistral7Bの継続日本語学習モデル持っていたな!
ふと思い浮かぶ、ギリシャ賢者の中に、サムライの姿が!

まず、MOEモデルの構造を調べた。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
moe_model = AutoModelForCausalLM.from_pretrained(model_id)
print(moe_model)
>
MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MixtralRotaryEmbedding()
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): Linear(in_features=4096, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): Linear(in_features=4096, out_features=14336, bias=False)
(w2): Linear(in_features=14336, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=14336, bias=False)
(act_fn): SiLU()
)
)
)
(input_layernorm): MixtralRMSNorm()
(post_attention_layernorm): MixtralRMSNorm()
)
)
(norm): MixtralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)つぎに、japanese-stablelm-base-gamma-7b
model_a = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-base-gamma-7b",
torch_dtype="auto",
)
print(model_a)
>
MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)要するに以下のような構造のようです。
埋め込み層 (embed_tokens): 入力トークンを固定次元のベクトルに変換します。
デコーダレイヤー (layers): トランスフォーマーベースのデコーダレイヤーです。各レイヤーには以下のサブコンポーネントが含まれます:
自己注意層 (self_attn): クエリ、キー、バリューの投影(q_proj, k_proj, v_proj)と出力投影(o_proj)を含みます。
Mixture of Experts層 (block_sparse_moe): 複数のエキスパート(MLPブロック)を含み、各トークンは最適なエキスパートにルーティングされます。
レイヤー正規化層 (input_layernorm と post_attention_layernorm): 層ごとの正規化を行います。
最終正規化層 (norm): デコーダの出力を正規化します。
言語モデルヘッド (lm_head): 最終的なトークン予測を行います。
互換性があるか確認する
def check_compatibility(model_a, moe_model, expert_index):
compatible = True
# エキスパートのインデックスの検証
if expert_index < 0 or expert_index >= len(moe_model.model.layers[0].block_sparse_moe.experts):
raise ValueError("Invalid expert index")
# 各デコーダレイヤーをループ処理
for layer_index in range(len(model_a.model.layers)):
# 対応するレイヤーにアクセス
model_a_layer = model_a.model.layers[layer_index]
moe_model_layer = moe_model.model.layers[layer_index]
expert = moe_model_layer.block_sparse_moe.experts[expert_index]
# 自己注意レイヤーの形状とタイプを比較
for attn_component in ['q_proj', 'k_proj', 'v_proj', 'o_proj']:
model_a_weight = getattr(model_a_layer.self_attn, attn_component).weight
moe_model_weight = getattr(moe_model_layer.self_attn, attn_component).weight
if model_a_weight.shape != moe_model_weight.shape or type(model_a_weight) != type(moe_model_weight):
print(f"Incompatible weights found in self attention {attn_component} at layer {layer_index}")
compatible = False
# MLPレイヤーの形状とタイプを比較
if model_a_layer.mlp.gate_proj.weight.shape != expert.w1.weight.shape or \
model_a_layer.mlp.down_proj.weight.shape != expert.w2.weight.shape or \
model_a_layer.mlp.up_proj.weight.shape != expert.w3.weight.shape:
print(f"Incompatible weights found in MLP at layer {layer_index}")
compatible = False
return compatible
# 互換性確認
compatible = check_compatibility(model_a, moe_model, expert_index=0) # 0を希望するエキスパートのインデックスに置き換えてください
if compatible:
print("Models are compatible")
else:
print("Models are not compatible")
MOEのエキスパートに日本語を学習したMistral7Bをコピー
def copy_weights_from_model_a_to_moe(model_a, moe_model, expert_index):
# Check if the expert index is valid
if expert_index < 0 or expert_index >= len(moe_model.model.layers[0].block_sparse_moe.experts):
raise ValueError("Invalid expert index")
# Iterate through all the decoder layers
for layer_index in range(len(model_a.model.layers)):
# Access the corresponding layers in both models
model_a_layer = model_a.model.layers[layer_index]
moe_model_layer = moe_model.model.layers[layer_index]
# Copy weights for self-attention layers
moe_model_layer.self_attn.q_proj.weight.data.copy_(model_a_layer.self_attn.q_proj.weight.data)
moe_model_layer.self_attn.k_proj.weight.data.copy_(model_a_layer.self_attn.k_proj.weight.data)
moe_model_layer.self_attn.v_proj.weight.data.copy_(model_a_layer.self_attn.v_proj.weight.data)
moe_model_layer.self_attn.o_proj.weight.data.copy_(model_a_layer.self_attn.o_proj.weight.data)
# Copy weights for MLP/gate/up/down layers to the specified expert
expert = moe_model_layer.block_sparse_moe.experts[expert_index]
expert.w1.weight.data.copy_(model_a_layer.mlp.gate_proj.weight.data)
expert.w2.weight.data.copy_(model_a_layer.mlp.down_proj.weight.data)
expert.w3.weight.data.copy_(model_a_layer.mlp.up_proj.weight.data)
# Copy layer normalization weights
moe_model_layer.input_layernorm.weight.data.copy_(model_a_layer.input_layernorm.weight.data)
moe_model_layer.post_attention_layernorm.weight.data.copy_(model_a_layer.post_attention_layernorm.weight.data)
# Finally, copy the lm_head weights
moe_model.lm_head.weight.data.copy_(model_a.lm_head.weight.data)
# copyweight
copy_weights_from_model_a_to_moe(model_a, moe_model, expert_index=0) # Replace 0 with the desired expert index
途中、32bit操作だと、システムメモリ200GB以上、必要としていました
このままでは大きすぎるので
16bitに変換して、完成したモデルを保存
model.to(torch.bfloat16)
moe_model.save_pretrained('path_to_save_model')推論!

・・・・・まあ予想通り、壊れました
注意機構だけ、MLP層だけ、コピーするエキスパート数を変更など実験しましたが、基本モデルが壊れました
エキスパート毎にファイチューニングできたら面白いのにな、と思ってましたが、そういった使い方は難しいですね
他のエキスパートとの関係や、ルーティングが無視できず、全体の学習がセットじゃないとダメなようです
その後、MOEについては下記で学べました
各エキスパートがどういう役割するかなど書いてありましたので、理解が進みました。

MoE とは一体何でしょうか?
変圧器モデルのコンテキストでは、MoE は 2 つの主要な要素で構成されます。密なフィードフォワード ネットワーク (FFN) 層の代わりに、疎な MoE 層が使用されます。MoE レイヤーには一定数の「エキスパート」(たとえば 8 人)があり、各エキスパートはニューラル ネットワークです。実際には、専門家は FFN ですが、より複雑なネットワークや MoE 自体になることもあり、階層的な MoE につながります。
どのトークンがどのエキスパートに送信されるかを決定するゲートネットワークまたはルーター。たとえば、以下の画像では、トークン「More」が 2 番目のエキスパートに送信され、トークン「Parameters」が最初のネットワークに送信されます。後で説明するように、トークンを複数のエキスパートに送信できます。トークンを専門家にルーティングする方法は、MoE と協力する場合の大きな決定の 1 つです - ルーターは学習されたパラメータで構成され、ネットワークの残りの部分と同時に事前トレーニングされます。
各エキスパートは何を専門とするのか?
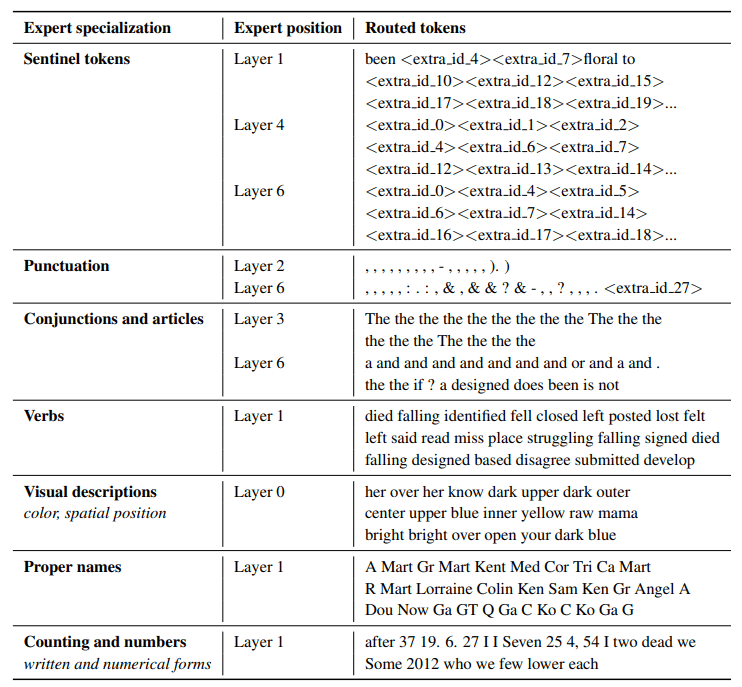
ST-MoEの著者は、エンコーダーの専門家がトークンのグループや浅い概念に特化していることを観察した。
例えば、句読点の専門家、固有名詞の専門家などである。
一方、デコーダーの専門家はあまり特化していない。
著者らはまた、多言語セットアップでトレーニングを行った。
各エキスパートはある言語に特化していると想像していたが、トークンのルーティングと負荷分散により、各言語に特化したエキスパートは存在しなかった。
各エキスパートは、日本語や英語など言語毎に特化しているわけではないんですね!
この記事が気に入ったらサポートをしてみませんか?