

#LangChain


OpenAIの新しいマルチエージェント用フレームワークSwarmを試す
Google ColabでSwarmを試したのでまとめました。
1. SwarmOpenAIが新しくマルチエージェント構築のためのフレームワークを作り始めました。まだ実験的なフレームワークで、本番環境での使用を想定していないようで、今の所かなりシンプルな仕組みに見えます。
エージェントの調整と実行を軽量で、制御性が高く、テストしやすいものにすることに重点を置いているようです。
2. Googl


AirLLM:405BのmodelをLocalで動かすと
去年の年末頃、比較的大きなLLMのmodelでも各層毎にGPUで計算することで少ないGPUメモリでも動かすことができるAirLLMが公開されました。
その方がLlama 3.1 405B modelを8GB VRAM以下で動作させていたので、試してみました。
概要Llama-3.1-405B
言わずもがな、Meta社の現在最高峰のオープンソース、多言語対応、128Kと長いコンテキスト長のmo


自動でプロンプトエンジニアリングする『APE(Automatic Prompt Engineering)』を試す。LangGraph
こんばんは、IZAIエンジニアリングチームです。今回は、自動プロンプトエンジニア(APE)についての論文のアイディアをもとに、遺伝的アルゴリズムチックにプロンプトを自動で調整する方法を試してみました。
APE(Automatic Prompt Engineering)とはAPEはAutomatic Prompt Engineeringの略で、その名の通り自動でプロンプトエンジニアリングを行うアル

LangChainを使った3つのLLM文書要約手法「Stuff, Map Reduce, Refine」を検証してみた。
こんにちは!株式会社IZAI、エンジニアチームです。
今回は、LLMのタスクとして活用の場面が多い文章要約の3つの手法「Stuff, Map Reduce, Refine」について検証して、その精度を比較していきます。
LangChainとは?LangChainとは自然言語処理の分野で活躍を期待されているオープンソースのライブラリで、チャットボットや自動要約アプリなどのAIアプリケーションの開発



LangChain で RAGのハイブリッド検索 を試す
「LangChain」でRAGのハイブリッド検索を試したので、まとめました。
1. RAGのハイブリッド検索「RAG」のハイブリッド検索は、複数の検索方法を組み合わせる手法で、主に「ベクトル検索」と「キーワード検索」を組み合わせて使います。
2. LangChainの準備LangChainの準備の手順は、次のとおりです。
(1) LangChainのパッケージのインストール。
# Lang


RAG技術の新たな展開:文書間コンテキストの活用とその影響
LangChainチームの@Lance Martinが最近公開したビデオシリーズでは、大規模言語モデル(LLM)とRetrieval Augmented Generation(RAG)技術の進化について詳しく説明されています。このビデオでは、特に多くの文書からコンテキストを必要とする問いに対応するためのRAPTORのアプローチや、長いコンテキスト埋め込み技術、自己反射型RAGやC-RAGなどの新た
もっとみる

生成AI新年会2024で「AIエージェントとLangChain」について話しました
LangChainエコシステムの盛り上がり昨年の3月ぐらいから「もくもくLangChain」と称したLangChain推し活動を続けていますが、昨年年末にかけてLangChain関連書籍が多数出版されていたり、SoftwareDesign誌でのLLMアプリケーション開発に関する連載も好調だったりと、LangChain周辺のエコシステムは継続して盛り上がり続けているのではないかと感じています。
![[活用例]Local-LLM+Topic model+Langchain+ChromaDB](https://assets.st-note.com/production/uploads/images/125226437/rectangle_large_type_2_ffdcc0de4669aecf99c1fb4f9af87c37.png?width=800)
[活用例]Local-LLM+Topic model+Langchain+ChromaDB
今回は集めた特許データをTopic modelで分類し、分類したtopicごとにChromaDBでデータベースを作成、Langchainを使ってRAGを設定し、Local-LLMに回答してもらうフローを整理しました。
フローは上のイメージ図の通り、下記の手順で進めます。
1. 特許からコンセプトを抽出
2. 抽出したコンセプトを分類
3. トピック毎にデータベースを作成
4. RAGの設定
LangChain の Tavily Serch API を試す
「LangChain」の「Tavily Serch API」を試したので、まとめました。
1. Tavily「Tavily」は、AIエージェント専用に構築された検索エンジンです。AIの機能を強化し、リアルタイムで正確かつ事実に基づいた結果を迅速に提供します。「Search API」を使用することで、AIエージェントが信頼できるリアルタイムな知識を取得できるようになり、ハルシネーションや偏見を軽減

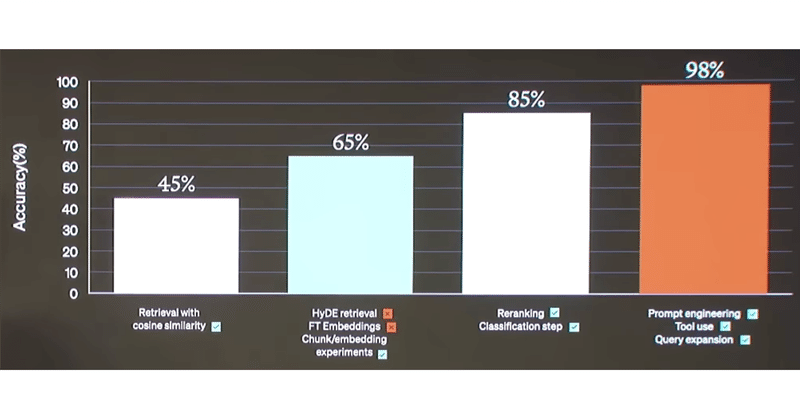
LangChain への OpenAIのRAG戦略の適用
以下の記事が面白かったので、かるくまとめました。
1. はじめに「Open AI」はデモデーで一連のRAG実験を報告しました。評価指標はアプリケーションによって異なりますが、何が機能し、何が機能しなかったかを確認するのは興味深いことです。以下では、各手法を説明し、それぞれを自分で実装する方法を示します。アプリケーションでのこれらの方法を理解する能力は非常に重要です。問題が異なれば異なる検索手法が


LangChainでストリーミングを有効にしつつ、会話やRAGのトークン消費数を計測する方法
はじめにこんにちは、@_mkazutakaと申します。今日は、LangChainでストリーミングを有効にしつつ、会話やRAGのトークン消費数を計測する方法について紹介します。
LangChainを使用するときのトークン消費量は、以下のドキュメントに記載されているように `get_openai_callback` 関数を利用すれば簡単に取得できます。しかしこれには注意点があり、この関数はストリーミ

LangChainとFastAPIのストリーミング機能を使って、ChatGPTで生成したテキストをAPIでリアルタイム送信する方法
こんな動作をするAPIの話。
LangChainの以下のIssueでも取り上げられていたのでメモです。
ソースコードimport threadingimport queueimport uvicornfrom fastapi import FastAPIfrom fastapi.responses import StreamingResponsefrom langchain.chat_mode