[memo]Knowledge Graph&Baseの作成
Knowledge Graph&Base(KG, KB)の作成事例の紹介も兼ねたメモです。
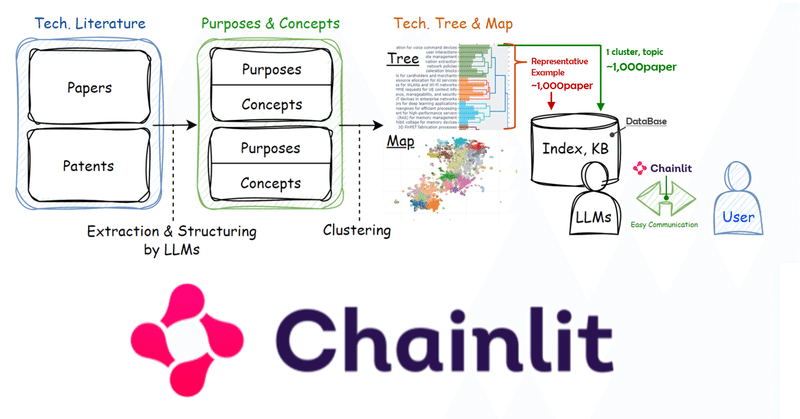
wikipedia、newspaper、GoogleNewsから取得したtext情報からREBELでのKG, KBの作成方法です。
下記で紹介する記事では、
・ 単純なtextからのKB作成
・ 異なる表記で同じ意味の項目の統合
・ Web上のニュース記事からのKB作成
・ 複数記事からのKB作成
と順に説明されており、非常にわかりやすいです。
0. 参考記事
1. REBEL