
Local PCに専門家を作る_Local-LLM+Document Summary Index

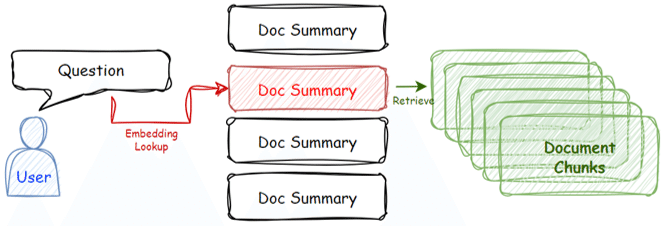
下記の通常のRAGに対し、LlamaindexのDocument Summary Indexを用いた事例です。
検索に要約文を用い、検索速度をあげつつ、要約文に質問例を追加することでembeddingでの検索の精度をあげることができます。

今回も前回同様に、専門知識が論文や特許になっているような、所謂「研究者」のような専門家チャットAIの実装を試みます。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
1. 知識の収集・格納
今回はarXivで取得したPDFをフォルダに格納しました。
検索した単語は"Superconductor"(超伝導体)です。
2. PDF ⇒ SummaryIndex
フォルダに入っているPDFファイルのtext情報を使用します。質疑に用いるLLMのモデルはHuggingFaceH4/zephyr-7b-betaです。
# フォルダのパス
path = r".\Superconductor"
# データの読込み
from llama_index.node_parser import SimpleNodeParser
from llama_index import (
SimpleDirectoryReader,
ServiceContext,
get_response_synthesizer,
)
from llama_index.indices.document_summary import DocumentSummaryIndex
documents = SimpleDirectoryReader(path).load_data()
# LLMのモデル指定
import torch
from llama_index.llms import HuggingFaceLLM
from llama_index import ServiceContext
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
# context_window=2048,
# max_new_tokens=512,
model_kwargs={"torch_dtype": torch.bfloat16},
generate_kwargs={"temperature": 0.1, "do_sample":True,},
device_map="auto",
)
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=1024)DocumentSummaryIndexの設定
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize", use_async=True
)
doc_summary_index = DocumentSummaryIndex.from_documents(
documents,
service_context=service_context,
response_synthesizer=response_synthesizer,
show_progress=True,
)3. indexの保存
作成したindexをいつでも使えるように保存しておきます。
doc_summary_index.storage_context.persist("index")4. indexの読込
# load
from llama_index.indices.loading import load_index_from_storage
from llama_index import StorageContext
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="index")
doc_summary_index = load_index_from_storage(storage_context)5. 質疑
クエリエンジンの設定
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize", use_async=True
)質問
question = "What are some of the models and theories related to holographic superconductors?"
response = query_engine.query(question)
print(response)Some of the models and theories related to holographic superconductors include the Chandrasekhar-Clogston (CC) bound, the LOFF phase, and the interaction between electric and spin motive forces. Additionally, there are models that involve complex and strongly correlated electronic interaction mechanisms, such as the emergence of PTs associated with different order parameters and the formation of scalar hair on fixed black hole space-time backgrounds. These models aim to provide a dual description of multi-band superconductors and explore the influence of new interactions between gauge fields.
(機械翻訳)
質問:ホログラフィック超伝導体に関するモデルや理論にはどのようなものがありますか?
回答:ホログラフィック超伝導体に関連するモデルや理論には、チャンドラセカール-クロッグストン(CC)束縛、LOFF相、電気力とスピン起電力の相互作用などがあります。さらに、異なる秩序パラメータに関連したPTの出現や、固定されたブラックホール時空背景上でのスカラーヘアーの形成など、複雑で相関の強い電子相互作用メカニズムを含むモデルもある。これらのモデルは、マルチバンド超伝導体の二重記述を提供し、ゲージ場間の新しい相互作用の影響を探ることを目的としている。
Embeddingベース検索を使ったクエリエンジンの設定
from llama_index.indices.document_summary import (
DocumentSummaryIndexEmbeddingRetriever,
)
retriever = DocumentSummaryIndexEmbeddingRetriever(
doc_summary_index,
similarity_top_k=3,
)
from llama_index.query_engine import RetrieverQueryEngine
response_synthesizer = get_response_synthesizer(response_mode="tree_summarize")
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)質疑
response = query_engine.query(question)
print(response)Some of the models and theories related to holographic superconductors include the Chandrasekhar-Clogston (CC) bound, the LOFF phase, and the AdS/CFT correspondence.
(機械翻訳)
ホログラフィック超伝導体に関連するモデルや理論には、チャンドラセカール-クロッグストン(CC)束縛、LOFF相、AdS/CFT対応などがある。
別の質問と回答(機械翻訳)
質問:(3+1)Dと(2+1)Dのトポロジカル相はどのように分類されるのか?
回答:(3+1)Dと(2+1)Dのトポロジカル位相は、対称群、モジュラーテンソルカテゴリーの性質、アノマリー指標公式に基づいて分類される。アベリアンボソニックトポロジカル相については、時間反転不変性に適合する(Θ, c-)の選択によって分類が決まります。アベリアンフェルミオン的トポロジカル相は、対称性クラス(AIIまたはAIII)とPin〜c+またはPinc構造に基づいて分類される。非アベリアン位相の分類はまだ未解決の問題である。様々な4多様体上の経路積分によって得られるアノマリー指標公式を用いて、与えられた(2+1)Dの位相幾何学的次数で大域的対称性を持つ't Hooftアノマリーの有無を示す。作用における分割関数と連続シータ項も、これらの位相の分類を決定する役割を果たす。
6. まとめ
この方法では~300本くらいの文献であれば比較的現実的な範囲のように感じています。200本くらいあれば一研究室の主な論文、一分野の主なレビュー論文はカバーできそうです。