
OpenGPTs への長期記憶の追加

以下の記事が面白かったので、かるくまとめました。
1. LLMはステートレス
LLMはステートレスです。最初の入力を渡し、次に2番目の入力を渡すと、最初の入力は記憶していません。
その最初の例外は、数週間前にOpenAIがリリースした「Assistant API」です。これを使用すると、メッセージリストを追跡できます。その後、このメッセージリストのアシスタント(LLM)を呼び出すと、そのスレッドにメッセージが追加されます。LLM自体はステートレスですが、公開されたAPIはステートレスではありません。
2.長期記憶
2-1. Conversation Memory
「Conversation Memory」は、会話中に以前のメッセージを覚える能力を意味します。これは、以前のメッセージリストを追跡し、それをLLMに渡すことによって行われます。
これは、メッセージリストが長くなると問題が発生します。第1に、メッセージリストが十分に長くなると、コンテキストウィンドウよりも長くなる可能性があります。第2に、コンテキストウィンドウがオーバーフローしなくても、LLMがすべてのメッセージにきちんと目を通すには多すぎるほどの長さになる可能性があります(長いコンテキストウィンドウの制限に関してはGreg Kamradtの研究が参考になります)。
これに対処する最も簡単な方法は、N個の最新メッセージのみを使用することです。これは長期記憶の欠如の欠点につながります。

2-2. Semantic Memory
「Semantic Memory」は、おそらく次に一般的に使用されるメモリです。これは、現在のメッセージに似たメッセージを見つけて、何らかの方法でプロンプトに追加することを指します。
これは通常、各メッセージの「埋め込み」を計算し、同様の「埋め込み」を持つ他のメッセージを見つけることによって行われます。これは基本的に、「RAG」(Retrieval Augmentation Generation)と同じです。ただし、文書を検索する代わりに、メッセージを検索しています。
たとえば、ユーザーが「私のお気に入りの果物は何ですか」と尋ねると、「私のお気に入りの果物はブルーベリーです」(「埋め込み」の距離が近いため) のような過去のメッセージが見つかるかもしれません。その後、前のメッセージをコンテキストとして渡すことができます。
しかし、このアプローチにはいくつかの欠陥があります。
第1に、洞察や情報が複数のメッセージに分散されている場合、適切なメッセージが取得されない可能性があります。
AI : あなたの好きな果物は何ですか?
Human : ブルーベリー
適切な情報を得るためには、これら両方のメッセージを取得する必要があります。
第2に、時間を考慮していません。好みや事実は時間の経過とともに変化する可能性があります。
第3に、必要なメモリの種別について比較的無頓着であることです。これは、AGIには向いているかもしれませんが、実際に機能する焦点を絞ったアプリの開発には向いていません。
2-3. Generative Agents
「Generative Agents」は、1年ほど前に出た素晴らしい論文であり、最も興味深い高度なメモリ作業のいくつかを行います。その論文を見て、上記の課題のいくつかにどのように取り組んでいるかを見る価値があります。
「Generative Agents」では、さまざまな技術を使用してメモリを構築します。
・Recency : 最近のメッセージを取得 (会話メモリとタイムスタンプに基づくメッセージの重み付け)
・Relevancy : 関連するメッセージを取得(意味記憶)
・Reflection : LLMを使用してメッセージをリフレクションして取得
第1の問題は、「Reflection」が役立ちます。情報が複数のメッセージに分散されている場合、複数のメッセージを反映させた合成メッセージを生成することで解決します。
第2の問題は、「Recency」の重み付けによって部分的に解決されます。しかし、完全には解決されていない可能性が高いです。
第3の問題は実際には対処されていませんが、これはまだかなり一般的なメモリ形式です(しかし、それは大丈夫です、それが目指していたことです)。
3. 長期記憶の抽象化
長期記憶について考えるとき、最も一般的な抽象化は次のとおりです。
・時間の経過とともに追跡されるステートが存在
・ステートはある時期に更新される
・ステートは何らかの形でプロンプトに組み合わされる
関連する質問は、次のようになります。
(1) 追跡されているステートは何か?
(2) ステートはどのように更新されているか?
(3) ステートはどのように使用されているか?
上記の3種のメモリがどのように機能するかを見ていきます。
3-1. Conversation Memory
(1) 追跡されるステートはメッセージリスト
(2) ステートは各ターン後に最近のメッセージを追加することで更新
(3) ステートはプロンプトにメッセージを挿入することでプロンプトに結合
3-2. Semantic Memory
(1) 追跡されるステートはメッセージのベクトルストア
(2) ステートは各ターン後にメッセージをベクトル化して挿入することによって更新
(3) ステートは各ターン後に同様のメッセージを照会することでプロンプトに結合
3-3. Generative Agents
(1) 追跡されるステートは、メモリのベクトルストアと、最新メモリのリスト
(2) ステートは以下の方法で更新
・ターン毎に新しいメモリを最新メモリのリストに挿入
・そのメモリの埋め込みを計算
・Nターン毎に、最近のメモリのリフレクションを生成し、リストとベクトルストアの両方に挿入
(3) ステートは最新性と関連性の重み付けに基づいてメモリ (またはメモリのリフレクション) を選択してプロンプトに結合
4. アプリケーション固有のメモリ
上記のメモリはすべて一般的で、AGIを構築しようとしているなら、素晴らしいことです。しかし、より狭いアプリを構築しようとしている場合、信頼性とパフォーマンスが低下します。
メモリは「認知アーキテクチャ」の一部です。「認知アーキテクチャ」と同様に、実際には、よりアプリケーション固有のメモリがアプリの信頼性とパフォーマンスを向上させるのに役立ちます。
したがって、アプリを構築するときは、上記の質問をすることが重要になります。
(1) 追跡されているステートは何か?
(2) ステートはどのように更新されているか?
(3) ステートはどのように使用されているか?
「Dangeon and Dragons」のダンジョンマスターとして確実に機能するチャットボットの構築を例に解説します。
4-1. 長期記憶の抽象化
(1) 追跡されているステートは何か?
はじめに、ゲームに関与しているキャラクターを確実に追跡したいと考えました。 彼らが誰なのか、彼らの説明など。これは知るべきことのように思えます。 これをcharacterメモリと呼びます。
次に、ゲーム自体のステートも追跡したいと考えました。それまでに何が起こったのか、どこにいたのかなど。これをquestメモリと呼んでいます。
私たちはこれを2つの異なるものに分割することにしました。そのため、実際にはcharacter と quest という2つの異なるステートの更新を追跡していました。
(2) ステートはどのように更新されているか?
character については、最初に一度だけ更新したいと考えていました。そのため、チャットボットがすべての関連情報を収集し、そのステートを更新し、その後は2度と更新されないようにしたいと考えました。
その後、チャットボットが毎ターン quest のステートを更新できるようにしたいと考えました。更新が必要ないと判断した場合は更新しません。それ以外の場合は、quest の現在のステートをLLMで生成された新しいステートでオーバーライドします。
(3) ステートはどのように使用されているか?
character と quest の両方が常にプロンプトに挿入されるようにしたいと考えていました。どちらもテキストであるため、これは非常に簡単です。
4-2. 認知アーキテクチャ
このチャットボットでは、一般的なエージェントとはわずかに異なる「認知アーキテクチャ」を使用しました。つまり、「State Machine」を使用しました。 チャットボットは次の2つのステートのいずれかにありました。
・キャラクター構築状態 : ユーザーのキャラクターに関する情報を収集する
・クエストモードの状態 : クエストを進行中
これら2つのステートの遷移は、LLMがプレイヤーのキャラクターを十分に収集したと判断したときに発生します。それが発生すると、characterメモリが更新されます。characterメモリの存在は、チャットボットがquestを伝える状態にあるべきであることを示す標識として機能します。
4-2. 動作の確認
これが実際に動作しているのを確認するには、「OpenGPTs」のデプロイバージョンに移動します。事前に作成されたボットはここで見つけることができます。ソースコードはここで見ることができます。
このタイプのメモリを使用して「Dangeon and Dragons」チャットボットを最初から作成したい場合は、新しいボットを作成するときに、dungeons_and_dragons タイプを選択できます。

メッセージを送信すると、まずキャラクターに関する情報をインタビューします。

十分な情報が得られると、それを CharacterNotebook (characterメモリ) に保存します。
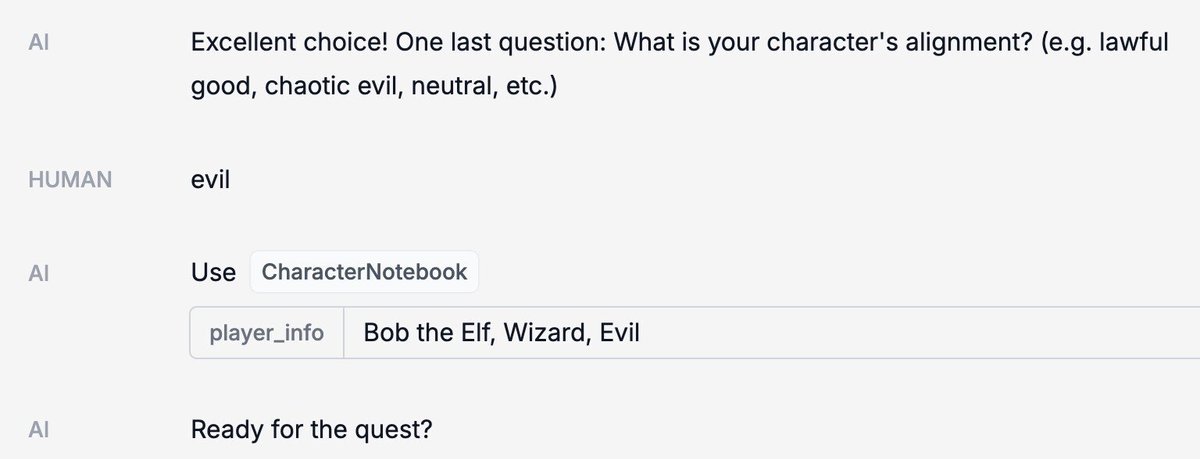
その後、クエストに導かれます。 さまざまな時点で、StateNotebook (questメモリ) が更新されます。

すべてが「LangSmith」に記録されるため、裏で何が起こっているかを確認できます。

これは完璧ではないことに注意してください。 時間の経過とともにクエストの更新を改善するために、早急なエンジニアリングを行う必要があることは間違いありません。 それでも、これが長期記憶についての考え方およびカスタム実装の1つとして役立つことを願っています。
この記事が気に入ったらサポートをしてみませんか?