
『最強のAI』Stable Diffusion 3 を無料で使おう❗ComfyUI、Google Colabでの簡単利用方法を解説✨✨ADetailerと一緒にも使えます⭕

どうも、皆さん!スニーカーを履いてもどこかに行く気がしない、家にこもりがちな葉加瀬あいです!
2024年4月18日、画像生成AIの世界に激震が走りました!
なんと、英国のStability AIが開発した最新の画像生成AIモデル「Stable Diffusion 3」のAPIが公開されたんです!✨✨
つまり、Stable Diffusion 3の画像生成が、開発者向けに利用できるようになったということなんですよね!
(この記事では、プログラミングなどの技術的な知識がない方でも使えるように、わかりやすく解説していきます!)
Twitterでは、早速Stable Diffusion 3を使って様々な画像を生成している投稿が見られます!
品質の高さに驚きの声が上がっていますね!
(やっぱり最強の画像生成AIという声もあって、品質はとても素晴らしいですね!)

開発者向けに使えるようになったということをもう少し詳しく説明すると、要はAPIでの利用ができるようになった形になります!
APIでの利用が可能になったということは、ソースコードを書いてAPIキーを入力し実行することで、Stable Diffusion 3が利用できるようになったということなんです。
でも正直なところ、プログラミングなどに詳しくない方が多いのも事実ですよね...。
今回のこの技術、すごくとても注目すべき技術で、知っておかないと絶対に損をするので、今回はそういった方のために技術的な知見がなくても、Stable Diffusion 3の画像生成を行える方法を詳しく解説していきたいと思います!
⚠️私の記事を読む上での注意事項⚠️
なお、私の記事を読む上での注意事項などをこちらで説明しておりますので、以下のプロフィール記事をご一読いただいた上で閲覧するようお願いいたします。
それでは、早速続きを解説していきたいと思います!
Stable Diffusion 3とは?最新の画像生成AIモデルを解説
ところで、そもそも Stable Diffusion 3って皆さんご存知ですかね?
もしかしたら、ご存知ない方もいらっしゃるかもしれませんね。
この技術、とてもとても重要で、今後必須となる技術なので、よくわからない方はぜひこの機会に理解を深めていただければと思います!
簡単に説明すると、Stable Diffusion 3は、Stable Diffusionシリーズを開発しているStabilityAIが生み出した最新の画像生成AIモデルです。
現時点で最強の性能を誇ると、多くの専門家が口をそろえて言っているんですよ!
例えば、こんなすごい画像が生成できるんです!


本当に凄いですよね。これ…
鏡に写る画像の生成は、これまでのAIにとって非常に難しいとされてきました。
でも、ご覧の通り、StableDiffusion 3では難なくクリアしています!
しかも、その画質は、高品質な画像生成で話題のMidjourney V6と同等かそれ以上…
(MidjourneyV6についてよくわからない方は、こちらの記事を参考にしてみてくださいね。)
つまり、Stable Diffusion 3は、DALL-E3やMidjourney V6といった最新の画像生成AIと同等以上の高品質な画像を生成できるということなんです!

Midjourney V6やDALL-E 3の利用においては月額料金が掛かりますが、Stable Diffusion 3 は無料で使用することができるようになるとのことで、そういった意味でもとても注目されているんです!
(Midjourney V6 は実写レベルのすごいきれいな画像を生成できるんですけど、Stable Diffusion ほど拡張性がなかったり、年間で約1万5000円の費用がかかったりしています。この費用がまるまる無料になるので、それはそれで嬉しいですよね!)
Stable Diffusion 3の特徴 - 幅広いカスタマイズ性が魅力
Stable Diffusion 3がMidjourney V6やDALL-E 3と比べて優れているのは、高品質な画像生成ができるだけではありません!
その最大の特徴は、幅広いカスタマイズ性にあります。LoRAやControlNet、ComfyUIなど、様々な拡張機能を使って画像生成をどんどんカスタマイズできるんです!

つまり、Stable Diffusion 3で超高品質な画像を生成し、それを自在に編集できるわけです。例えば、LoRAで特定の人物の顔を再現したり、ControlNetで絵画風のスタイルを適用したり、ComfyUIで動画生成もできたりと、応用範囲は無限大ですね!
Stable Diffusion 3が得意とする画像の種類
Stable Diffusion 3の凄さは、実写画像だけではありません。アニメ調の画像生成も非常に得意なんです!


実際に、LoRAを使ってデルタモンというキャラクターを作成した方もいらっしゃいましたね!

さらに驚くべきは、これまでの画像生成AIが苦手としていた手の描写も、Stable Diffusion 3では見事に再現できているんです!

さらに、文字の生成だってお手の物です。

本当に凄すぎますよね…。
このように高性能で、これまでのAIの課題を解決するStable Diffusion 3は、間違いなく今後のゲームチェンジャーになると、多くの著名人も注目しています。
私のこれまで数多くのAIプロジェクトに携わったり、企業のコンサルをしたりしてりしてきて、このAI業界では仲良くお付き合いさせていただいている方も多いのですが、私の周りでも、Stable Diffusion 3への期待は非常に高い印象ですね!
Stable Diffusion 3はオープンソースで無料公開予定
さらに驚くべきことに、Stability AIはStable Diffusion 3をオープンソースで公開する予定だそうです!
つまり、誰でも無料で利用できるようになるんですよ!
そういった意味でも、この技術について皆さんに知ってもらいたくて私もこちらの記事で解説をしているので、もっと詳しく知りたい方は、ぜひこちらの記事をチェックしてみてくださいね!
また、ノートの記事を読んだりする時間がない方も中にはいますよね…
そのような方のために、私のノートでは記事の内容を動画でも解説しています!
普段はメンバーシップ限定で公開しているのですが、Stable Diffusion 3については、特別に誰でも視聴できるようにしていますので、ぜひこちらのリンクから動画をご覧ください。
なお、私のメンバーシップでは、このようにノートの記載内容を動画で確認できるようにしております!
つまりは、通勤等の移動中は動画で確認をして、AI技術を触れるときは、実際にノートの記事を読みながら、自分のペースでキャッチアップできるといった形です!
技術の悪用を懸念してメンバーシップ制にしているのですが、高校生でも利用できる設定にしていますし、この記事を見つけてくれた情報感度の高い皆さんのために、費用対効果の高い有益な情報提供をしているので、興味がある方は、メンバーシップの内容についても、以下のリンクからぜひ見てみてください!
顔の修復機能で生成画像の品質をさらに向上
現在、Stable Diffusion 3を使うには、公式が提供するAPIを利用します。
ただ、生成される画像のアスペクト比によっては、顔が崩れてしまうことがあるようです。
そこで今回は、Stable Diffusion 3による画像生成と一緒に顔の修復もしてくれるワークフローをご紹介します!
この記事では、そういった使い方を詳しく解説していきますので、興味のある方は、ぜひメンバーシップに登録して最後までチェックしてくださいね!
それでは、続きを解説していきます!
StabilityAIのアカウント登録
Stable Diffusion3の画像生成方法について、初心者の方でもわかりやすく解説していきますね!
まずは、StabilityAIのアカウント登録から行いましょう!これは、Stable DiffusionのAPIを使用するのに必要な設定となります。以下のURLから登録を行ってください。
具体的には、(こちらの画像)のように、ログインをクリックしてください。

その後、Googleなどでサインアップを行います。

ここまでできたら、後は普通にGoogleのOAuth認証(アカウントの連携)で登録すれば大丈夫です!
登録できたら、右上のご自身のアイコンボタンをクリックします。
すると、(こちらの画像)のようにAPIキーが表示されますので、コピーボタンをクリックして、APIキーをクリップボードにコピーしてください! (このAPIキーは絶対に他の人には見せないようにお願いします。)

また、APIキーは以下のURLから直接確認することも可能です。
https://platform.stability.ai/account/keys
APIを使用した画像生成では、(こちらの画像)のようにクレジットが消費されていきます。登録時にいくらかクレジットが反映されているはずなので、そちらの確認もお願いします。

つまり、Stable Diffusion 3のAPIを使って画像生成を行う場合、このクレジットが消費されるということですね!
消費量は以下の通りです。(チケット=画像1枚分)
SD3: 6.5ポイント/チケット
SD3 ターボ: 4ポイント/チケット
ComfyUIでの使用
画像生成の方法としては、Google Colabを使う方法とComfyUIを使う方法がありますが、今回は拡張性を考えてComfyUIで使用する方法を見ていきましょう!(Google Colabの方が簡単ですが、コーディングが面倒なんですよね。)
ComfyUIを無料で使う方法などは、私のこちらの記事で解説しています。
https://note.com/ai_hakase/n/ne08c4daf6971?magazine_key=m8e1b089bc489
ComfyUIの基本的な使い方については、はかな鳥さんの解説記事がわかりやすくまとめられているのでおすすめです。
もし使い方について、もっと詳しく知りたいと言った方は、こちらをご確認するのが良いかと思います! (私もかなり勉強になりました。はかな鳥さん、ありがとうございます🙏)
https://note.com/hcanadli12345/n/nc3b95d3e1764#37ae88ec-f6bd-49c8-b9bb-94a2bc3c3926
ここからは、私のこちらのノートで解説している拡張機能がインストールされていることを前提に進めていきます。まだ読まれていない方は、記事中で紹介されているComfyUIのワークフローをインストールした状態にしておいてください。
https://note.com/ai_hakase/n/n1e50f38c7678?magazine_key=ma5812eb86d3b
また、ComfyUIは最新版にアップデートしておくことをおすすめします!
ワークフローのダウンロード
使用するComfyUIのワークフローはこちらです。
これは、Stable Diffusion 3のAPIを使ってComfyUIで画像生成ができるワークフローになります!
URLに移動したら、右側のダウンロードボタンをクリックしてワークフローをダウンロードしてください。

ダウンロードしたら、ComfyUIを開き、(こちらの画像)のようにダウンロードしたワークフロー(.jsonファイル)をドラッグ&ドロップします。すると、このような画面になるはずです。

赤くなっている部分は、ワークフローの」インストール時点でまだ適用されていない拡張機能を使用したノードがあることを示しています。つまり、インストールすべき拡張機能がインストールされていないので、それをインストールする必要があります。
その場合は、(こちらの画像)のように、メニューアイコンをクリックし、「Install Missing Custom Nodes」をクリックしてください。

その後、(こちらの画像)のように、インストールされていないカスタムノードにすべてチェックを入れ、インストールボタンをクリックします。

すると、不足している拡張機能がインストールされるので、インストールが終わったらComfyUIを一度閉じて再起動してください。
再起動後、(こちらの画像)のような画面になっているはずです。
ワークフローの解説
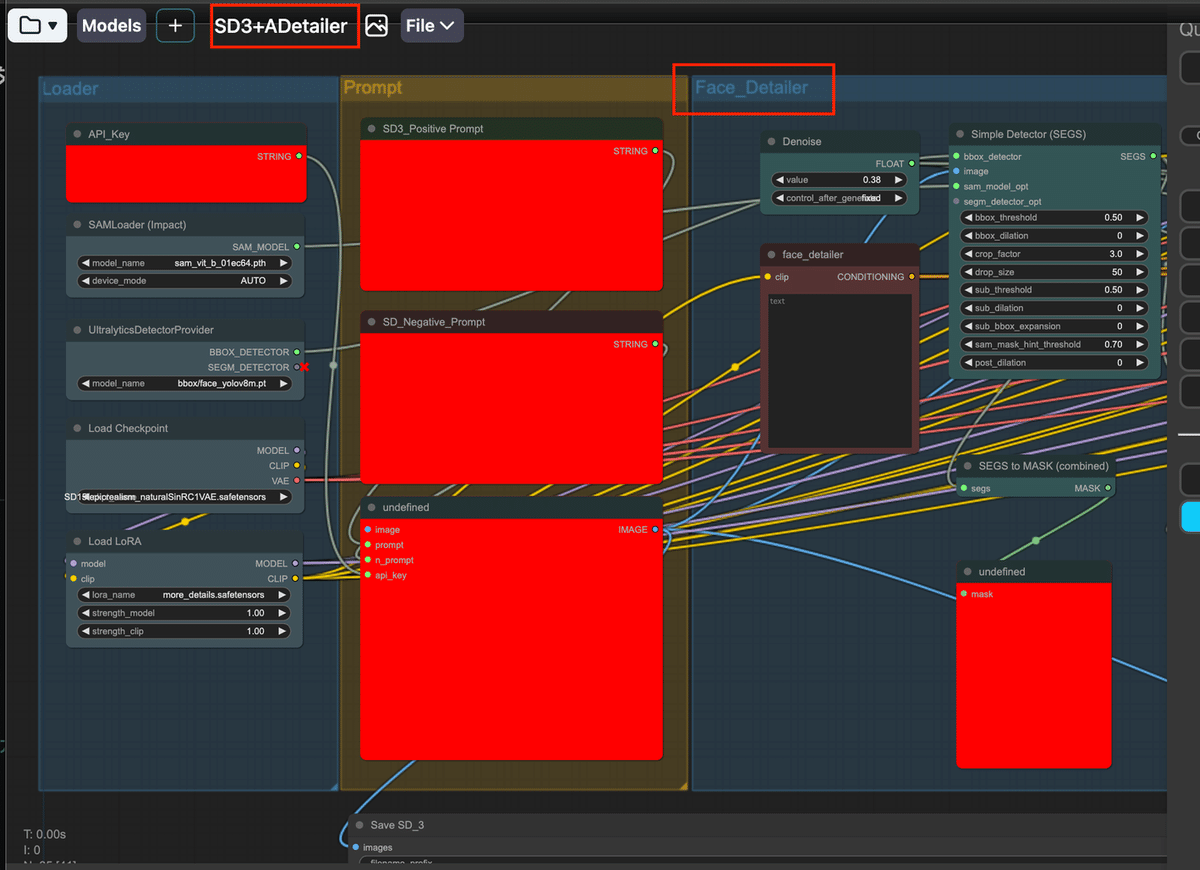
このワークフローは大きく3つの構成に分かれています。

1つ目は、プロンプトやチェックポイントの設定をする場所で、ここにAPIなどを入力しておきます。APIは先ほどのStability AIの会員登録時に取得したものです。

その他のチェックポイントやLoRAは、Face Detailerを使用する際の設定なので、画像生成に直接関わるというよりは、Stable Diffusion 3で生成した画像の顔を修正する際に関わってきます。そこまで重要な項目ではないので、好きなものを設定して大丈夫です。
2つ目は、(こちらの画像)のようにFace Detailerで顔の修正を行っている箇所です。つまり、Stable Diffusion 3で生成した画像の顔の修復作業を行っているということですね。

3つ目は、(こちらの画像)のように生成した画像を表示したり保存する場所です。左側がStable Diffusion 3で生成した画像で、右側がそれに顔の修復を加えたものになります。

ここまでできたら、好きなプロンプトを入れて画像作成を行ってみてください!
実際に画像生成を行うと(こちらの画像)のようになります。顔の修復による違いがわかりますでしょうか?

リアルな画像を生成しようとしてプロンプトを調整すると、(こちらの画像)のようになります!

つまり、アニメ調であれば、アニメーション的な画質でより忠実に表現しようとし、リアル系であれば実写的な画質でとても忠実に表現されるんですよね!
さらに、冒頭でも解説したのですが、Stable Diffusion 3では、従来モデルでは困難だった文字を含む画像の生成が可能になっており、様々なアスペクト比のテキスト生成画像にも対応しています。
(こちらの画像)を見てみてください!

このように、Stable Diffusion 3では画像だけでなく、文字の生成もとても得意なんです!
それで、今までアスペクト比に関しては、大体画像生成できる幅が決まっていました。
例えば、Twitterのヘッダーのような9対21の比率の、縦や横に長い画像は生成するのが難しかったんですよね。
しかし、Stable Diffusion 3では、(こちらの画像)のように、様々なアスペクト比の画像生成にも対応しています!

Stable Diffusion 3の今後の動向
Stable Diffusion 3の今後の動向としては、将来的には、Stability AIメンバーシップでモデルを自社サーバでホスティングできるようになる予定とのことです。
つまり、まずはStability AIのメンバーシップで使えるようにしていくということですね!
ゆくゆくは、オープンソースですべてのモデルを公開して、みんなが無料でStable Diffusion 3のモデルを使用できるようになるみたいです!
現在は悪用防止のため一般公開は見送られていますが、研究者や専門家、コミュニティと協力してモデルを改善していく方針とのことです。
発表がとても楽しみですね!
Stable Diffusion 3に関連するリンク
以下に、Stable Diffusion 3に関連するリンクを紹介しますので、詳細が気になる方はぜひご覧ください!
Stable Diffusion 3 APIの紹介ブログ: https://ja.stability.ai/blog/stable-diffusion-3-api
Stability AIメンバーシップ: https://stability.ai/membership
Stable Diffusion 3をすぐ試せるColabノートブック: https://colab.research.google.com/drive/1IsDIFmnbmQANDrR8lJTIh1rBvh09FI7d?usp=sharing
APIリファレンス:https://platform.stability.ai/docs/api-reference#tag/Generate
ComfyUIでのStable Diffusion 3 API使用方法:
https://platform.stability.ai/docs/api-reference#tag/Generate
まとめ
Stable Diffusion3のAPIが公開されたのは本当に大きなニュースですね!
これからは誰でも高品質な画像生成ができるようになるのが楽しみです。
Stable Diffusion3の特徴をまとめると以下のようになります:
現時点で最強クラスの画像生成品質。
Midjourney V6やDALL-E 3と同等かそれ以上の高画質画像が生成可能
鏡に写った画像など、これまで画像生成AIが苦手としていた表現も難なくこなせる
将来的には無料で誰でも使えるオープンソースモデルとして公開予定
文字を含む画像生成や様々なアスペクト比の画像生成にも対応
ただ、現時点ではAPIでの利用のみで、プログラミングの知識が必要なのが難点ですね。
でも、この記事ではプログラミングの知識がなくてもStable Diffusion3を使える方法を丁寧に解説してくみました!
具体的には、Stability AIのアカウント登録とAPIキーの取得方法、そしてComfyUIというツールを使った具体的な画像生成方法ですね。
Stable Diffusion3は本当に画期的な技術なので、この機会にぜひ使い方をマスターしておきたいですね。今後さらなる発展が期待できるAIだと思います!
🎈おわりに
いかがだったでしょうか。以上で本稿の解説を終了します。
今後も生成AIに関する記事を投稿していく予定ですので、フォロー・いいね をいただけると非常に励みになります。
また、私のプロフィール記事に関しても是非一読ください。
また、私はこういった生成AI技術の解説以外にも、保護猫活動なども行っておりますので、日々の応援なども含め、少額でも下記のリンクからご支援いただけますと幸いです。
ここまでご覧いただきありがとうございました!充実した生成AIライフをお楽しみください!
🙌ご覧いただきありがとうございました!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?