

#AI

はじめてのキーポイント検出 by YOLO
やってみました。意外と楽しいのでシェア。
キーポイント検出とはキーポイント検出とは、画像や動画に現れる物体のランドマークを検出する行為です。ランドマークとは、間接、目、鼻など、物体中の重要部位のことです。
この技術を用いると、スポーツをしている人のフォーム分析や、料理をしている人の動きの特徴を分析することが可能となります。
YOLOv7 poseによるキーポイント検出の解説として、以下が分









Grounded-Segment-Anything(Grounded SAM)をWindows11+WLS2+Anacondaで試す
1.Grounded-Segment-Anythingとは、テキスト入力に基づいてあらゆる物体を検出し、セグメンテーションを行うことができる視覚AIシステム。
このシステムは、Grounding DINOとSegment Anythingを組み合わせることで、オープンワールドのシナリオにおいて多様な視覚タスクを実行する能力を持っています。
ユーザーがテキストで対象物を指定すると、システムはその物体


テキストプロンプトで切り抜くものを指定できるワークフレーム「Object Cutter」を試してみる
「Object Cutter」とはObject Cutterはテキストプロンプトだけで画像内のあらゆるオブジェクトに高品質の HD カットアウトを作成できます。手作業はまったく必要ないところがありがたいところ。
しかもオブジェクトは透明な背景で利用できるため、他の場所に貼り付けることができます。早速試してみたいと思います!
🌐プロジェクトページ💪さっそく試してみるそれでは早速試してみようとい

一瞬で綺麗なdepthを取ることができる「Depth Anything V2」を試してみる
Depth Anythingがバージョン2で復活!Depth Anything がバージョン 2 で復活しました。
現在の他の方法よりも 10 倍高速とのこと。すごい!
さまざまなサイズのモデル (2500 万から 13 億のパラメータ) が Huggingface Hub で入手可能になっています。
Depth Anything V2とは?Depth Anything V2はカメラ1台で撮影し
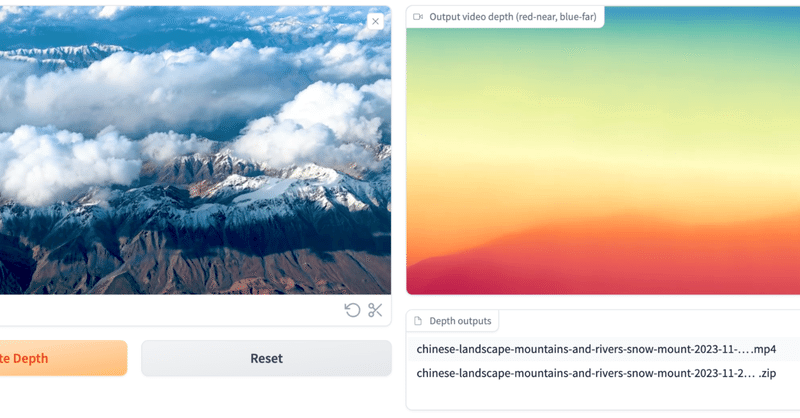
動画での深度推定AIの「ChronoDepth」を試してみる
「ChronoDepth」とはChronoDepthは超簡単に使える動画での深度推定AIツールです。
深度推定モデルをビデオに直接適用すると、フレーム間で不整合が生じる可能性がありますが、実際そういうちょっとした不整合でつかいものにならない残念さはクリエイターならみんな実感するとこと。
これはそういうこともなく簡単にできちゃうとのこと。ありがたや〜〜
なお、モデルはStable Video Dif



Google Colab で SAM 2 を試す
「Google Colab」で「SAM 2」を試したのでまとめました。
1. SAM 2「SAM 2」(Segment Anything Model 2) は、画像や動画のセグメンテーションを行うためのAIモデルです。目的のオブジェクトを示す情報 (XY座標など) が与えられた場合に、オブジェクトマスクを予測します。
具体的に何ができるかは、以下のデモページが参考になります。
2. セットア