

#論文



Label-Efficient Microscopy Image Recognition with Cell Image Characteristics
2023年度研究会推薦博士論文速報
[コンピュータビジョンとイメージメディア研究会]
西村 和也
(国立がん研究センター研究所 計算生命科学ユニット 特任研究員)
邦訳:細胞画像特性を用いたラベル効率の良い顕微鏡画像認識
【背景】深層学習により顕微鏡画像の認識が高精度に実現可能になった
【問題】深層学習には撮影環境毎に学習データが必要である
【貢献】細胞画像の特性を活用することにより学習デー




【論文要約:自動運転関連】Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
自動運転に関連する論文の要約をしています。
論文へのリンク:https://arxiv.org/abs/2407.16647
1. タイトル
原題: Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
和訳: 自動運転における魚眼画像の変形可能

【論文要約:自動運転関連】SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
自動運転に関連する論文の要約をしています。
論文へのリンク:https://arxiv.org/abs/2403.10353
1. タイトル
原題: SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
和訳: SimPB: 複数のカメラから2Dおよび3Dオブジェクト検出のための単一モデル
2.

【論文要約:自動運転関連】HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird’s Eye View
自動運転に関連する論文の要約をしています。
論文へのリンク:https://arxiv.org/abs/2307.13510
1. タイトル
原題: HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird’s Eye View
和訳: Height

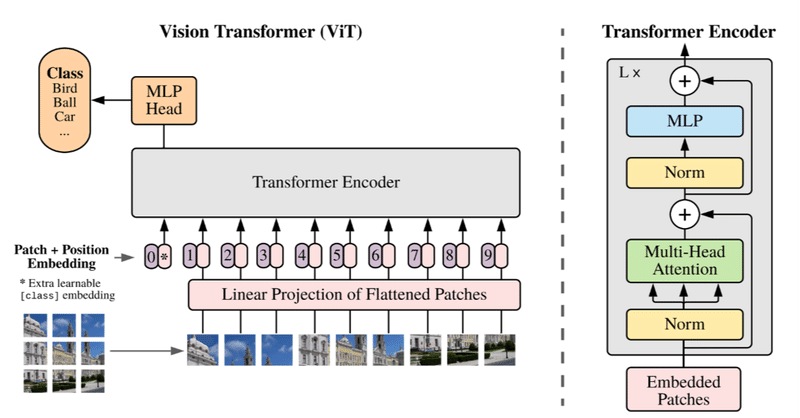
Computer Vision x Trasformerの最近の動向と見解
この記事についてこの記事では、Vision Transformer[1]登場以降のTransformer x Computer Visionの研究で、興味深い研究や洞察について述べていきます。この記事のテーマは以下の4つです。
• Transformerの急速な拡大と、その理由
• TransformerとCNNの視野や挙動の違い
• TransformerにSelf-Attentionは必須