
Uber徹底研究 -「続き」MaaSを支えるデータサイエンス編 レコメンド-

今回も前回に引き続き、Uberが使用するデータサイエンス、特にレコメンドについて紹介していきます。
前回、ご好評いただいた以下の記事を含め、まずはこれまでの連載をまとめておきます。
・Uber徹底研究 -ビジネス概要編-
・Uber徹底研究 -UX改善編-
・Uber徹底研究 -ゲーミフィケーション・行動科学編-
・Uber徹底研究 -MaaSを支えるデータサイエンス編-
■Uberがレコメンド?
そもそも、Uberがするレコメンドなんてあるの?という疑問を持たれる方もいらっしゃるかもしれません。レコメンドというとAmazonの「あなたにおすすめ」など商品を提示しているイメージを持たれる方も多いかと思います。それではUberは何をレコメンドするのでしょうか。
今回はUberが取り組むレコメンドを2つ紹介したいと思います。
はじめにUber Eatsでのレコメンドを紹介して(こちらがメイン)、次にFoursquareとのレコメンド連携による相乗効果を紹介します。
■Uber Eatsの世界トップレベルのレコメンデーション
最近都内ではUber Eatsをよく見かけるようになりました。
ご存知の方も多いと思いますが、Uber Eatsは自分が好きな飲食店の料理をアプリ上で注文し、その料理を家まで届けてくれるサービスです。お店の出前と異なるのは、配達してくれる人がUberEatsが抱えるパートタイムの労働者であることです。
このUber Eatsについて、最初にUber Eatsの構造を説明して、その後レコメンドの仕組みを紹介します。
■Uber Eatsの構造
Uber Eatsは以下の3つの関係者で構成されている3 side プラットフォームです。
①注文をする人 (Eater)
②レストランパートナー (Restaurant Partner)
③配達パートナー (Delivery Partner)
注文をする人はUber Eatsを通して好きな料理を探して注文します。
レストランパートナーは顧客を見つけるための販売チャネルとしてUber Eatsを使用します。
配達パートナーはレストランからの料理を注文者に届けることで収入を得ます。
なお、Uberは手数料としてレストランパートナーの売上の35%を受け取ります。
Uber Eatsのサービスを確実に提供するには、以上の全ての関係者の存在がか欠かせません。これらの関係者の需給バランスがうまくとれないと負のスパイラルが起こります。
注文をする人が充分にいない場合、レストラン側はUber Eatsには参加したくないでしょう。レストランの数が少ない場合は選択肢が少なくなり、Uber Eatsから注文する人が少なくなります。注文が減少した場合、配達パートナーは収入が減る可能性が高いため、他の仕事を探し出すかもしれません。配達パートナーが少なすぎると料理の配達ができなくなったり、配達時間が長くなって食べ物を届けたときには冷めてしまったり顧客に不満を抱かせる可能性があります。
また、1つのレストランに一時的に注文が集中することも問題です。注文が集中した場合、レストラン側が注文された料理を作れなくなってしまい、結果として注文をした客の要望に応えられないためです。さらに、レストラン側が料理を作れたとしても配達パートナーが不足して料理を運べない、もしくは運ぶ時間が遅くなる事態も発生してしまいます。結果としてこのような事態はUber Eatsへの不満を感じさせることになります。

図: All parties in Uber Eats’ three-sided marketplace contribute to its overall health.
(Image credits: Restaurant-Partner: gst/Shutterstock.com, Delivery Partner: Kikuchi/Shutterstock.com, Eater: tigatelu/Depositphotos)
Uber Eatsには、上図の3つの関係者が存在するため、3者間で需要と供給を予測しバランスをとることが求められます。しかし、多くの場合に市場のバランスを取ろうとするとトレードオフを伴います。例えば、新しいレストランが出店された場合を考えます。注文する人のコンバージョンのみを最適化すると、過去のデータからその人が好きなレストランだけが上位にアップされます。そうすると新規出店したレストランはレコメンドされにくくなり、そのレストランはレコメンドの公平性に疑問を持つでしょう。このような背景から、Uber Eatsは注文する人のコンバージョンレートと、レストランパートナーの公平性を考慮した多目的最適化を行っています。この多目的最適化については後ほど詳しく説明します。

図:Uber Eatsのレコメンドの変遷
■多目的最適化のための3者への設定
注文をする人、レストランパートナー、配達パートナーのそれぞれに対して、どのようなことを考慮し、各種設定を行っているかを紹介します。
①注文をする人
注文をする人はUber Eatsの関係者の中でも「需要」に関係するため、非常に重要です。
Uber Eatsのアプリを開くと、レストランがいくつか表示されます。その時にはアプリの裏で様々な要因を考慮したランク付けが行われ、個々人に適したレストランがレコメンドされます。利用可能なレストランを最適にランク付けする方法を詳しく見てみると、以下の考慮すべき要因があります。
・レストランはどのくらい人気があって、その決め手は何か?
・レストランの特徴は何か? (オーダーが早いなど)
・現在のレストランの状況は?ランチタイム/ディナー?
・自分と似た人はどんなものを注文したか?
など
しかし、これまでのデータを利用して上記の要因を考慮した場合、どのような結果になるでしょうか。例えば、過去にUber Eatsを何回か利用して、ラーメンしか注文していなかった場合、過去のデータに基づくと次に注文しようとした場合にはラーメン店しかレコメンドされず、もっと軽いものが食べたいと思っていた時には残念な気持ちになってしまいます。
そのため、Uber Eatsではレストランのランク付けの指標として「多様性」を加えて考えるようになりました。具体的にはレコメンドの指標として、
(1).関連性があること:注文する人に関連するレストラン、つまり注文する人に適したレストランを簡単に見つけられること
(2).多様性があること:注文をする人が様々な種類の料理を探索できるようにすること
の両方を取り入れました。この指標に則って、
(a)注文する人が求めるもの(テイスト)のプロファイルと、
(b)レストランの料理のプロファイル
をそれぞれ(a)注文する人と(b)レストランのベクトル表現として扱い、
(1)関連性と(2)多様性の多目的を最適化するアルゴリズムを開発しました。
このレコメンドが威力を発揮するのは注文者の2回目以降の注文です。なぜなら最初の注文は初回割引などがきっかけとなることが多いため、2回目以降もUber Eatsを使ってもらうための仕掛けが必要だからです。そこで、Uberは注文者が再びUber Eatsから注文する確率を予測するモデルを考えました。
このモデルでは
・料理の配達時間のズレ(予実誤差)
・レストラン側の料理の準備時間
・注文に対する料理の評価 など、
注文する人とレストランの過去のデータを使用します。この予測の結果は、後述の「多目的最適化の実行」の部分で使用します。
②レストランパートナー
レストランパートナーになってもらう以上、Uber Eatsとしてはレコメンドに一定の公平性が必要です。例えば新しいレストランがUber Eatsのプラットフォーム上に追加された場合に、関連性(過去データに基づく個別最適化)のみが考慮されていると、新しいレストランはレコメンドをする際のランクで上位にあがって来ません。そのため、新しいレストランにランキングを上げてアプリ画面上に表示する公平な機会を与えるために、Uberはこのレコメンドの最適化を多腕バンディット問題として扱いました。以下では「多腕バンディット問題とは何か」から始めて、「どのようにしてレストランに公平な機会を与えていくか」を考えていきます。
・多腕バンディット問題に取り組む
多腕バンディット問題とは、「探索」と「活用」という二種類の行動を使い分けて報酬を最大化する問題です。よくある例がスロットマシンです。複数のスロットマシンがあった時に、得られる報酬の最大化を目的にします。しかし、使えるお金には制限があります。そのため、スロットマシンのアーム(腕)を引く戦略が重要になります。
ここで、最初にどのスロットマシンが当たりやすいかを知るため、情報収集としてアームを選択するのが「探索」です。そして、収集した情報を利用してアームを選択するのが「活用」です。
UberEatsのケースでは、レストランがスロットマシンのアームに該当します。
ここで、「探索」と「活用」をする方策(policy)はいくつかありますが、UberEatsではUCB(Upper Confidence Bound)方策を使用しています。
今回の場合、UCB方策では
・過去のインプレッション数
・合計クリック数
などの指標に基づいて、各レストランのUCBスコアを計算します。このUCBスコアを使用してレストラン間の順位を決定します。UCBスコアのざっくりとした特徴は、そのアーム(レストラン)の選択回数が少ないほどUCBスコアが高くなることです。したがって、新しいレストランは、最初は比較的高いUCBスコアを持っているため、レストラン間の順位が高くなり、アプリの画面上に表示されやすくなります。新しいレストランがより多くのインプレッションを集めると、UCBスコアは滑らかに減少し、ランク付けの重みを関連性などの他のスコアに徐々に移します。
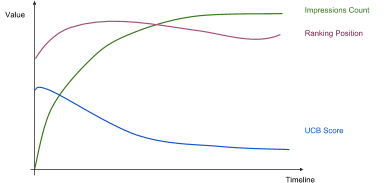
このようにして、UberEatsは新たにプラットフォーム上に登録されたレストランにもなるべく公平性を保てる工夫をしているのです。
③配達パートナー
配達パートナーなしでは、UberEatsのビジネスは成り立ちません。 Uber社内のチームは、ランク付けとレコメンドが配達パートナーをどのように満足させられるかを調査し、配達パートナーが最も稼働できるようにレコメンドを最適化しました。
・配達パートナーの位置予測を用いたレコメンド
Uber Eats側は、稼働できる配達パートナーの予測される位置や配達パートナーの密集具合のデータをとり、近くに配達パートナーが多いレストランをランクアップすることによって、Uber Eatsの利用率の向上に役立てようと考えました。
ここで、レストラン側は注文を受けてから料理を準備するのに時間がかかるため、配達パートナーの現在位置を単純に使用することはできません。したがって、料理が準備される予定時刻の予測位置を把握し、その位置情報を使用する必要があります。この配達パートナーの到着時間の予測も、Uberの機械学習プラットフォームである”Michelangelo”を使用して予測を行っています。
(機械学習を使用してUber Eatsから到着時間を見積もる方法の使用例については、Uberの機械学習プラットフォーム"Michelangelo"に関する以下の記事をご覧ください。)
■多目的最適化の実行
3 side プラットフォームの全ての目的を最大化したいのですが、実際には妥協することがよくあります。
例えば、今回のような3-sideプラットフォームでは、下図のように市場の公平性(横軸)と注文率(縦軸)とのトレードオフ曲線を示しています。
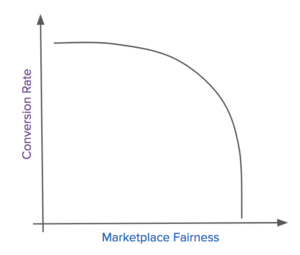
もしUber Eatsが注文者だけのために最適化するならば、恐らくほぼ全ての注文者に対して非常に人気のあるレストランをレコメンドするでしょう。この場合、新規のレストランは、注文者のアプリ画面には現れないため注文が少なくなり、市場の公平性を損なうことになります。一方で、市場の公平性のみを最適化し、すべてのレストランがすべての注文者に平等に表示されるようにすれば、注文者にマッチしない飲食店をいくつか推奨してしまうため、コンバージョンレートに悪影響を与えてしまう可能性もあります。
多目的最適化では以上のようなトレードオフが存在するため、制約条件を設定した上で、全ての目的関数を最大化するパラメータを調整します。(具体的にはラグランジュ双対性およびKKT条件を使用します。詳細は以下をご参照)
ここまで紹介したところで、実際の計算フローを整理します。以下の図は、多目的最適化を使用した、ランク付けフレームワーク全体のフローチャートを示しています。
最初の層では、各種インプットデータを用いて需要予測をします。
2層目は複数の目的を追加し、トレードオフを考慮した最適化をします。
最後の3層目では、3 side プラットフォーム向けに最適化されたレコメンドを行います。
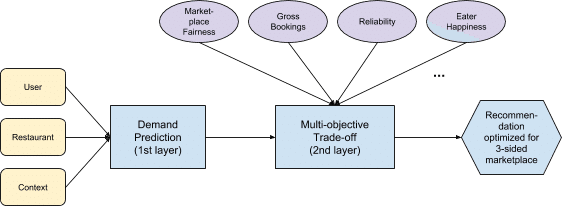
このような3 side プラットフォームで多目的最適化を実現する仕組みは世界トップレベルだと思います。個人的には、他の3 side プラットフォームでこのような多目的最適化を実現しているサービスはUber以外に知りません。(もしあれば教えて頂きたいです。)
今後は他社・他業界のサービスもUberのようにプラットフォーム上の関係者が多くなり、多目的最適化が求められるようになるでしょう。その際に、Uberは間違いなくベンチマークの1つとなると考えられます。
■Foursquareと連携したレコメンドによる相乗効果
最後に、データサイエンスの要素は少なくなりますが、UberがFoursquareと連携して相乗効果を出した事例を簡単に紹介します。

■Foursquareとは何か
Foursquareとは位置情報に基づくSNSサービスです。従来のFoursquareでは、ユーザーはアプリを使ってお店など様々な場所に訪れてチェックインすることで、その回数などに応じてバッジがもらえていました。現在ではチェックインの機能をSwarmに分離し、そしてFoursquareはYelp(≒食べログ)に近いサービスなりました。今ではレストランなどをレコメンドするためのサービスとなっています。このレコメンドでは、自分が今までに行った場所、色々な人の評価や友人のレコメンドなどに基づいて、簡単にランチ・ディナースポットなどを発見できるようにしています。
さらに、Uberとの統合によりFoursquareアプリ内からの配車も可能になりました。これにより、移動の際に住所を入力したり、道順を調べたりする必要はありません。
■なぜUberはFoursquareと連携するのか
実は、Foursquareは膨大なデータを持っています。5000万人以上のユーザーから位置情報を収集しており、ユーザーは世界中で約100億回、8500万以上の場所にチェックインし、そしてFoursquareには8700万以上のヒント(“タグ”のようなもの (ex.#ステーキ))を残しています。これらのデータを活用してユーザーが行きたいと思える場所を提示してくれるのです。
実際にこれらのビッグデータを活用し、Uberと連携した以下の成果も出ています。
・Foursquareアプリ内でUberボタンを使用したユーザーは、その後、平均的なFoursquareユーザーの2〜3倍アクティブになりました。
・FoursquareアプリでUberボタンを使用したユーザーの74%が翌週にもこのUberボタンを使用しています。
・Uberボタンをタップしたユーザーも、3~4倍のvenue views(特定の場所のチェック)をしています。

UberとFoursquareの相性は非常に良いです。なぜなら、Foursquareは「目的地」を提示し、Uberはそこに行くための「手段」を提示します。したがって両者は補完関係にあります。しかもお互いがカニバリゼーションを起こす領域もないため、組み合わせとして最適なのです。
■さいごに
前回と今回でUberのサービスを支えるデータサイエンスを紹介してきました。Uberは「シェアリングエコノミー」や「プラットフォーマー」としてメディアに取り上げられますが、重要な役割をしているのは、Uberのサービスの裏にあるデータサイエンスだと思いました。
さらに、Uberはデータサイエンスによって不確実性を把握しているため、個人的な推測ではありますが、その不確実性に対応する仕組みを構築していると考えます。例えば、UberXのドライバーが供給過多になった場合は、Uber Eatsの方に人員を回してドライバーが稼働できない状態を防止することもできます。実際に、Uberのドライバーに関しては手が空いて稼働率が下がってしまうことを恐れるドライバーもいるため(前回のnoteご参照)、ドライバーの不満を解消する仕組みが構築されていると思います。
また、Uberはダイナミックプライシングが可能であるため、各サービスの需要と供給を、①価格と②サービス間をまたいだ配達パートナー/ドライバーの供給量によって調整できると考えられます。
今回紹介したデータサイエンスはUberの強みの1つであり、今後も進化を続けていくと思います。
参考文献
↑Uberのモビリティのレコメンドも取り組もうとしているようです。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?