
データ分析を上手にビジネスに活かす方法

本稿では、マーケティングを例としてデータ分析の全体像を概観します。
マーケティングにデータを活用すれば、主に以下のようなことができます。
(1)維持できる顧客数が増える
(2)顧客の購買金額が増える
(3)マーケティングの費用対効果が上がる
それでは、以下で具体的に見ていきましょう。
(本編には、有益な情報を適宜追加していきます。)
1.マーケティングを例としてデータ分析の全体像を眺めてみる~マーケティングにデータを活用すると、何ができるか~
江戸時代の呉服屋の番頭は、顧客の顔と名前だけでなく、その人の好みや購買の履歴を頭に入れておくことで、効果的に商売をしていました。古くは、これもデータ活用の一種といえるでしょう。なぜならば、画一的にすべての顧客に対して同じものを勧め、同じ売り方をした場合と、顧客の好みに応じて勧める商品を変えたり、以前買った時期を知ったうえで買い替えを勧めた場合とでは、後者の方がはるかに稼げる商売になるからです。
それでは、現代においてのデータ活用とは何でしょうか?実は、本質的にはこの呉服屋の例と何ら変わりません。ただ、取得できるデータの種類や量が増えたために、より精度が高く顧客の好みを把握したり、顧客の買うタイミングを推定したりできるようになっています。
顧客の好みやニーズは多様化し、商品サイクルも短くなっていることから、よりタイムリーに顧客のニーズに対応する必要があります。一方で、企業の側も多くの市場において成長が停滞し、競争も益々激しくなっています。そんな中、データ活用によって顧客に効果的なアプローチをするデータサイエンスが脚光を浴びるようになってきているのです。また、大量のデータを扱うことが可能となったテクノロジーの進歩も大きく関わっています。
多くの分野において、新規顧客を獲得するためのコストは増大してきていますし、既存の顧客を維持することの重要性もますます高まっています。ある業界では、新規顧客を獲得するために必要なコストは、既存の顧客を維持するためにかかるコストの約10倍にもなることが分かっています。
しっかりとデータを活用すれば、タイムリーに顧客の好みとニーズをつかまえ、ちょうど良いタイミングで顧客が必要とする商品を提案し、自社から買ってもらえるようになります。これこそデータサイエンスの真骨頂だといえます。
マーケティングにデータを活用すれば、主に以下のようなことができます。ここではイメージをつかんでもらうために、簡単な例だけを紹介します。
(1)維持できる既存顧客の数が増える
たとえば、ある保険会社の例では、顧客の離脱率を5%下げることができれば、利益が25%向上します。このように、顧客が自社から離れていかないように、適切な方法とタイミングで顧客にアプローチすることは大変重要なことです。
(2)顧客の購買金額が増える
顧客の好みとニーズを把握することで、顧客の求める商品と併せて、別の商品もセットで買ってもらうことや、よりグレードの高い(高付加価値な)商品を買ってもらうことで、顧客あたりの購買単価をあげることもできます。
(3)マーケティングの費用対効果が上がる
一昔前と違い、いくらCMを流しても思ったほどには売り上げにつながらないということも多々あります。ターゲットとする顧客をデータからより深く知ることで、必要なマーケティング活動をピンポイントで行うことができれば、これらの活動の費用対効果を大幅に高めることもできるようになります。
2.どんなデータが使えるのか
まず、自社の中にどのようなデータが保存されているのか(または眠っているのか)を知る必要があります。データが一切存在しないという会社はおそらく存在しないことでしょう。もし何らかのデータが存在するのであれば、それをマーケティングに活用できないかを考えてみます。(まずはマーケティング活動に絞って説明しますが、それ以外にも活用の可能性は数多くあります。)ここでは、これを「既存データ」と呼ぶことにします。
次に、これらの既存データだけではまかなえない部分について、外部のデータの活用を考えます。これには無料で利用可能なものから、有料で購入するものまでさまざまあります。また、新たに自社で取得するようにし、新たにデータを蓄積していくこともあります。ここでは、これを「新規データ」と呼ぶことにします。
まず、ここでは大まかに、データには、「既存データ」と「新規データ」があるということを覚えておきましょう。
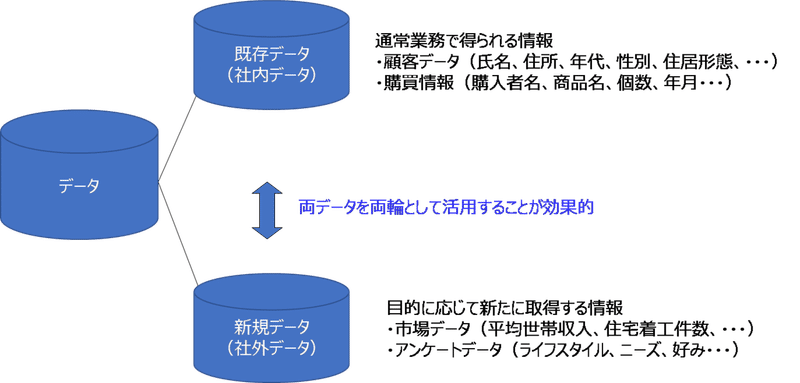
図2 既存データと新規データ
3.マーケティングリサーチを使いこなす
読者もマーケティングリサーチということばを聞いたことがあるかもしれません。これもデータサイエンスの適用領域の一つです。
マーケティングリサーチというのは、データによって市場の機会や問題を特定して明らかにすることです。これによって、マーケティングのプロセスを改善していくことができるため、マーケティング活動を洗練していくことができます。
それでは、なぜ調査をするのでしょうか。実は、マーケティングリサーチにおいて、もっとも大切なことは、「なぜ調査するのか」をしっかりと決めることだともいえます。調査をすれば、何らかの結果は必ず得られます。何らかの情報も必ず得られます。しかし、だからといって闇雲に調査をしても真に有益な情報は得られないということも肝に銘じておかなければなりません。何よりもまず調査目的を明らかにし、何を得たいために調査をするのかを、箇条書きにすることをお勧めします。
なお、調査には、大きく以下の2つの型があります。
ひとつは、「事実発見型」。これは、調査者がノーアイデアなものについて、回答者にたずねる調査方法です。しかし、調査者もよくわかっていないことを聞くのですから、調査として失敗するケースも散見されるので注意が必要です。
もうひとつが、「仮説検証型」。あらかじめ設定した仮説が正しいかどうかを確認するための調査方法です。具体的には、2つ以上の変数間の関係を予想して、言語化することを目的に行います。たとえば、以下のような仮説です。「23区在住の20歳代と30歳代の女性は有職率が高く、平日の在宅率が低いため、防犯に対する意識とニーズが高い」などです。
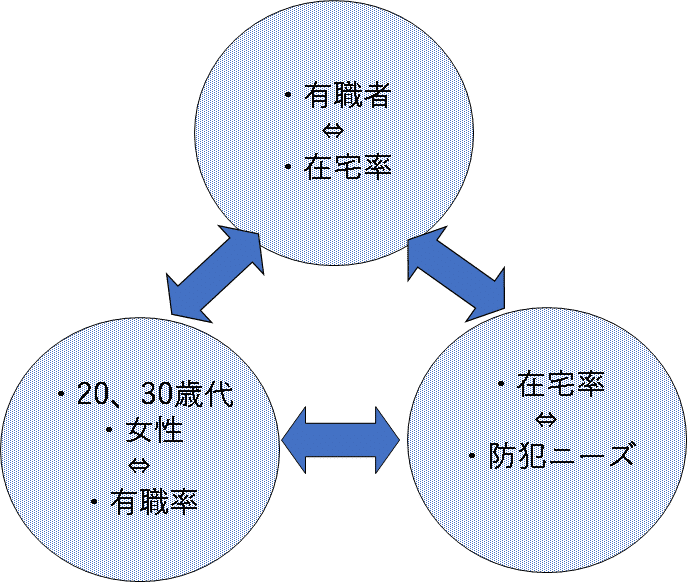
図3 調査による仮説検証の例
4.データの4つのものさしを知る
データには、4つのものさしがあります。測定する対象の持つ特徴に応じて、測る尺度が異なるからです。その4つとは、具体的には、「名義尺度」「順序尺度」「間隔尺度」「比率尺度」です。最初から2つを質的データといい、残りの2つを量的データといいます。また、データとしての情報量は、名義尺度から比率尺度に向かうに従って多くなっていきます。以下、それぞれについて説明します。
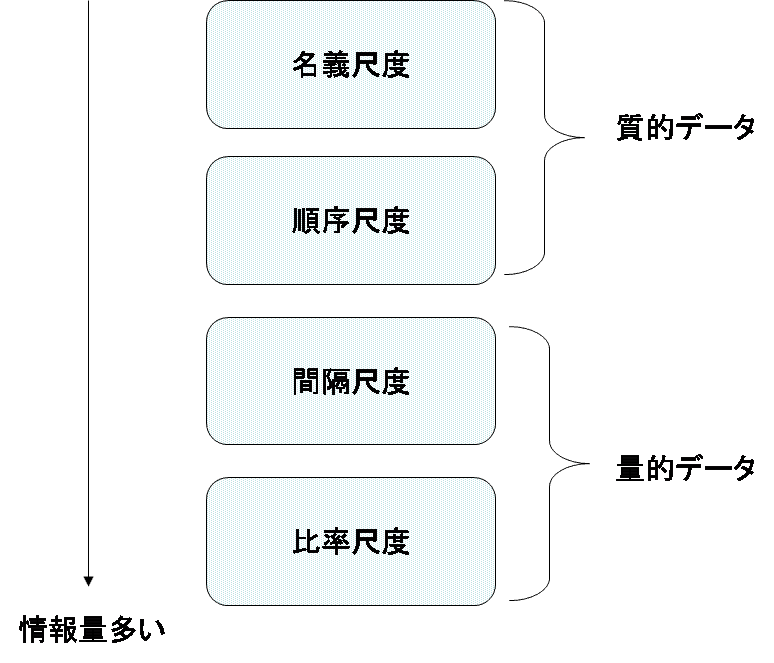
図4 データの4つのものさし
(1)名義尺度
単なる記号として(記号の代わりとして)、数字を用いたものをいいます。同一のものや同種のものに同じ数字を割り当てた尺度です。たとえば、以下のようなものが代表例です。
例1:男性=1、女性=2、未回答=3
例1:戸建=1、分譲マンション=2、賃貸マンション=3、・・・
これらの名義尺度においては、それぞれの数字には記号の代わりとしての意味しかないため、順位をつけたり、四則演算(足し算・引き算・掛け算・割り算)を行うことはできません。すなわち、戸建が1(番)で分譲マンションが2(番)だからといって、戸建ての方が分譲マンションよりも順位が上だという意味にはならないということです。同じように、男性(1)+女性(2)=結婚(3)のような演算をすることもできません!
可能な統計処理として代表的なものには、最頻値やχ2検定などがあります。
(2)順序尺度
ものごとの大小関係を表すために数字を用いたものをいいます。代表的なものには、成績順位(マラソンの順位や試験の合計点数の順位)や成績の5段階評価、および売り上げランキングなどがあります。とても極端なケースを例にあげれば、試験の受験者が3名しかいなかった場合に、100点=1位、20点=2位、0点=3位だったとします。この1位~3位という数字は、これらの受験者の実力をうまく反映できていないことが分かります。
なぜならば、今20点=2位ですが、仮に99点=2位だったとしても、順位は何も変わらないからです。1位との点数差が何点であったとしても、同様に1位~3位の順位がつきます。このことからも分かる通り、先の(1)名義尺度よりも順序という情報量は増えていますが、(1)名義尺度と同じように、こちらも四則演算はできません。
可能な統計処理として代表的なものには、中央値、四分位偏差などがあります。
(3)間隔尺度
順位尺度に間隔の概念を加えたもので、大小・順序関係だけではなく、その差や和にも意味があるものをいいます。ただし、0は相対的な意味しか持ちません。代表的なものには、西暦や温度、偏差値などがあります。気温0℃には相対的な意味しかありません(気温の表し方には、摂氏と華氏があるのはよく知られていますね)。
そのため、どこが基準(0℃)かということに意味はありませんが、気温が摂氏25℃から30℃に上昇したという場合には、その気温差5℃には意味があります。
西暦や偏差値でも同じです。西暦2000年から2010年になったという場合には、その差の10年には意味がありますが、西暦2000年という数字そのものには意味がありません。偏差値も45から50に上がったという場合には、偏差値が5上がったということには意味があります。
可能な統計処理として代表的なものには、平均、標準偏差、t検定などがあります。
(4)比率尺度
間隔尺度に原点ゼロを加えたものをいいます。比率尺度は量的変数の尺度であり、尺度の中では最上位の尺度となります。間隔尺度までの全特徴に加えて、0が絶対的な意味を持ちます。例えば、身長や大きさ、値段などです。
具体的には、「100円の商品と200円の商品では、200円の方が2倍の値段である」ということがいえます。すなわち、金額の比率も意味を持ちます。
そのため、測定値間の倍数関係(比)を扱うことが可能になり、同一性、順序性、加法性、等比性を表します。利用可能な統計量は、値が絶対的な意味を持つので、変動係数や幾何平均などを扱うことができます。
可能な統計処理としては、あらゆる統計処理が可能です。
以上の4つの尺度(ものさし)を図5にまとめました。
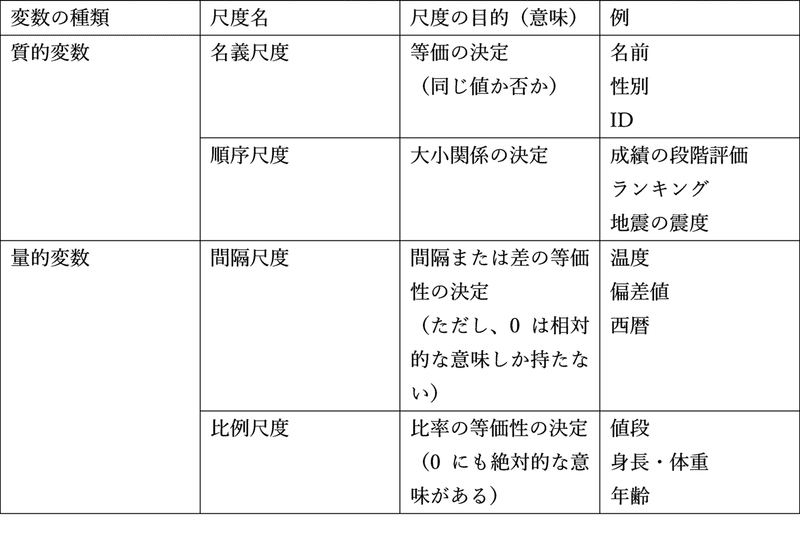
図5 各尺度の目的と代表例
5.測定にはかならず誤差がつきまとう
人の心の状態や行動の特性また社会現象の特徴などを測定すると、そこには誤差が必ず含まれます。
誤差を小さくするための方法もありますので、ここではその方法を紹介します。
(1) 再検査法
時間的間隔をおいて同一測定を行うことで誤差を抑える方法です。
心理テストや知能テストの信頼性を高めるために、時間的な間隔を空けて、同じテストを同じ対象者に2回行うことがあります。1回のテストよりも2回のテストの得点間の相関関係を求めることで、測定誤差を抑えることができます。これは再テスト法とも呼ばれます。
(2)評定者間の一致度
同一対象を二人以上で測定することでも誤差を抑えることができます。
行動分析学などにおいては、実験結果を複数の研究者で主観的に判断して、それらの判断がどれほど一致しているかによってデータが信頼できるかどうかを決定することもあります。この2人以上の観察者による記録間の一致度のことを「評価者間の一致度」といいます。
(3)折半法
測定値が複数の項目の合計得点として与えられる場合に、項目を二分し、それぞれに合計値を算出し、両者の相関係数を求める方法です。すなわち、同時実施の平行テストを疑似的に構成することで、誤差を抑えようとするものです。
折半法では、1回のテストを実施すれば信頼性に関する情報を得られる点が再テスト法と異なる点です。
ただし、大切なことは、項目を折半する方法が一意ではないということです。 例えば、奇数番目の項目と偶数番目の項目で折半して部分テストを作ることを奇偶法といいますが、これに限らずテストの前半部分と後半部分で分割しても構いません。 この場合には、どのような基準で折半したかによって結果が変わります。
(4) 因子得点を用いる方法
複数の項目に共通する成分(共通因子)を利用して、誤差を抑えようとする方法です。
いずれにしても、測定値には誤差が含まれるため、下式となることを覚えておきましょう。
「測定値=真値+測定誤差」
測定値=真値とはならず、これには必ず誤差が加わるということです。
6.データ処理の手順
データ処理の一般的な流れは、以下になります。
(1)仮説の設定、(2)データの収集、(3)データの処理、(4)仮説の検討です。
(1)では、何をどのように検討したいのかを明らかにする必要があります。(2)では、データ収集方法を決定して、データを収集します。(3)では、データ処理の目的を明らかにして、適切な処理(統計処理・分析)を行います。(4)では、データ処理した結果を吟味します。
(1)データを大まかに把握する
データを大まかに把握するために有効な手段として、以下があります。
・表にまとめる
・図にまとめる(ヒストグラム、円グラフ、レーダーチャート、箱ヒゲ図、etc)
・図の種類を変える

図6 各図から分かるデータの特徴
(2)いろいろな分析手法のダイジェスト
まず手始めに、代表的な統計数値を確認することから始めてみましょう。分析対象としているデータの特徴を大まかにつかみます。データの中心的傾向を示す値を「代表値」といいます。代表値としては、一般に平均値が使われますが、分布の形によっては最頻値や中央値を代表値にする場合もあります。
最近の統計ソフトでは、これらを基本統計量として一覧で表示してくれるものもあります。
①平均値(最も一般的)
平均値は、個々の変数の値の総和をデータ数で割ったものです。試験の平均点、身長や体重の平均など、日ごろよく耳にするもので、生活にも馴染みの深いものでしょう。
平均を一般化すると、変数xについて、平均値 は、以下のように表せます。
x ̅=(x_1+x_2+x_3+・・・+x_n)/n (ただし、nはデータ数)
②最頻値(モード)
度数分布表において、もっとも頻度(度数)の高い値のことを最頻値といいます。
③中央値(メジアン)
データを大きさ順に並べたとき、ちょうど中央に位置する値を中央値(メジアン)といいます。
たとえば、ここで、{-5,5}の平均も{-5000,5000}の平均も同じ0となります。
同じように、{5,5,5}の最頻値も{1,5,5,3,5,1}の最頻値も同じ5になります。
しかし、平均値や最頻値が同じであっても、これら両者のデータには大きな違いがあります。データの散らばり具合が異なるからです。このデータの散らばり具合を見るための方法として、標準偏差や分散があります。
④分散(s2)
分散とは、統計学において、数値データのばらつき具合を表すための指標です。ある一つの群の数値データにおいて、平均値と個々のデータの差の2乗の平均を求めることによって計算します。データ相互のばらつきを見るために恣意的にこのような指標を作ったと考えれば分かりやすいかもしれません。
もし単純にデータの差をとってしまうえば、正と負の両方の値をとってしまうことになるため、これらを足し合わせると正と負の値が相殺してしまうので、平均値からどれだけ離れているかを表す指標としては役割を果たせなくなってしまいます。
そこで、考え出されたのが2乗してから平均をとるという方法です。このようにすれば、
平均値から離れた値をとるデータが多ければ多いほど、分散(指標)が大きくなることを表現できます。2乗することで、平均値からの距離の基準を正負によらない値として統一することができるからです。
これを数式で書くと以下になりますが、ばらつきの大小を見るという目的のために作った指標が分散だというふうに考えれば、何も怖いことはありません。
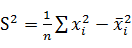
ここで、nが観測値の数、x1,x2…xnが一つ一つの観測値。xの添字は観測したデータの番号を表しています。
それでも問題がひとつあります。たとえば、仮にある物の重さの平均からのばらつきを見ようとした場合、分散の大きさ(の単位)はg2(グラムの2乗)で与えられることになります。しかし、グラムの2乗とは一体何か?と思ってしまいますね。
そこで登場するのが、標準偏差です。
⑤標準偏差(s)
標準偏差は、分散の平方根で与えられます。すなわち、標準偏差Sは、次式となります。
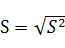
もうお分かりですね。たとえば、グラムの2乗だったものを、私たちに馴染のあるグラムに単位を直したものが標準偏差です。距離の2乗や時間の2乗などもすべて同じです。2乗だと分かりにくいものを、もとの単位に戻しているのです。
(3)統計的検定
標本(データ)における相違や関連性が、調べようとするもの全体(母集団)においても認められるかどうかを検討することを統計的検定といいます。つまり、データに見られる相違や関連性が、偶然か否かを見極めることをいいます。
①検定の方法
ここでは、大まかに検定の流れを把握しておきましょう。
(1) 仮説の設定
母集団のある特性について、予測H1を得たとします。このとき、この予測のことを対立仮説といいます。これが、検定によって正しいと主張したい仮説になります。
次に、仮説H1を否定するための仮説H0を立てます。この否定する仮説のことを帰無仮説といいます。
(2) 分布の把握と棄却域の設定
対象となる統計量がどのような分布に従うのかを調べます。次に、その統計量が分布上のどの範囲に入ったときに帰無仮説H0を棄てるのかをあらかじめ決めることになります。これを棄却域といいます。棄却域の起こる確率をαとして、この棄却域に入ることを許容する確率を決めておきます。よく使われるのが、5%や1%です。棄却域に入ることを5%まで許容した場合には、「有意水準5%」などといいます。
(3)仮説の採否を決定
ここで、もし統計量が棄却域に入れば、有意水準αで帰無仮説を棄却(対立仮説を採択)します。もし統計量が棄却域に入らなければ、帰無仮説は棄却しません。この場合には、帰無仮説の方を採択しておくことになります。ただし、帰無仮説を採択するという場合には、帰無仮説を積極的に正しいと主張できるわけではないことに注意が必要です。これは、設定した棄却域の中においては、棄却するまではいかないという意味になります。
主な検定方法には、以下のものがあります。
・χ二乗検定(カテゴリーの差)
・t検定(平均の差)
・F検定(分散の差)
統計的検定においては、よく有意水準5%が使われます。ここで頭に入れておきたいことは、「有意水準5%で有意な差がある」と認められた場合、100回に5回は誤りである可能性を含んでいるということです。それでは、この5%を小さくすればいいかというと、必ずしもそうとはいえません。もし1%にすれば、100回に1回しか誤りである可能性を含まないことになりますが、その分、「有意な差がない」との結論が導かれる可能性も高くなるからです。
(4)多変量解析
多変量解析とは、多くの要素(3つ以上)を含んだ対象をまとめて分析する方法です。多変量解析としてよく使用されるものには、以下のものがあります。
①重回帰分析
重回帰分析とは、ある特定の変数を、他の複数の変数を用いて一次式で予測する方法です。
ここで、目的変数をY、説明変数をXnとすると、
Y=aX1+bX2+・・・+c
ただし、目的変数、説明変数ともに量的データ。
ここでの注意点としては、説明変量間に相関関係の高いものは使用しないということです。説明変量間に相関関係の高いものを使用すると、解析結果が不安定な状態となる現象が見られることがあります。これを「多重共線性」といいます。
解析結果から異常な値が存在しないかどうかをか確認し、もし存在するようであれば、説明変数間の相関係数を確認する必要があります。異常値が存在し、かつ強い相関が認められる説明変数が存在するようであれば、どちらか一方の説明変数を除外して再分析を行わなうなどの対処が必要になります。
ただし、多重共線性のある状態では、係数についての信頼性の高い解釈を行うことはできませんが、適合度や予測の精度には影響がありません。
【一口メモ】多重共線性とは
重回帰分析やロジスティック回帰分析などの多変量解析を行ったときに、互いに関連性の高い説明変数(独立変数)が存在すると解析上の計算が不安定となり、回帰式の精度が極端に悪くなったり、回帰係数やオッズ比などが異常な値をとったりする現象のことをいいます。これをマルチコ現象と呼ぶこともあります。
多重共線性が起こりやすい条件として、①説明変数(独立変数)間の相関係数が±1に近い組み合わせが含まれる、②説明変数(独立変数)の個数がサンプルサイズに比べて大きいなどがあげられます。いずれの条件に該当しても多重共線性が起こらない場合もあり得ますが、分析をする際に、これらの点に注意する必要があります。
②判別分析
判別分析とは、特定の1変数を、他の複数の変数を用いて一次式で予測するものです。
ただし、目的変数=質的データ、説明変数=量的データです。説明変量間に相関関係の高いものは使用しないようにします。
下図は、判別式を使用した体力・知力テストの合否判定です。体力テストと知力テストの点数が、判別式よりも上にいる人は「合格」、下にいる人は「不合格」です。なお、この例では、判別式によって「補欠」も判定しています。
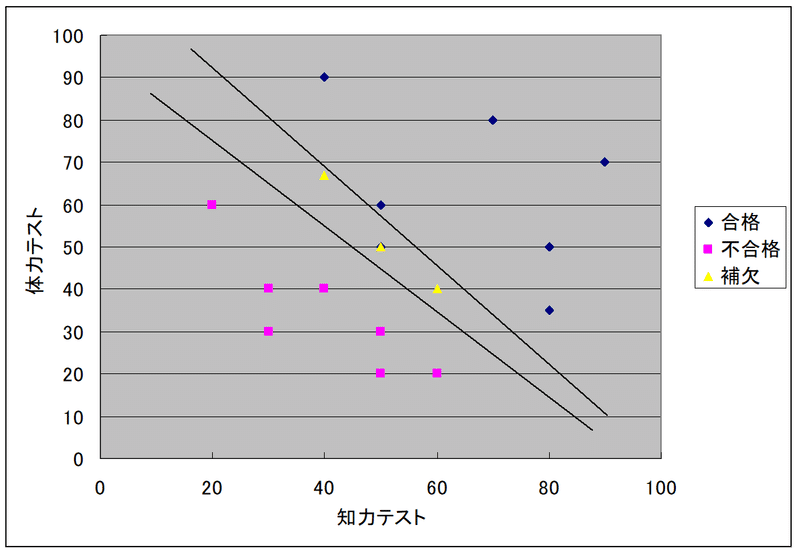
③因子分析
因子分析とは、複数の変数間の関係性を探り、変数間に潜むいくつかの因子を見つけ出す手法です。複雑なものを単純な要因で説明することができます。変数が測定されたものであるのに対し、因子は測定された変数間の相関関係をもとに導き出される潜在変数です。
たとえば、国語や社会のテスト点数から「文系能力」、数学と理科のテスト点数から「理系能力」を導き出すようなものをイメージすると分かりやすいかもしれません。
④クラスター分析
クラスター分析とは、性質の似たケースをいくつかのグループにまとめる手法です。一般に、セグメンテーションと呼ばれているものの一つです。
7.顧客ニーズとマーケティング
(1)ニーズとはなにか
ここで、そもそも「ニーズ」とは何でしょうか。どのようにしたら「ニーズ」が分かるのでしょうか。一般には、データ分析や調査をすれば分かる、消費者に求めているものを聞けば分かると思われています。しかし、ニーズがあると分かってからでは出遅れてしまう可能性だってあります。ニーズが明らかであるならば、他社も同じような商品・サービスを出す可能性もあります。ここでは、ニーズには、「顕在ニーズ」と「潜在ニーズ」があることを押さえておきましょう。
(2)潜在ニーズと顕在ニーズ
ニーズにも、すでに消費者が認識できている顕在ニーズと、まだ顕在化していない潜在ニーズがあります。潜在ニーズを顕在化させることがマーケティングであるともいえます。
ただし、ここで注意しなければいけないことは、以下です。
・仮にニーズがあったとしても、潜在ニーズのままでは売れない
・不満願望と商品ニーズは別物である
・日常生活で感じる不満や願望が強いからといって、それを解消してくれる商品のニーズが高いとまではいえない
・不満と商品を結び付けなければ、商品ニーズにはならない
(3)不満願望と商品ニーズの心層深度
不満願望と商品ニーズの心層深度はまったくの別物と考えなければなりません。たとえ不満が顕在化していたとしても、商品ニーズが顕在化しているとは限りません。
これを示したのが図7です。不満願望と商品ニーズには、顕在化率に大きな隔たりがあることが普通です。
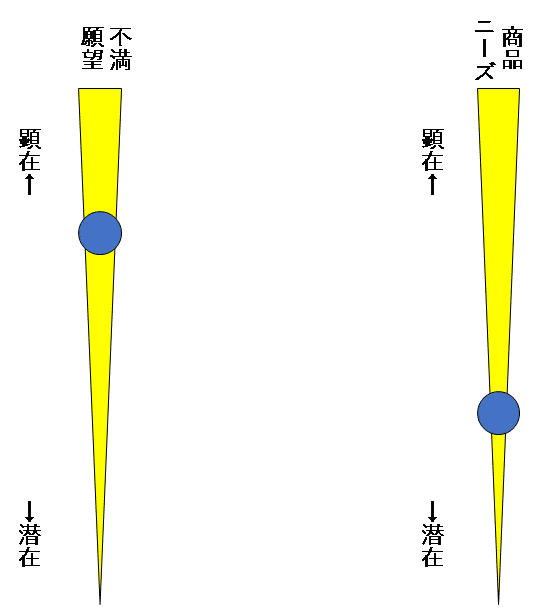
図7 不満願望と商品ニーズの心層深度
たとえば、やや古い話になりますが、今では一般的にも普及している床暖房の不満願望と商品ニーズについて見てみます。エアコンに対するさまざまな不満願望は以前から顕在化していましたが、だからといって、いきなり「床暖房」という商品ニーズが生まれたわけではありません。不満願望と商品ニーズを結びつけることで、商品ニーズを高めることができます。
仮に、エアコンに対する不満が「足元が寒い」だとすると、床暖房にすることで「足元が暖かい」という商品ニーズと結びつくようにする必要があります。この結びつきを起こさせるためには、「床暖房の体験コーナー」を設営するなどの施策が有効となります。(図8)
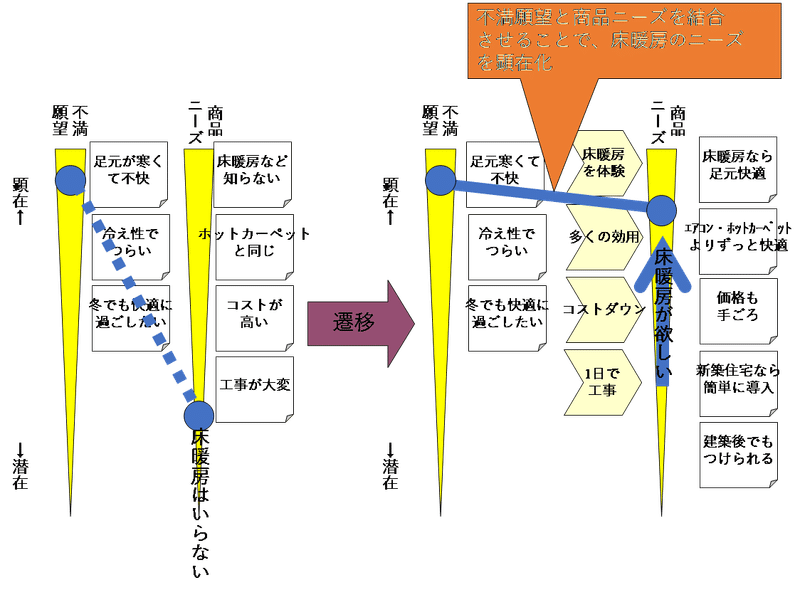
図8 不満願望と商品ニーズの結合(例:床暖房)
【補講①】CRISP-DMを押さえる
CRISP-DM(CRoss-Industry Standard Process for Data Mining)は、SPSS、NCR、ダイムラークライスラー、OHRAがメンバーとなっているコンソーシアムにて開発されたデータマイニングのための方法論を規定したものです。
これは、データマイニングプロジェクトを具体的にどのような手順で進めていくのか、各工程において実施する作業はどのようなものがあるのかを明確に定義しています。一見すると単純そうですが、実体験に基づいたきめ細かなプロジェクト工程が理解でき、その適用の汎用性および柔軟性から多くのデータ分析プロジェクトに採用されています。
・フェーズ1:ビジネス状況の把握
・フェーズ2:データの理解
・フェーズ3:データの準備
・フェーズ4:モデル作成
・フェーズ5:評価
・フェーズ6:展開/共有
データマイニングの標準化手順「CRISP-DM」では、これら6つフェーズを繰り返し行います。
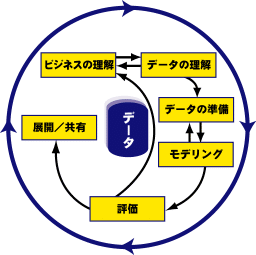
図1 CRISP-DM
マーケティング担当者がCRM実現のために行うデータマイニングは、顧客、商品、売り上げ、店舗、Webログなどのデータから顧客ニーズの傾向をつかむことから始まります。そこから顧客と商品に対しての企業戦略を導き出し、売り上げ予測などを行うことも可能となります。システムはデータ・ウェアハウスを構築していなくても、データマイニングを始めることができます。
次項では、データ分析の実際の作業を6つのフェーズに分け、それぞれのフェーズで行うべき内容と留意点などを簡単にまとめていきます。ぜひ実務をイメージしながら読み進めてみてください。
イメージしにくいものとしては、自社内にどのような「データ」が存在し、それらがどこにどのような形式で格納されているのか、それらをどのようにデータ分析のインプットとするのかというような基礎的なことであるかもしれません。普段、集計処理などで用いているExcelのデータやDBMS(データベースマネジメントシステム)、あるいは紙のアンケートには記述されているが未だ電子化されていないデータ(情報)などもあるかもしれません。これらが分析に適したデータであるか否かを見極める必要もありますが、すべてのデータがデータ分析の対象になり得るとの前提に立って、検討を深めていく必要があります。
【一口メモ】CRISP-DMとは
CRoss Industry Standard Process for Data Miningの頭文字をとったものです。SPSS、NCR、 Daimler Chrysler、 OHRAなど、世界200社以上での導入実績がある標準化されたデータマイニングの方法論のことです。
【補講②】データマイニングの実践的な手順
各フェーズにおいては、データが主役となります。ビジネスに精通した担当者や分析担当者は、監督のような役割と位置づけます。
フェーズ1:ビジネス状況の把握
まずはプロジェクト目標を設定します。企業内における各々の課題を明確にした上で、データ分析プロジェクト全体をプランニングします。データ分析を行うことそのものが目的ではありませんので、ビジネス状況をマーケティング担当者の観点から数値として正確に把握し、テーマを選定していくことが肝要です。
データ分析プロジェクトを効率的かつ効果的に進めるためにはビジネスセンスに依存する部分が大きく、特にこのフェーズ1においてはビジネスエキスパートとして自身が属する業界や自社の状況をつかみ、課題と目標を定義する必要があります。
具体的なテーマとして、DMのレスポンス率を向上させたい、スイッチャー(退会者)を減少させたい、優良顧客を特定したいというような項目を設定し、目標数値、分析工程のスケジューリングも具体的に示しておくことが大切です。
フェーズ2:データの理解
データがあるからといって、すぐに分析をはじめたり、分析しやすいようにデータの加工をはじめる人がいますが、それよりももっと前にしっかりとデータの中身を理解しなければなりません。その上で、データ分析に利用できるのかどうか(または、利用すべきかどうか)を吟味する必要があります。
基本的にはデータ項目、量、品質を把握します。外れ値(データ分布上、数値的に懸け離れたデータ)や欠損値(ブランクのデータ)などが含まれていることも多く、分析に使用できるデータであるか否かを判断する必要があります。また必要とされるデータ項目が欠落している場合には、データを集め直す必要があるかもしれません。
さらに、ここで改めてフェーズ1に立ち返る必要があります。このフェーズでの調査結果を踏まえてデータがビジネス目標を達成するのに必要十分な内容であるかを検討する必要があるからです。使用可能なデータでなければ、目標に見合った分析ができないという判断をしなければなりません。ここでの判断がデータ分析の成否を大きく左右します。
またシステムインフラの課題として、データ処理をするうえでコンピュータのスペックがデータ量に適合したものであるかどうかも把握しておかなければなりません。膨大なデータ量を低スペックなパソコンでデータ処理することには無理があり、データ分析プロジェクトを円滑に進められない原因にもなりますので、注意が必要です。
フェーズ3:データの準備
データ分析の前処理として、使用可能なデータを分析に適したデータに整形していきます。これをデータクレンジング(洗浄)と呼びます。
データの良し悪しによって分析結果が大きく左右されることになりますので、結果的にフェーズ2とこのフェーズ3にすべてのデータ分析行程の中で最も多くの時間を費やすことになります。(案外見落とされがちですが、データ分析そのものよりも、データ分析に使用するデータの整備の方に時間を要することの方が普通です。)
すでにデータ・ウェアハウスを構築していたとしても、データ分析にとって最良のデータであるとは限りません。ここでの作業は地味で目立たずにコツコツと進めていく工程となりますが、すべての工程の中で最も大切なフェーズです。
このフェーズでの処理は、大きく以下となります。
① 欠損値処理
分析対象のデータに欠損値が含まれている場合には、データ演算の正確な処理ができなくなってしまいます。欠損値がブランクとして意味を持つ場合でない限りは、それらを意味のある定数で埋めるか、削除しなければなりません。
② データ型の整備および正規化
分析手法により量的データ(数値)を必要とする場合と、質的データ(記号)を必要とする場合があり、これらを混在させてはいけません。ここではデータ項目のデータ形式を後続処理に適した形に変換します。
誕生日データから年齢データへの変換や、商品データと顧客データの結合などもここでの処理となります。またデータの冗長性を排除するための正規化も行います。
これらにより、繰り返しのある項目の独立化や他項目からの間接演算で得られる同一内容を除去し、信頼性が高く無駄のないデータを作り出すことができます。
③ サンプリング
大規模なデータを処理する場合には、状況によってはサンプリングによりデータ件数を絞り込むこともあります。サンプルデータを用いることで、迅速に、全体の概観をつかむことができます。
ただし、サンプリングを適用すべきでない場合もあります。たとえば、購買トランザクションデータから個々人の売上総計を集計して後続処理するような場合や、データの異常値検出処理のような場合には、全件処理が前提となります。
④その他
アンケートや掲示板などの自由記述文、あるいは雑誌、新聞の記事などを分析データとするテキストマイニングにおいては、これらテキストデータの形態素解析(単語の分かち書き)をした上で、データ準備を行う必要があります。
また、Webマイニング(ホームページのアクセスをベースとした分析など)の場合には、Webログの形式によってその準備方法が異なります。
【一口メモ】分かち書き
分かち書きとは、英語のようにことばの区切りに空白を入れる書き方のことです。
漢字カナ交じりの日本語文では通常分かち書きをしませんが、日本語以外の世界の言語では、むしろ分かち書きをするものの方が多いといえます。
フェーズ4:モデル作成
さて、ここまで準備ができて初めてモデルの作成となります。モデルとは、適した手法を用いて作成され、学術的な裏付けに立脚したデータ処理をするための機能といえます。
モデル作成のための手法は数多くありますが、代表的なものとして、相関分析、回帰分析、マーケットバスケット分析、クラスター分析、遺伝アルゴリズム(GA)、決定木、ニューラルネットワークなどがあります。
本書ではこのうちのいくつかについては簡単に解説しますが、詳細は他書に譲ります。一般的にCRMの実現などの場合には、顧客、商品、市場などを有機的に組み合わせて分類や予測モデル作成を行います。最近では、GA(遺伝アルゴリズム)などを適用する例も増えています。遺伝アルゴリズムは、生物界の進化の仕組みをモデル化した最適解の探索手法です。
いずれにせよ各手法ともに長所もあれば短所もあるため、それらを理解したうえで適切な状況で使い分けていくことが必要です。
また、万能なデータ分析手法は存在しません。データ分析担当者がテーマごとに適切な分析手法を選択する必要がありますが、現実的には複数の手法で分析を行った上で、ビジネス感覚から最も当てはまると考えられるモデルを選択することが多いことも実情です。
このようなモデル作成には高度な技術と深い見識を要するような印象を持つ読者も多いかもしれませんが、試行錯誤は必要ですが誰でも作り上げていくことのできるものです。
フェーズ5:評価
モデル作成のフェーズでは、複数の手法を反復的に実施することが普通ですが、同じように、CRISP-DM全体についても各フェーズのプロセスを繰り返し行う必要があります。
データの中に潜む関連性や特徴がその時々で変化することもあります。そのため、タイムリーで精度の高いモデルを作り続けていかなければ、意思決定に必要なナレッジが陳腐化してしまうことになります。
このフェーズでは、フェーズ1で明確に定義したビジネス目標を達成するのに十分なモデルであるかを、ビジネスの観点から評価します。評価に際しては、具体的な数値を得るための実験(制約を設定して、分析結果をビジネスに反映する)を行うこともあります。
このフェーズでも、ビジネスエキスパートの役割は重要です。モデル作成の結果をビジネスの展開につなげることが、現実的に有効かどうかを判断する必要があるからです。
フェーズ6:展開/共有
データ分析した結果をビジネスに適用するための具体的なプランニングを行います。データ分析の結果として、特定の分類に属する顧客にDMを送付したり、商品の陳列を変えたり、という単純なものも含め、利益率の向上や業務効率化を目的としてフェーズ1で設定した目標を達成するための具体的なアクションにつなげていきます。
このようにデータ分析を実践することは、効果を最大限に引き出すために大変有効なものです。しかしながら、データ分析も万能ではないということに注意が必要です。
何らかのデータが存在しているからといって、それをやみくもに分析しても、有益な結果が導かれるとは限りません。データ分析は、その過程においてどのようにデータを加工するのか、数多くの分析アルゴリズムの中でどの手法を用いるのかによって、現実的な有用性のある結果であるかどうかに大きな違いを生みます。また分析結果をどう解釈するかによって、結果を踏まえたビジネスアクションも異なります。
この記事が気に入ったらサポートをしてみませんか?