
データサイエンスの進め方。プロジェクトの各フェーズ、その中身を解説

データサイエンスの時代
データサイエンスが人口に膾炙するようになって久しいです。
数年前にデータサイエンティスト協会から取材を受けまして、自分自身がどのようにデータサイエンスの取り組みを前職の楽天で始めてきたかについて触れつつ、必要なスキルやマインドについてお話しました。
現代は、データサイエンス、また、ビッグデータ、IoT と AI の時代と言われてそれらを背景にDX(デジタルトランスフォーメーション)の必要性が叫ばれています。起点となるのはデータ活用です。データを分析し、またそこからのアナリティクスにより予測・最適化を行い、アクションにつなげていく。それをもってビジネスや社会をも変えていくデータサイエンス、データアナリティクスはとてもエキサイティングかつやりがいのある領域だと思っています。
データの分析と活用、データに基づく意思決定と問題解決、データ駆動型の戦略策定と遂行は、データサイエンス、データアナリティクスの業務のコアです。今回は、データサイエンスのプロジェクトにおいて、実際にどのようなアプローチ、ステップで業務を進めていくかについて解説してみようと思います。
データサイエンスプロジェクトのステップ
データサイエンスのプロジェクトは、ビジネスの目標に対するデータ分析と活用に関連するすべての要素から構成されます。
基本的には、「問題・仮説の定義」「データ収集」「データ処理」「探索的データ解析」「特徴量設計」「モデル構築」「可視化・コミュニケーション」「デプロイ」「モデルの保守・運用」の作業ステップによって実行されます。
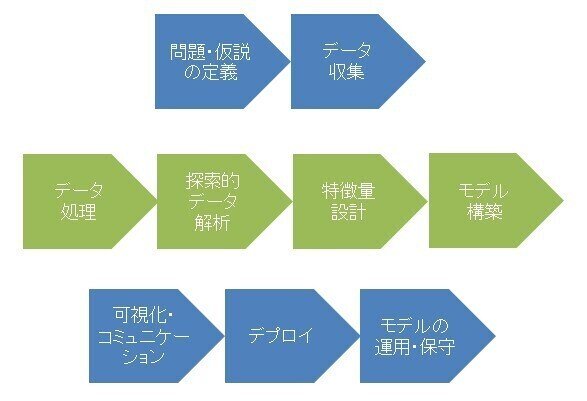
図)データサイエンスプロジェクトのステップ
以降、各ステップについて解説していきます。
問題と仮説の定義
まずデータサイエンスのプロジェクトに限らず、全てのプロジェクトにおいて解くべき問題の定義をすることは、プロジェクトの成否、そして運命を左右することになると言っても過言ではありません。
プロジェクトが解くべき問題は、より大きな問題の一部であり、またプロジェクトの目的も、自社組織全体の目標につながっていくものとして定められます。そのため、前提として、まず自社・自組織の業界における問題を認識しつつ、そして、自社・自組織のデータ活用における目標(KGI)を理解しておくことは大切です。それにより、プロジェクトの位置づけを整理し、正しくプロジェクトを計画することができます。
前提が確認されたら、関連する情報を調査しながら、プロジェクトが解くべき問題とその理由を識別し、そしてプロジェクトの目的を明確化しましょう。ビジネスにおけるどのような困難を解くか確認し、それによってどのような効果(KPI)を実現したいのか、プロジェクトの価値を明らかにします。
次に、プロジェクトの問題を解き、目的を達成するためのアプローチ、解決策に関する仮説を定めます。
まずそのためには、問題の構造を洗い出しておく必要があります。そこにおいては、いわゆる Pyramid Principle や MECE 等のテクニックを用いて、問題をツリー上にその構成要素を漏れなく適切な粒度で分解していく作業が有用です。
そして、洗い出された問題の構成要素に対して、解決策をそれぞれ定めていきます。ここでは、ある程度、解決策の優先順位や実行可能性をビジネス知識も踏まえながら想定をしていきます。これら、問題とその構造、対応する解決策群、そしてその優先順位と実行可能性が初期仮説ということになります。
問題と仮説が定まってきたら、問題解決の目的と得たい効果から考えられるプロジェクトに期待される要件を洗い出し、タイムフレームを定め、解決策に必要と思われる利用可能なリソース(データはもちろんのこと、人材やインフラ)にあたりをつけて、データサイエンスプロジェクトとして成立するかどうかチェックしましょう。その際に、収集するデータや分析のやり方、あるいは、プロジェクト関係者の構成によっては倫理的配慮が必要になるケースもあるため、そのリスクの確認も行いましょう。そうすることで、プロジェクトの計画が具体化されていきます。
データサイエンスのプロジェクトにおいては、様々なデータやその分析手法、機械学習モデリングに対する知識も重要ですが、組織(経営)と現場をつなぐ、横断的なコミュニケーションも重要になります。問題と仮説の定義、プロジェクト計画の策定においては、主要なステークホルダーを特定し、関連する部署の利害関係者へのプロジェクトに関する賛同を得る必要があります。このデータサイエンスプロジェクトは、何を目的とし、どのような課題を解決して、どれぐらいのベネフィットを自社と関連部署にもたらすのか。それらをプレゼンして関係者のモチベーションを高めつつも、コストや必要となるリソース、関連部署の負担はどれくらいなのかもきちんと説明し、プロジェクト推進のための合意と意識合わせをしておくことが大切です。ここにおいてはデザイン思考の適用が役に立つケースもあるでしょう。
データ収集
問題と仮説が定義され、プロジェクトを進めることの合意が得られたら、次は、データサイエンスを適用するために必要となるデータの収集です。
多くの場合、企業はビジネス上の問題に取り組むために必要なデータを既にERPや各種のデータベースに所有しています。自社のコンタクトセンターの顧客からのフィードバックデータを用いるケースもあれば、Webサーバのログからデータを得るケースもあります。関連システムからAPIで取得してくる例もあるでしょう。IoTデバイスやセンサーのデータを使うこともありえます。ですが、解くべき問題と解決策によっては、それだけでは十分でないケースや、それ以外のデータが必要となるケースもあります。
その場合は、外部や新しいデータソースに目を向けます。外部には利用可能なデータが様々存在しています。従前、政府や学術機関、調査機関が発表している各種の統計データが存在します。マクロ経済指標、人口動態、天気予報のデータもあります。そして近年は、多くの団体により、多種多様なオープンデータも公開されています。
また、日進月歩を遂げているソーシャルメディアは、会話、投稿、写真、ビデオ、リツイート、シェア、フォロワーの急増等の形で、消費者やマーケットの動きを刻一刻と伝えています。更には、マーケティングリサーチ会社のパネルや、各インターネット企業・データ保有企業がそれぞれの利用制限の下で、属性データや統計データの提供を行っています。
仮説がしっかりと立てられていれば、収集したいデータもわかっているはずです。組織の内外のソースから解決策に必要と思われるデータを収集します。その際には、解決策(モデル)の構築にきちんとつながるかを留意してデータを集めましょう。
データの収集においては、気をつけなければいけないこととして、規制や各種法令の遵守もあります。業界毎の規制や、どの利用目的での同意を得ているのか、改正個人情報保護法やGDPRやCCPA等に代表されるデータ保護規則やプライバシー保護関連の動きに気をつけながら、利用可能なデータを収集しましょう。
データ処理
データを集めた後、必要になってくるのは、データをモデル構築において使える形に整えていくデータ処理の工程です。データプリパレーションやデータクレンジングとも呼ばれます。ここはデータサイエンスプロジェクトにおいても最も時間がかかるステップになります。
まず集めたデータを調査します。ここで変数のデータタイプとカテゴリーを特定し、どのようなデータ入っているかをざっと確認します。集めたデータは、見慣れないフォーマットや型を持っているかもしれません。不必要な値や、欠損(NULL値)、予期しない小さな値や巨大な値が含まれているかもしれません。データ項目とその値が整合していないケースもあります。重複があったり、名寄せが必要なケースも想定されます。
以前、商品データの整備に関してプロダクトカタログの記事でも言及しておりますが、ある商品ジャンルには詳細な属性データがあるけれど、違うジャンルには様々な欠損が存在するというのはよくあることです。
色やサイズ、素材の情報などが欠損しているジャンル等はよくあり、偏りはとても大きいです。更には、そもそも商品を製造しているメーカーや卸のデータが間違っているということも普通にあります。商品データに限らず、データサイエンスのプロジェクトは、このようなデータのありようとの戦いになります。
調査が終わると、データ処理によって使える形にもっていくことになります。まずは、不必要な値や、明らかにエラーと思われる値、すなわち、ノイズを取り除きます。そして一部のデータにおいて年齢や住所等の項目が空白だったり、必須項目が抜けていたり等の欠損値がある場合や、データがカテゴリ毎に不均衡があった場合の対応策を検討してデータ処理を行います。以下のデータ拡張の記事は処理作業の参考になるかと思います。
後続のステップで得られる洞察や作業次第では、このステップでのデータクレンジングやデータ拡張の作業を取り消して、違うアプローチによる処理でやり直すことがあります。実際の有用なモデル構築に至るまでは、このデータ処理の工程はある程度、ステップ間を反復しながら繰り返されるものになります。
探索的データ解析
次はよりデータの感触を掴むステップになります。探索的データ解析においては、データセット内の各特徴または複数の特徴を分析し、それらがどのように振る舞うか、関連性を持っているかを確認します。そうすることでデータの明示的な傾向と隠れた傾向を理解することができます。
具体的には、データの特性、傾向を意識しながら、変数を一つずつ検査します。変数の型が連続型であった場合は、主にデータセット内の平均値、中央値、標準偏差、歪度、尖度等の統計的傾向を調べます。カテゴリー型に関しては、出現する値の出現頻度を測定し、データの広がりを把握します。
関連性の分析においては、2変量解析を行います。連続型の場合は相関性を確認し、カテゴリー型の場合は、関連しているかしていないのかを調べます。
連続型における相関性を見る場合は、ヒートマップを作成します。例えば、身長と体重という2つの連続変数をX軸・Y軸のグラフにマッピングしていき、相関係数を確認したりします。この時に、多くのデータが示す相関関係から極端に外れた値があったら、それが行うべき分析や問題の解決に貢献しないノイズなのかどうかを検討する必要があります。また、相関係数が単に見せかけの相関である場合もあります。そのため、クロス集計分析を行い、データへの理解を深めていきます。
このような探索的なデータ解析においては、後述する可視化の手法やツールが、理解深化の助けになることもあるでしょう。積極的に、Tableau、Power BI、QlikView、RAWGraphs 等のツールを使いましょう。
データへの理解が深まって洞察を得た段階になると、説明変数と目的変数の特定も完了しており、データ間の図式が明確になってビジネスの変動要因が何であるかについて仮説を深めたことでしょう。例えば、ダイナミックプライシングの問題であれば、価格がいつ変動するのか、またその理由についての理解を得ていることでしょう。そして、モデル構築における特徴量になりそうな候補を考えつつ、次のステップに進みます。
特徴量設計
特徴量設計、あるいはフィーチャーエンジニアリングは、サイエンスというよりは、アートと言えるかもしれません。ここは、データサイエンティストの知恵と技工が結晶化するステップでもあります。そして、このステップもデータ処理や探索的データ解析と同様に、後続のモデル構築と評価の結果次第では、何回か立ち返ってやり直すことがあります。試行錯誤が求められる、モデルのパフォーマンスの向上のための反復的なプロセスです。
ビジネスにおける問題を理解し、それに対して効く解決策を構成する機械学習モデルを構築するためには、より意味のある入力データを作り出していく特徴量設計が必要となります。これは、問題とデータの本質的な意味に向き合っていく作業だと言えます。特徴量とは、モデルを説明しうる、事象の特徴を数値化したものです。変数の分布や特定の値の出現頻度、値が変化する傾向を踏まえた上で、有力な特徴量を変数から選んだり(フィルタ法)、複数のデータの特徴を組み合わせたり(ラッパー法)、カテゴリ型の変数を連続型に変換したり連続変数の範囲を狭めたり等します。変数同士の差をとったり、掛け合わせたり、比率をとったり、スケール変換したり、二乗したり、対数をとったり、距離をとったり、ペアにしたり、エンコードしたり、等などもありつつ、様々な工夫をこらして特徴量を作り上げていきます。業界特有の特徴量の選択もあります。例えば、金融領域でのAIによる株価の予測や資産運用モデルを構築する場合においては、インデックスを掛け合わせて特定の短期におけるリスクを排除する変数を作成する等が行われたりします。ドメイン知識も活用して特徴量を作っていきましょう。人間の洞察をいかにモデルに組み込んでいくか、人間参加型(HITL)の手法も有用です。
特徴量の設計を後続のモデル構築ステップと同時に行うケースがあります。例えば、決定木や、Lasso回帰等は学習ステップと特徴量の選択を同時に行います。画像認識においては、SIFTやHOGアルゴリズムで特徴量を算出する方法が長く知られていますが、最近は画像を取り扱う場合、ディープラーニングを使うことが当たり前になったため、特徴量の選択や設計はモデル学習の中で自動的に行われることが普通になってきました。逆に、そのような特徴量を自動的に計算する機能を活かし、ディープラーニングを特徴量抽出機として用い、実際の機械学習アルゴリズムは別のものを用いるというやり方もあります。これはなかなか興味深い方法です。言及し忘れましたが、特徴量設計をある程度自動化してくれる featuretools というPythonライブラリもあります。
特徴量は、モデルの精度をあげるだけでなく、モデルの見通しを高め、後続の過学習を防ぐ手段でもあります。以前、別記事で書きました、AIモデルの説明可能性にも関わってくることにも言及しておきます。
モデル構築
そして問題を解くソリューションにつながる、機械学習モデルを構築していくステップに入ります。
データを使ってモデルを学習させ、モデルを構築していきます。モデル構築自体は、データ収集・データ処理・特徴量設計に要求される労力と知識に比べると、比較的簡単なステップではありますが、戦略的・計画的に行うことが大切です。機械学習アルゴリズムにおいては、教師なし、教師あり、ディープラーニング等各種存在します。どれを用いるか、あるいは、複数組み合わせた複雑なモデルを作るのかは、定義した問題をどれぐらいの精度でどう解きたいかに関わります。
回帰等の統計的手法や決定木、アンサンブルラーニングに代表される教師あり学習の機械学習モデルを構築する場合、過学習を避けるため、一般にはデータとそれに対する正解のセットを用意することになります。このデータと正解が対応している、ということをトレーニングしていくわけですが、ここで交差検証やROCによって本番でも機能していく汎化性能を確保します。交差検証の適用では、データと正解のセットを3つに分けますが、詳細は以下記事をご参照ください。
ディープラーニングを使う場合は、通常、大量のデータを学習する前提となるので交差検証を行うにはコストがかかり、それゆえデータセットの分割等はしないことが一般的です。
さて、ここで複数の機械学習アルゴリズムで、モデルを学習させて構築します。Logistic 回帰、決定木、ナイーブベイズ、GBT、ランダムフォレスト、XGBoost、そして、場合によっては、CNN、RNN、LSTM等のディープラーニングモデルも含みます。それぞれの精度を比較しつつ、精度が一番高いモデルが必要なのか、それともある程度の精度があり他システムとの組み合わせが容易なモデルが必要なのか等の判断ポイントを考えます。その際に、パフォーマンスを向上させるために複雑でないモデルは何がありうるか、という問いを立てることも有用です。高度な手法を使えば、より優れたモデルを作ることができますが、複雑すぎると社内でのコミュニケーションが難しくなり、結局使われないものを構築してしまいかねません。そのような点も踏まえながら総合的に評価し、定義した問題の解決に一番向いているモデルを選択します。
ここまでも何度か言及してきましたが、データ収集から始まるモデル構築は、イテレイティブなプロセスです。何事も最初からうまくはいきません。問題解決につながるモデル構築を目指して精力的に試行錯誤を繰り返しましょう。
可視化とコミュニケーション
前項でも触れましたが、モデルのわかりやすさと社内コミュニケーションは、モデルの社内での有用性を決める重要なポイントの一つです。
モデル構築の後、実際にそれをビジネスに展開していくためには、プロジェクトの関係者における意思決定を要します。百聞は一見にしかずと言います。説得力のあるビジュアルやストーリーテリングのスキルがなければ、データやモデルの潜在的な価値の多くは失われてしまいます。
説得力のあるビジュアルとしてインフォグラフィクスの手法が使われることがあります。前述した各種BIツールに加え、Infogram、Visual.ly 等ビジュアル化をサポートするサービスもあります。また、Echairs、D3.js、Plot.ly、Chart.js、Google Charts等の可視化を助けるライブラリも存在します。これらを用いてプロジェクトで使うダッシュボードの表現力を高めておくことも助けとなるでしょう。
ストーリーテリングにおいては、プレゼンテーションのスキルも重要です。以下は、プレゼンテーションテクニックに関する記事です。こちらも参考になるかと思います。
これらツールやテクニックを駆使しながら、データからの洞察と構築したモデルの効果をわかりやすく、インパクトのある形でステークホルダーに伝え、ビジネスへの展開につなげていきましょう。
デプロイ
モデルの構築と評価、そしてGo Liveの意思決定がが完了したら、いよいよビジネスへデプロイしていきます。このステップでは、データサイエンティストは、データエンジニアやソフトウェア開発者を含む多くの関係者と協力することが一般的です。
定義された問題と仮説に対する解決策を動かします。顧客にパーソナライズされたサービスを提示することかもしれませんし、ダイナミックに需要を予測していくことかもしれません。あるいは、音声認識や画像認識で自動化を果たしていくことかもしれません。それら機械学習モデルを本番のサービスに組み込んで稼働させていきます。
オフラインでトレーニングされた機械学習モデルを、そのままサービスとして稼働させるのは基本的に困難です。モデルを本番用に再トレーニングし、必要となるデータのインプットや変換を前処理工程のパイプラインとして組み込むことが通常の作業になります。アプリケーションによっては、UI/UXの設計と開発も前提となるでしょう。ケースによっては、ユーザー対応のオペレーションも設計し、関連部署と連携しておく必要があります。それら一連の作業を経て、モデルはデプロイされることになります。ここにおいては、失敗が発覚した際に以前のバージョンにロールバックできる担保も重要です。
上記デプロイの工程は多くの関係者を巻き込み、手作業でやられることが多くありますが、プロジェクトが自分たちでデータモデルを本番に展開できるインフラが整備されているのが理想です。そのようなデータサイエンスプロジェクトのためのプラットフォームが存在し、管理されたデプロイジョブによってリリースが実行されている状態であると、次のステップで言及するMLOpsの導入も容易になります。
運用と保守
機械学習モデルが実際のビジネスの場で稼働を始めた後は、その運用と保守のフェーズに入ります。ここでデータサイエンティストは、エンジニアに加えて、運用担当者ともコラボレーションを行っていきます。
機械学習モデルはデプロイされた直後がもっとも高い精度を持っており、以降時間の経過とともに精度が劣化していくのが普通です。これは、コンセプトドリフトといわれるもので、モデルを取り巻く環境や世の中そのものが変化していくことで、モデルが前提としていた変数の有力さ度合いや特徴が学習をしていたときとは異なってしまい、予測精度が劣化してしまうという現象です。また、ビジネス要件の変化や業界の規制の変更等で起きることもあります。これは冒頭で引用したインタビュー記事において言及している「モデルリテラシー」にも関わるところです。
それゆえ、運用時においては、機械学習モデルの品質を維持するための評価と保守の計画をプロジェクトに含めることが重要です。例えば、パフォーマンスをモニタリングし、可視化ツールも駆使しながらステークホルダーとともに定期的にレビューします。そして、本質的なモデルの劣化が認められた場合にはモデルの再構築と再訓練を実施し、モデルをアップデートするような対処を行います。データが時間の経過とともに変化していくことを予測し、どのようなサイクルでレビューするかを織り込んでおくことが鍵です。
もちろん、観測されたパフォーマンス低下が、モデルの本質的な劣化を指しているのではなく、一時的な現象で精度が下がっているように見えているだけということもあります。これは、劣化とは異なり、データのノイズということになりますが、精度低下が一時的なもので回復していくものなのかどうかを客観的に判断できるようにしておくことで対応します。
また、そのような人手での個別の判断を排し、自動的にデータの洗い替えとモデルの再学習を行っていくことでコンセプトドリフトに対処するというやり方もあります。例えば、金融マーケットにおけるインデックスの予測モデルの運用として、毎月最新の過去半年分のデータをもってモデルを再構築する、とか、3ヶ月毎に複数の機械学習アルゴリズムの中で最も良いものを選び直す、という感じです。DevOpsにおけるCI(継続的インテグレーション)/CD(継続的デリバリー)に通じるやり方であり、MLOpsでは、CT(継続的トレーニング)とも呼びます。運用と保守にかかるコストを考えた場合は、そのような自動化も効果的です。
MLOpsでモデルの構築とデプロイを含めて自動化していくことは、機械学習モデルの実戦投入までの時間を短縮し、運用・保守コストを削減することにつながります。結果、課題解決までの効率性を高め、プロジェクトチーム及びステークホルダーの議論も本質的な部分にフォーカスでき、より俊敏で戦略的な意思決定ができるようになるでしょう。
終わりに:データサイエンスを俯瞰し、プロジェクト実行を支える枠組み
以上、データサイエンスのプロジェクトにおいて、実際にどのようなアプローチ、ステップで進めていくかについて解説しました。
データサイエンスプロジェクトは見てきたように、長いステップから構成されますが、最終的には自社組織の課題解決につながるビジネス結果を出し、目的を達成できるかどうかによってその成否が決まります。個々のステップにおけるデータ探索やとるべき方法論やツール、あるいはステップ毎の品質に深く入り込み過ぎず、常にプロジェクト全体を見渡した価値提供を心がけることが肝要です。
ステークホルダーとプロジェクトの遂行と成否を共有するために、データサイエンスプロジェクトを俯瞰して解決すべき問題や達成すべき目標にとって何が最適かを問う際には、AI Canvas というフレームワークがヒントを与えてくれるかもしれません。こちらの記事もご参照ください。
また、より広い視点に立った組織全体へのパースペクティブをもってデータサイエンスプロジェクトのKSFをとらえるには、データドリブン戦略の記事で示した枠組みが有用です。この枠組みに沿って全社のパーパスを設定し、データを整理し、基盤を整備してケイパビリティを高めた組織においては、個々のデータサイエンスのプロジェクトもその位置づけを明確に理解し、スムーズにデータの収集から価値の実現まで、その遂行を進めることができるようになるでしょう。
この記事が気に入ったらサポートをしてみませんか?