
Llama 2のLLM(モデル)をGGUFに変換する

なぜ、こんなことを思われるかもしれないが、自宅のPCはグラボは積まれているが、とてもではないがAIの分野で処理されている性能はない。従って、GPUを使わず、CPUとメモリで処理させたいという要望が出てきた。奇跡的にCPUで処理させているツワモノがいたので、ありがたく使用するためのモデルの変換である
前提
Windowsのメモリは16GBはあった方がいい。ざっくり、モデルを使用したときに10GB程度は間違いなく消費しているので、それより下は難しいかもしれない

Llamaのモデルのダウンロードが完了していること
事前準備
後述するが、llama.cppを使用するにあたり記載のあった
w64devkitのfortranを含むzip(w64devkit-fortran-1.20.0.zip)をダウンロードして解凍しておくこと。実はfortran入りを使う理由は分からないのだが、llama.cppのプロジェクトに記述があったので素直に従うことにした。なお、処理に必要なmakeが私のWindowsの環境下では使えなかったので、w64devkitを使うことにした理由となる
手順
今回はllama.cppプロジェクトを使用する、ほぼ、書いてある通りに実行しているが、手順として起こしていく
Git Cloneと関連ライブラリのインストール
まずは、適当なディレクトリを用意してgit cloneでプロジェクトを複製する。合わせてプロジェクトにはrequirements.txtが用意されているので関連ライブラリをインストールしておく
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
python -m pip install -r requirements.txtw64devkitを立ちあげて、llama.cppをmakeする
makeするディレクトリは、llama.cppのディレクトリだ
makeLLMをGGUFに変換する
convertはllama.cppで用意されたプログラムだ。対象となるオブジェクトはmetaでダウンロードしてきたLLMである。2行目を実行すると同ディレクトリに同じ容量(12GBくらい)のggufファイルが出来上がる。4行目で4GB弱に圧縮されたggufファイルが出来上がる。16bitだったものを4bitに量子化しているとのことだが、ざっくり1/4化されたことは分かった。ただ、16bitで表現していたものを4bitで表現していることがヤバイ。時間があるときにどういうことかは知りたいと思う。ソースコードを見ればいいんですかね?
# convert the 7B model to ggml FP16 format
python .\convert.py ..\llama\llama-2-7b-chat\
# quantize the model to 4-bits (using q4_0 method)
.\quantize.exe ..\llama\llama-2-7b-chat\ggml-model-f16.gguf ..\llama\llama-2-7b\ggml-model-chat-q4_0.gguf q4_0出来上がり
ggml-model-q4_0.ggufとなっている。
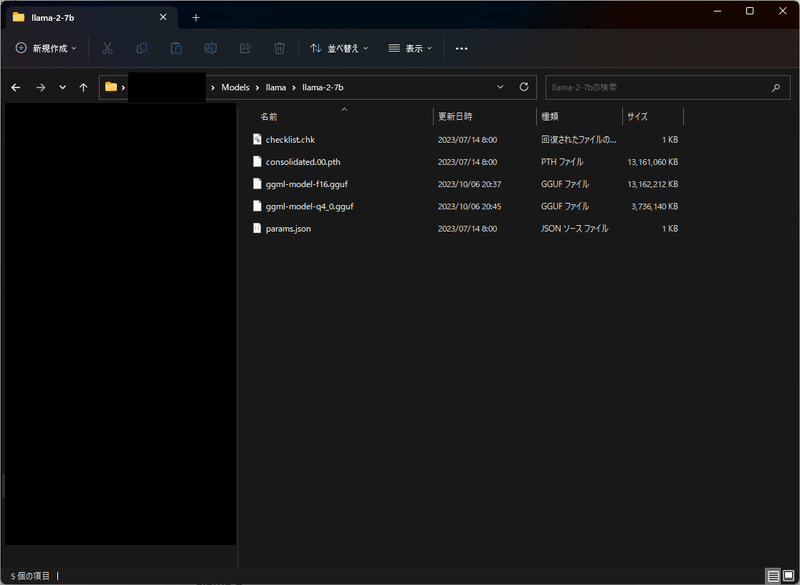
同様に7B-chatモデルからggml-model-chat-q4_0バージョンも作っておいた
参考
llama.cpp
Requirements Files
参考にしたブログ
llama.cppを使ってインストールからプログラムの実行まで行っている、Pythonでの扱い方は別の記事で扱う
CPUで動くことを知ったブログ
requierments.txtの使い方について知ったブログ
python -m pip installとpip installの違いについて書かれていたブログ、よく分かっていないのでChatGPTやオフィシャルサイトでも調べてみたいと思う
余談:Fortranがw64devkitで使えるのでワクワクしてきた記事、クラシックな言語なのだが、今は学校の授業で扱っているのだろうか。中々、昔の言語というのは触る機会がないのでオリジナルのfortranでないにしろ貴重だ。
おわり!