
GPTを活用して簡単にテキスト解析をする方法 -ワードクラウド編-

ChatGPTとGoogle Colabratoryを活用してワードクラウドを作成するやり方に関してまとめた記事です。
プログラミングに関してそこまで詳しくいない企画職の方でもできます。
ワードクラウドの作成に挑戦
前回の記事ではテキスト解析のうちで”感情分析”と”カテゴリー分類”のやり方を紹介しました。
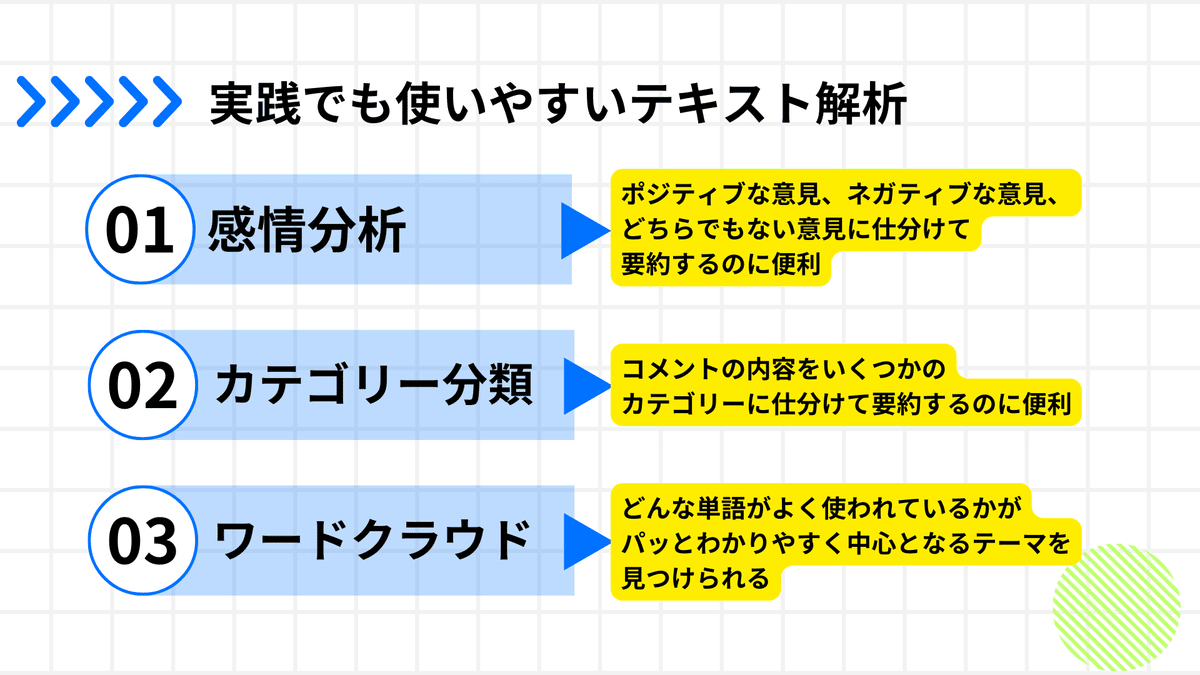
この記事ではワードクラウドを作成するやり方を紹介しようと思います。
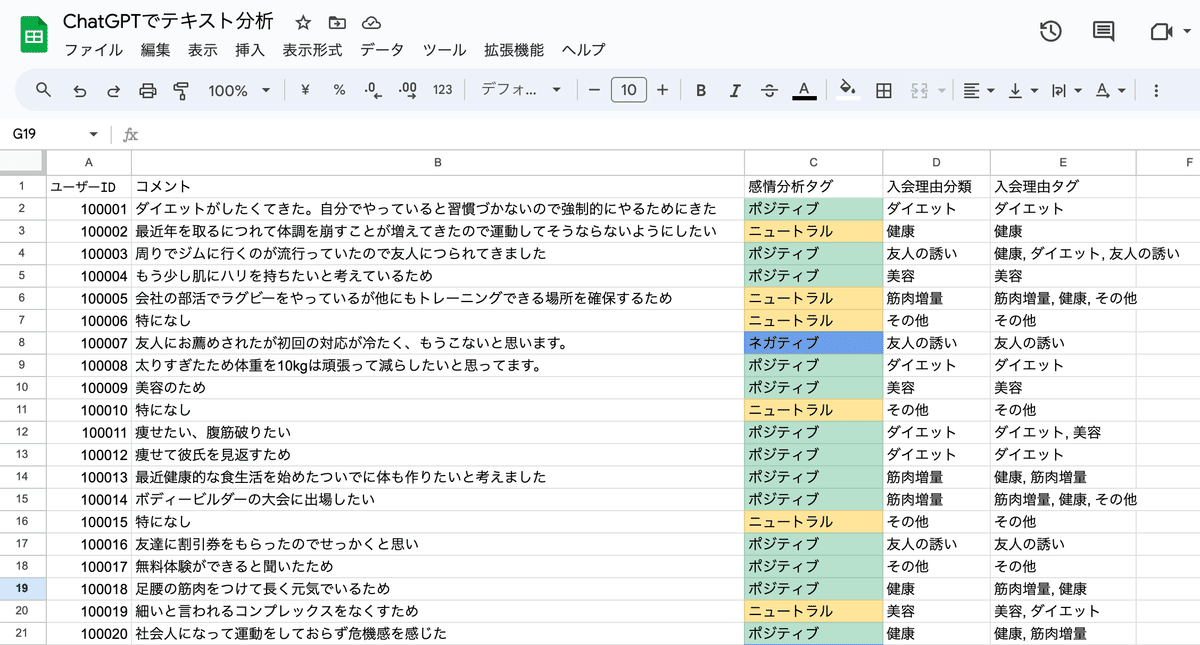
使うデータは前回作成した、ジムの入会理由のコメントを使用します(みなさんはアンケートのフリーコメントの結果などを活用してみてください)。
プロンプト for ワードクラウド
今回はワードクラウドを作成するために以下のプロンプトを作成しました。
使う際は”Advanced Data Analysis”の機能を活用してください。
”Advanced Data Analysis”の設定方法は以下のようにChatGPTのGPT4のタブにカーソルを合わせると出てくるので選択してください。

設定をするとファイルを添付できるようになるので、データが入ったExcelかCSV形式のファイルを添付し、以下のプロンプトを投げてください。
#役割
あなたはデータアナリストです。
定性データの分析のアシストをしてください。
-分析言語
Python
#インプット
ChatGPTで添付したテキスト分析のExcelデータ
#命令
”コメント”カラムのデータを使って、ジムへの入会理由のニーズを分析してください。アウトプット形式は{-アウトプット1}を参照してください。
またGoogleColabでワードクラウドが可視化できるコードを書いてください。
言語は{-言語}に従ってください。
形態素解析にはJanomeを使ってください。
コードには必要なライブラリのインストールのコードも必ず書いてください。
ワードクラウドのインプットは添付したデータです。
OSに関係なくGoogle Colabで扱えるフォントで日本語を可視化してください。
#アウトプット
{-アウトプット1}
カラムのテキストの内容の要約とそこから見えるニーズを簡潔な表現で出力してください。
{-アウトプット2}
ワードクラウドが可視化できるPythonコードこちらのプロンプトを投げるとPythonベースでワードクラウドを作成してくれるためのコードが書かれます。
{#命令}の
”コメント”カラムのデータを使って、ジムへの入会理由のニーズを分析してください。アウトプット形式は{-アウトプット1}を参照してください。
の部分は自由に変更していただいて問題ないです。
ただ、
またGoogleColabでワードクラウドが可視化できるコードを書いてください。
言語は{-言語}に従ってください。
形態素解析にはJanomeを使ってください。
コードには必要なライブラリのインストールのコードも必ず書いてください。
ワードクラウドのインプットは添付したデータです。
OSに関係なくGoogle Colabで扱えるフォントで日本語を可視化してください。
の部分はGoogle Colaboratoryで動かすためにチューニングした部分なのであまり変更することはオススメしません。
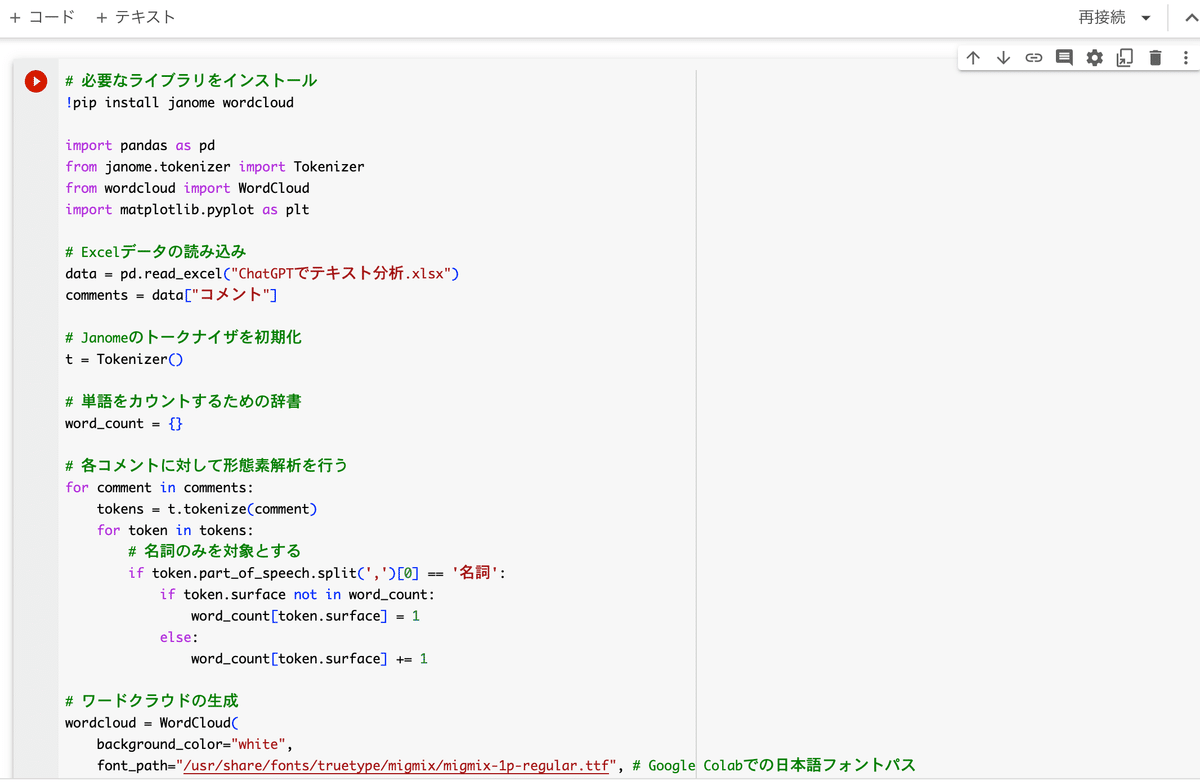
こちらのプロンプトを投げると要約結果のアウトプット1と以下のPythonコードが返ってきます。

# 必要なライブラリをインストール
!pip install janome wordcloud
import pandas as pd
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Excelデータの読み込み
data = pd.read_excel("ChatGPTでテキスト分析.xlsx")
comments = data["コメント"]
# Janomeのトークナイザを初期化
t = Tokenizer()
# 単語をカウントするための辞書
word_count = {}
# 各コメントに対して形態素解析を行う
for comment in comments:
tokens = t.tokenize(comment)
for token in tokens:
# 名詞のみを対象とする
if token.part_of_speech.split(',')[0] == '名詞':
if token.surface not in word_count:
word_count[token.surface] = 1
else:
word_count[token.surface] += 1
# ワードクラウドの生成
wordcloud = WordCloud(
background_color="white",
font_path="/usr/share/fonts/truetype/migmix/migmix-1p-regular.ttf", # Google Colabでの日本語フォントパス
width=800,
height=800
).generate_from_frequencies(word_count)
# ワードクラウドの表示
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()Google Colaboratoryを起動する
Google ColaboratoryはGoogleが提供している分析ツールで一定の分析であれば無料で実施できます(これを無料なんだからすごいですよね)

こちらにログインしてファイルタブから新規作成すると以下の分析画面に遷移します。

こちらにデータをアップロードして、先ほどChatGPTが出してくれたPythonコードを入力してShift+Enterを押すと実行してくれます。
すると実行が始まります。
しかし、今回のコードを実行すると以下のエラーが出ました。

こちら理由はフォントがインストールできていないからなのですが、Pythonに慣れていないとどうすればいいんだとなると思います。
※現段階だと”Advanced Data Analysis”を使いこなすにはある程度Pythonや分析の素養はあった方が良い気はしています。
こんな場合でもChatGPTの場合はこのエラーをそのままチャットで投げてどうしたらいいかと投げてください。
そうするとChatGPTがエラー解消方法を提示してくれます。

結果フォントをインストールしてくれる以下のコードを追加してくれました。
# Notoフォントをダウンロード
!apt-get -y install fonts-noto-cjk
# フォントのキャッシュを更新
!fc-cache -fv
# 必要なライブラリをインストール
!pip install janome wordcloud
import pandas as pd
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Excelデータの読み込み
data = pd.read_excel("ChatGPTでテキスト分析.xlsx") #ここを自身のデータに変更してください
comments = data["コメント"]
# Janomeのトークナイザを初期化
t = Tokenizer()
# 単語をカウントするための辞書
word_count = {}
# 各コメントに対して形態素解析を行う
for comment in comments:
tokens = t.tokenize(comment)
for token in tokens:
# 名詞のみを対象とする
if token.part_of_speech.split(',')[0] == '名詞':
if token.surface not in word_count:
word_count[token.surface] = 1
else:
word_count[token.surface] += 1
# ワードクラウドの生成
wordcloud = WordCloud(
background_color="white",
font_path="/usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc", # Notoフォントのパス
width=800,
height=800
).generate_from_frequencies(word_count)
# ワードクラウドの表示
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
こちらをGoogle Colabにコピペして実行してみると以下の結果になりました。

しっかりとワードクラウドを作成してくれていますね。
健康や友人、筋肉という単語の出現頻度が高いことがわかります。
この単語を元にテキストを再度確認してどんな理由で入会してくれたかを判断することができますね。
また、出現頻度が多い単語はユーザーにとって思いつきやすい単語でもあるので訴求する際にこれらの単語を中心に発信するのもありかもしれません。
まとめ
前回の記事と合わせてテキストデータを元にOpenAIのAPIやChatGPTを活用してテキスト解析を実施してみました。
Pythonをゴリゴリかけなくてもこれらの分析ができる様になったことで企画やマーケ職の人々ができることも一層広がっていきますね。
気になる方は是非試してみてください!
いいねとフォローもいただけると嬉しいです!
サポート費用は次の記事を書くための資金にさせていただいています。 ホワイトワーカーの在り方が問われていくこれからの時代にとって、考える職業の方々に価値あるナレッジを発信していくので応援よろしくお願いします! ※その代わり有料記事は作る気ないです。