
【1万文字】Stable Diffusion 3が凄すぎる!無料でMidjourney v6 を超え、幅広いカスタマイズ性を備えた『最強』の画像生成AIを紹介!

はじめに
こんにちは!歯ブラシは電動を使うタイプの女、葉加瀬あいです!
今回は、Stability AIが発表した最新のテキストから画像への生成モデルである「Stable Diffusion 3」について、その概要を詳しく解説していきたいと思います!
最近、AIによる画像生成技術が急速に発展しており、その中でもStable Diffusionシリーズは、オープンソースで提供されていることもあり、多くの注目を集めています。
そんなStable Diffusionシリーズの最新版であるStable Diffusion 3は、従来のバージョンと比較して、さまざまな点で性能が向上しているんです!
例えば、以前こちらの記事でもMidjourney の最新モデルである V6 のすごさについて解説したのですが
「Stable Diffusion 3」であればそういったMidjourney レベルの高品質な画像を簡単に作ることができます!
(しかもオープンソースなので無料という…。幅広いカスタマイズもできるので現時点で最強の画像生成AIなんじゃないかと思っています!)
例としてこちらの画像を見てみてください!すごいハイレベルですよね!


なお、私の記事を読む上での注意事項などをこちらで説明しておりますので、以下のプロフィール記事をご一読いただいた上で閲覧するようお願いいたします。
それでは、早速Stable Diffusion 3の概要について見ていきましょう!
最後に参考文献も載せているので気になる方はそちらを見てみてください!
Stable Diffusion 3の概要
フロー・マッチングを備えた拡散変換アーキテクチャ
Stable Diffusion 3は、フロー・マッチングを備えた拡散変換アーキテクチャに基づいて設計されています。
フロー・マッチングとは、画像生成における新しい手法の一つで、生成されたサンプルと真のデータ分布との間の確率的流れを見つけることで、より自然で多様な画像を生成できるようになる技術です。

また、拡散変換アーキテクチャは、ノイズを徐々に除去していくことで画像を生成するDiffusion Modelを、Transformerベースのアーキテクチャに適用したものです。

これらの技術を組み合わせることで、Stable Diffusion 3は、より高品質で自然な画像を生成できるようになっているんです!
なお、拡散変換アーキテクチャーに関してはこちらのStable Diffusion WebUI 基礎の投稿でも解説をしているので、興味のある方は、ぜひこちらで詳細をご確認ください!
800Mから8Bのパラメータ
Stable Diffusion 3は、そのパラメータ数が800Mから8Bの範囲になっています。
パラメータ数が多いということは、モデルの表現力が高いということを意味しており、より複雑で詳細な画像を生成できる可能性が高くなります。
ただし、パラメータ数が多くなるほど、モデルの学習に必要な計算リソースも増大するため、トレードオフの関係にあるんです。
Stable Diffusion 3では、このパラメータ数の異なる複数のモデルを提供することで、ユーザーのニーズに合わせて最適なモデルを選択できるようになっています!
顕著なテキスト生成能力
Stable Diffusion 3の特徴の一つとして、テキスト生成能力の向上が挙げられます。
従来のStable Diffusionでは、テキストから画像を生成する際に、テキストの内容を十分に反映できないことがありましたが、Stable Diffusion 3では、そうした問題が大幅に改善されているんです!

具体的には、複数の主題が含まれるプロンプトに対しても、それぞれの主題を適切に反映した画像を生成できるようになっており、また、テキストの誤字脱字にも強くなっているんです。

これにより、ユーザーは、より自然な言語表現で画像生成を指示できるようになり、AIとのコミュニケーションがよりスムーズになることが期待されます!
Stable Diffusion 3のパフォーマンス
Stable Diffusion 3は、その優れた性能が大きな注目を集めている画像生成モデルです。ここでは、人間の評価者による評価に基づいて、Stable Diffusion 3のパフォーマンスを他のモデルと比較した結果について詳しく見ていきましょう!
人間による評価に基づくパフォーマンス比較
Stable Diffusion 3の開発チームは、Stable Diffusion 3の出力画像を、SDXL、SDXL Turbo、Stable Cascade、Playground v2.5、Pixart-αなどのオープンソースモデルや、DALL-E 3、Midjourney v6、Ideogram v1などのクローズドソースモデルと比較し、人間の評価者によるフィードバックに基づいてそのパフォーマンスを評価しました。
この画像は、その評価結果を示したものです。縦軸は各モデルのパフォーマンススコアを、横軸は比較対象のモデルを表しています。

評価者は、各モデルの出力画像を見て、以下の3つの観点から最も優れた結果を選ぶように求められました。
プロンプトフォロー:出力画像が、与えられたプロンプト(テキストの指示)にどれだけ忠実に従っているか。
タイポグラフィ:プロンプトに基づいて、テキストがどれだけ上手に画像中にレンダリングされているか。
視覚的美学:どの画像が、より美しく、高品質に見えるか。
これらの評価基準は、画像生成モデルの性能を総合的に判断するために非常に重要な指標です。
プロンプトフォローは、モデルがユーザーの意図をどれだけ正確に理解し、反映できるかを示します。
タイポグラフィは、テキストを画像中に自然に配置し、違和感なく表現できるかを評価します。
そして、視覚的美学は、生成された画像の全体的な質の高さを判断する指標となります。
Stable Diffusion 3の優れたパフォーマンス
評価の結果、Stable Diffusion 3は、プロンプトフォロー、タイポグラフィ、視覚的美学のすべての観点において、他のモデルと同等か、それを上回るパフォーマンスを示しました。
特に、Stable Diffusion 3は、タイポグラフィの評価で他のモデルを大きく上回る結果となりました。
グラフを見ると、Stable Diffusion 3のタイポグラフィスコアは、他のモデルを大きく引き離していることがわかります。
これは、Stable Diffusion 3が採用しているMMDiTアーキテクチャやT5テキストエンコーダーにより、テキストの意味をより深く理解し、それを画像中に自然に表現できるようになっているためだと考えられます。
また、プロンプトフォローや視覚的美学の評価でも、Stable Diffusion 3は他のモデルと同等か、それ以上の高いパフォーマンスを示しました。
グラフを見ると、Stable Diffusion 3のプロンプトフォロースコアと視覚的美学スコアは、他のモデルと比べて非常に高い位置にあることがわかります。
これは、Stable Diffusion 3のRectified Flowによる柔軟な確率分布のモデル化や、高いパラメータ数を持つモデルの採用などにより、より自然で多様で高品質な画像を生成できるようになっているためだと考えられます。
これらの結果は、Stable Diffusion 3が現在の最先端のテキスト画像生成システムと肩を並べる、非常に高い性能を持つモデルであることを示しています!
ただし、今回の評価はStable Diffusion 3の開発チームによるものであり、第三者による客観的な評価が必要であることにも留意が必要です。
また、評価に用いられた画像のサンプル数や、評価者の人数なども、結果に影響を与える可能性があります。
より多くのサンプルと評価者による、大規模な比較実験が行われることで、Stable Diffusion 3の真の性能がより明らかになっていくことでしょう。
Stable Diffusion 3のパフォーマンスについては、今後も注目していく必要がありそうですね!
Stable Diffusion 3の特徴
Stable Diffusion 3には、従来のバージョンとは異なるいくつかの特徴があります。ここでは、その中でも特に重要な3つの特徴について詳しく見ていきたいと思います!
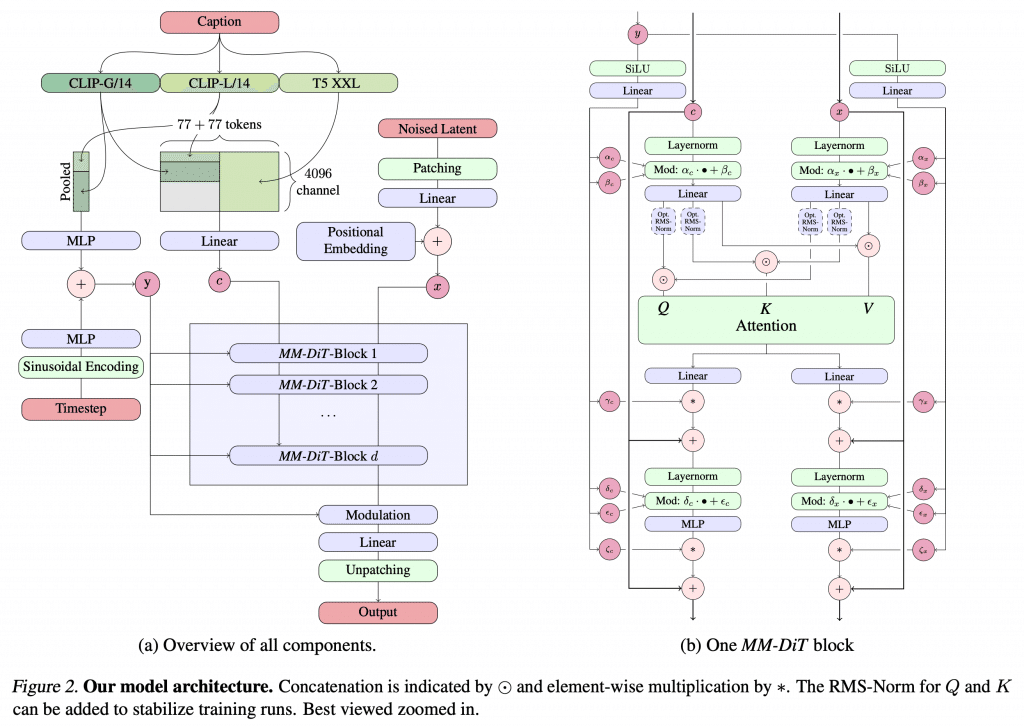
新たなアーキテクチャ「MMDiT」の採用
Stable Diffusion 3では、新たなアーキテクチャとして「MMDiT」(Multimodal Diffusion Transfomer)が採用されています。
● 例としてこちらの画像をみてください。

MMDiTは、テキストと画像という2つのモダリティ(データ様式)を同時に処理することができる、マルチモーダルなDiffusion Transformerモデルです。
具体的には、テキストと画像のそれぞれに特化した2つのトランスフォーマーを用意し、それらを並列に配置することで、テキストと画像の情報を融合しながら画像生成を行うことができるようになっています。
これにより、テキストの内容をより正確に理解し、それを画像に反映させることが可能になるんです!

MMDiTアーキテクチャは、従来のDiffusion Modelにトランスフォーマーを組み合わせたものと言えますが、その特徴は、テキストと画像という異なるモダリティを同時に扱えるところにあります。
従来のDiffusion Modelでは、画像生成の過程でテキストの情報を直接利用することができませんでしたが、MMDiTアーキテクチャでは、テキストと画像の情報を融合させながら画像生成を行うことができるため、より自然で意味のある画像を生成できるようになっているんです!
また、MMDiTアーキテクチャでは、テキストと画像のそれぞれに特化したトランスフォーマーを用意することで、それぞれのモダリティの特徴をより効果的に捉えることができます。
これにより、テキストの意味をより深く理解し、それを画像生成に反映させることが可能になっているんです!
MMDiTアーキテクチャは、Stable Diffusion 3の大きな特徴の一つであり、従来のDiffusion Modelでは困難だったテキストと画像の融合を可能にする、画期的な技術だと言えるでしょう。

推論の重み付けにRectified Flow(RF)を採用
Stable Diffusion 3では、推論の重み付けにRectified Flow(RF)と呼ばれる手法が採用されています。
● 例としてこちらの画像をみてください。

RFは、生成モデルの一種であるNormalizing Flowをベースにした手法で、データの確率分布を柔軟にモデル化することができます。
Normalizing Flowは、単純な確率分布から複雑な確率分布へと変換する一連の可逆な変換の組み合わせとして定義されます。

これにより、データの確率分布を柔軟にモデル化することができるようになるんです!
RFは、このNormalizing Flowを拡張した手法で、より効率的で安定した学習を可能にするために、いくつかの工夫が施されています。
具体的には、RFでは、Normalizing Flowの変換に制約を加えることで、より安定した学習を実現していると言うことになります。

これにより、Stable Diffusion 3では、より自然で多様な画像を生成できるようになっているんです!
RFは、Stable Diffusion 3の画像生成の質を大きく向上させる重要な技術の一つであり、従来のDiffusion Modelでは困難だった、多様で自然な画像の生成を可能にしています。

テキストエンコーダーとしてT5を採用
Stable Diffusion 3では、テキストエンコーダーとして「T5」(Text-to-Text Transfer Transformer)が採用されています。

T5は、自然言語処理の分野で広く使われているトランスフォーマーベースのモデルで、テキスト生成やテキスト分類など、さまざまなタスクに適用できることが知られています。
T5は、大規模なテキストデータを用いて事前学習されたモデルで、テキストの意味を深く理解することができます。
Stable Diffusion 3では、このT5をテキストエンコーダーとして採用することで、より高度なテキスト理解が可能になっているんです!
具体的には、T5は、入力されたテキストを、意味を捉えた上で、より抽象的な表現に変換することができます。

これにより、テキストの意味をより的確に捉えた上で、画像生成に反映させることが可能になるんです!
また、T5は、大規模なデータを用いて事前学習されたモデルであるため、幅広いドメインのテキストに対応することができます。
これにより、Stable Diffusion 3では、さまざまなジャンルのテキストから、より自然で意味のある画像を生成できるようになっているんです!

T5は、Stable Diffusion 3のテキスト理解の能力を大きく向上させる重要な技術の一つであり、従来のDiffusion Modelでは困難だった、テキストの意味を深く理解した上での画像生成を可能にしています。
Stable Diffusion 3の一般公開について
このように、Stable Diffusion 3は、従来のStable Diffusionでは困難だった、高度なテキスト理解に基づく画像生成や、ビデオの生成などを可能にする画期的なモデルです。
しかし、その性能の高さゆえに、一般公開に先立って、さらなる性能の向上と安全性の評価が必要とされています。
現在、Stable Diffusion 3は、先行プレビューのウェイティングリストの登録を受け付けています。(現在はキャンセル待ちということになっています。)
先行プレビューでは、限られたユーザーに対してStable Diffusion 3を使用してもらい、そのフィードバックをもとに、さらなる性能の向上と安全性の確保が図られる予定です。
ウェイティングリストへの登録は、以下のリンク先から行うことができます。
Stable Diffusion 3に興味のある方は、ぜひこのウェイティングリストに登録してみてください!
Stable Diffusion 3はテキストで詳細な修正やビデオの生成も可能!
Stable Diffusion 3には、従来のStable Diffusionにはなかった、いくつかの特徴があります。
その一つが、テキストによる画像の内容の修正です。
Stable Diffusion 3では、生成された画像に対して、テキストで詳細な修正を加えることができます。
また、Stable Diffusion 3では、ビデオの生成も可能になっています。
● 例としてこちらの動画をみてください。
「Stable Diffusion 3」がすごい。
— 葉加瀬あい (AI-Hakase) ✎. 楽曲制作+AI解説+保護猫活動🐾 をしている理系女子🎈 (@ai_hakase_) March 17, 2024
テキストでの修正に加えてビデオの作成もうできる!しかもとても高品質!もう言うことないですね...pic.twitter.com/WesCrvQiBt
テキストから静止画を生成するだけでなく、連続したフレームを生成することで、ビデオを作成することができるんです!
これにより、より動的で表現力豊かなコンテンツの作成が可能になりますよね。
アニメーションの画風の生成にも優れています。
さらに、Stable Diffusion 3は、アニメーションの画風の生成にも優れています。


アニメ調のキャラクターや背景を、自然に生成することができるんです!
東洋人や西洋人などの異なる人種の特徴をとらえた、リアルな画像の生成も得意
加えて、Stable Diffusion 3は、東洋人や西洋人などの異なる人種の特徴をとらえた、リアルな画像の生成も得意としています。
● 例としてこちらの画像をみてください。



とても自然に特徴を捉えた画像が生成できていますよね!
画像生成AIでは苦手とされていた、手の生成なども高い精度で行うことが可能
また、Stable Diffusion 3は、これまでの画像生成AIでは苦手とされていた、手の生成なども高い精度で行うことができます。
● 例としてこちらの画像をみてください。


指の本数や形状など、細部まで正確に再現することができるんです!

Stable Diffusion 3の動作環境
Stable Diffusion 3は、800Mから8Bまでの異なるパラメータサイズのモデルが提供される予定です。
これにより、消費者向けのハードウェア上でも動作可能になります。
特に、8BサイズのモデルはGTX 4090と24GBのVRAMで動作可能であることが確認されています。
ただし、モデルのサイズが大きくなるほど、必要とされるハードウェアのスペックも高くなるため、自分の環境に合ったモデルを選ぶ必要があります。
Stable Diffusion 3は、さまざまなサイズのモデルを提供することで、より多くのユーザーに利用してもらえるよう配慮されされる予定とのことです!
まとめ
今回は、Stable Diffusion 3について、その概要から特徴、パフォーマンス、一般公開に関する情報まで、幅広く解説してきました。
Stable Diffusion 3は、フロー・マッチングを使ったRectified Flowという生成技術と、MMDiTというモデルを採用することで、従来のStable Diffusionの課題であったテキスト表現の精度を大幅に向上させています。
また、テキストによる画像の詳細な修正やビデオの生成、アニメーションの画風の生成、異なる人種の特徴を捉えたリアルな画像の生成、手の生成など、これまでの画像生成AIでは困難とされていたさまざまな機能を実現しています。
パフォーマンスの面でも、他の最先端モデルと比較して、プロンプトフォロー、タイポグラフィ、視覚的美学のすべての観点で同等以上の結果を示しており、特にタイポグラフィの評価では他のモデルを大きく上回っています。
現在、Stable Diffusion 3は一般公開に向けた準備段階にあり、先行プレビューのウェイティングリストの登録を受け付けています。リリース後は、800Mから8Bまでの異なるパラメータサイズのモデルが提供される予定で、消費者向けのハードウェア上でも動作可能になる見込みです。
Stable Diffusion 3は、その高度な機能と、ユーザーフレンドリーな設計により、今後のAIによる画像生成の発展に大きく寄与することが期待されています。ぜひ、Stable Diffusion 3の登場に注目していきたいですね!
以上で、Stable Diffusion 3についての解説を終わります。最後までお読みいただき、ありがとうございました!
参考
SD3の画像:https://twitter.com/Lykon4072
🎈おわりに
いかがだったでしょうか。以上で本稿の解説を終了します。
今後も生成AIに関する記事を投稿していく予定ですので、フォロー・いいね をいただけると非常に励みになります。
また、私のプロフィール記事に関しても是非一読ください。
また、私はこういった生成AI技術の解説以外にも、保護猫活動なども行っておりますので、日々の応援なども含め、少額でも下記のリンクからご支援いただけますと幸いです。
ここまでご覧いただきありがとうございました!充実した生成AIライフをお楽しみください!
⚡X (Twitter) のフォローもよろしくお願いします!生成AIを使った面白いコンテンツなど発信して行きます🚀
ハッシュタグ:
#AI #AIモデル #AIイラスト #AI画像生成 #AI生成画像 #AIアバター #生成AI #画像生成AI #画像生成AIチャレンジ #StableDiffusion #StableDiffusionWebUI #StableDiffusionXL #Stable #SDXL #ControlNet #SpaceTimeUNet #動画生成技術 #画像生成 #アート #NFT #デザイン #プログラミング #txt2img #img2img #副業 #副業収入 #副業で稼ぐ #副業情報 #ネット副業 #ネットビジネス副業 #サラリーマン副業 #副業の教科書 #SNS #SNS活用 #SNSマーケティング #SNS集客 #SNS運用 #SNSブランディング #SNSマネタイズ #マネタイズ #メンバー #メンバーシップ #noteメンバーシップ #メンバー募集 #在宅 #ChatGPT #BingAI #Colab #GoogleColab #SageMaker #Paperspace #note書き初め #noteマネタイズ #AIとやってみた
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?