

#GoogleColab


【v1.1アプデ】SDXLモデルを半分に圧縮!?モデルをFP8に量子化してストレージを解放せよ!
24/08/25 15時頃追記(※スクリプトアプデしました)
こんな感じで、初期のローカル版のコード実行時に変換前のキャッシュが残るようになっています。C:\Users\ユーザーID\.cache\huggingface\hub\以降のフォルダにリポジトリidフォルダがあったら削除してください。
コードの改修が終わりましたので、お手数ですがローカル版ご使用の方は改めてダウンロードお願いいたし


Google Colab で FLUX.1 を試す
「Google Colab」で「FLUX.1」を試したので、まとめました。
1. FLUX.1「FLUX.1」は、「Stable Diffusion」の開発者たちが立ち上げた「Black Forest Labs」が発表した最新の画像生成AIモデルです。
2. FLUX.1 [dev]「Google Colab」でのFLUX.1 [dev] (ガイダンス蒸留モデル) の実行手順は、次のとおりです


【Google Colab】DALL-Eで一括画像生成!ガチャツールの使い方
こんにちは、Shinyaです。
私は普段、DALL-E 3を使ってAI画像を大量に生成しています。
DALL-E 3で画像を生成する方法としてChatGPT Plusがありますが、
ChatGPTのインタフェースだと1つのプロンプトでは1つの画像しか出力することができない。「再生成」ボタンを押せば別の画像も出力できるけど、時間もかかるし、使いすぎると利用制限を食らってしまう。
そこでDALL


ByteDanceの画像生成AIのSDXL-LightningのGoogle Colabでの使い方
ByteDanceといえば、tiktokの会社ですね。そこが、画像生成AIで、軽くて早く実行できるというSDXL-Lightningを出しましたので、Google Colabでの使い方を紹介します。
今回は、Google ColabでA100で上記のコードを少し修正して、画像を30枚作成できるコードとなります。
!pip install diffusersimport torchfrom di


Google Colab で試す Stable Cascade での新時代のテキスト画像生成
2024年2月13日、Stability AIより新モデル「Stable Cascade」がリリースされました。
https://ja.stability.ai/blog/stable-cascade
Stable Cascade モデルカードよりこのモデルは、Würstchenアーキテクチャに基づいて構築されており、Stable Diffusionのような他のモデルとの主な違いは、より小さな潜
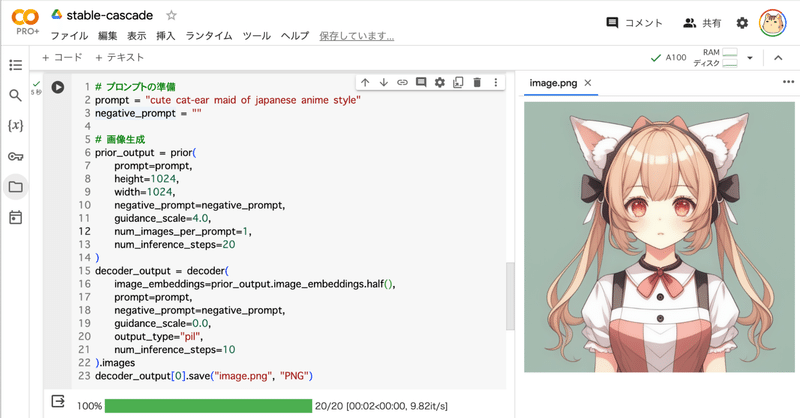
Google Colab で Stable Cascade を試す
「Google Colab」で「Stable Cascade」を試したので、まとめました。
1. Stable Cascade「Stable Cascade」は、「Würstchen」ーキテクチャをベースにした新しいテキスト画像変換モデルです。3段階のアプローチにより、一般消費者向けハードウェアでの学習とファインチューニングが簡単にできます。非商用利用のみを許可する非商用ライセンスの下でリリース

Google Colab で RPG-DiffusionMaster を試す
「Google Colab」で「RPG-DiffusionMaster」を試したので、まとめました。
1. RPG-DiffusionMaster「RPG-DiffusionMaster」は、マルチモーダル LLM (PRG) によって複雑かつ構成的なText-to-Imageの生成・編集でdiffusionモデルをマスターし、最先端のパフォーマンスを実現するフレームワークです。
核となる戦略

diffusers で LoRA を試す
「diffusers」で「LoRA」を試したので、まとめました。
1. LoRA「LoRA」(Low-Rank Adaptation)は、AIモデルの効率的な調整やカスタマイズのための手法です。手法は、モデルの重みを直接調整するのではなく、低ランク(小さい次元)の行列を用いてモデルの一部の重みを調整することにより、モデルの振る舞いを変更します。
この手法には、多くの利点があります。
「LoR

Google Colab で Stable Video Diffusion を試す
「Google Colab」で「Stable Video Diffusion」を試したのでまとめました。
1. Stable Video Diffusion「Stable Video Diffusion」は、「Stability AI」が開発した画像から動画を生成するAIモデルです。解像度 1024x572 で、14フレーム (2秒) または25フレーム (4秒) の動画を生成します。
2.

diffusers で ControNet の inpaint を試す
「diffusers」で「ControNet」の「inpaint」を試したので、まとめました。
1. ControlNet の inpaint「inpaint」は、画像の一部をマスクして、任意の領域のみ新しい画像を生成させることができる機能です。
2. Colabでの実行「ControlNet」で「inpaint」を行う手順は、次のとおりです。
(1) パッケージのインストール。
# パッ
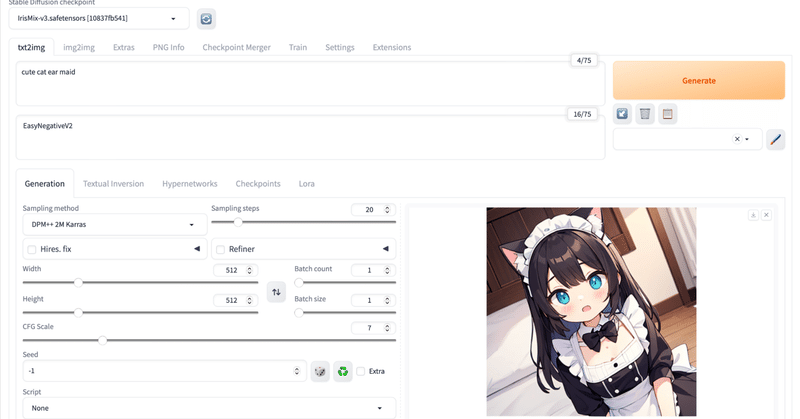
Google Colab で Stable Diffusion WebUI を試す
「Google Colab」で「Stable Diffusion WebUI」を試したので、まとめました。
1. Stable Diffusion WebUI「Stable Diffusion WebUI」は、「Stable Diffusion」で画像生成するためのWebUIです。
2. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メ
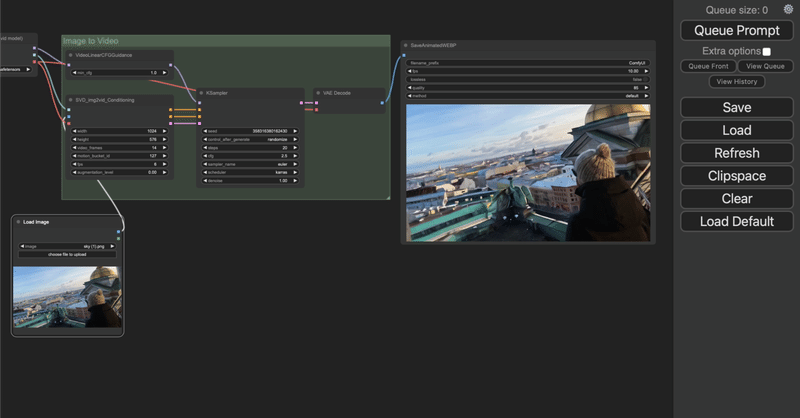
ComfyUI で Image-to-Video を試す
「ComfyUI」で Image-to-Video を試したので、まとめました。
前回
1. Image-to-Video「Image-to-Video」は、画像から動画を生成するタスクです。
現在、「Stable Video Diffusion」の2つのモデルが対応しています。
2. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) セットアップ。
前回と同様です。


簡単にSDXLベースの画像が生成できるFooocusの紹介(Colab利用者向け)
今回は、簡単にSDXLベースの画像生成を行うことができるFooocusを紹介します。
Foocusは、ControlNetを開発したlllyasviel氏が発表した画像生成AIのWebユーザーインターフェイスで、プロンプトを入力して1クリックするだけで簡単にSDXLベースの高精細な画像を生成することができます。
※2024.6.18追記 Animagine XL 3.1を追加しました。
※202

Google Colab で SSD-1B を試す
「Google Colab」で「SSD-1B」を試したので、まとめました。
1. SSD-1B「SSD-1B」(Segmind Stable Diffusion Model) は、「SDXL」(Stable Diffusion XL) を50% 小型化したバージョンで、高品質のテキストから画像への生成機能を維持しながら60% の高速化を実現します。
2. Colabでの実行Colabでの実行手