
NVIDIAが切り開いたAI半導体市場: 市場の拡大と細分化(2)ハイパースケーラー編

今回は、近年のNVIDIAの大躍進を支えるデータセンターでのGPUの大口需要の震源地であるハイパースケーラーと呼ばれるクラウドプラットフォーマーを題材として、彼らプラットフォーマーが自社開発するAIアクセラレーターについて、その概要や目論見について紹介したいと思います。
前回の大手半導体メーカー編で紹介したAIアクセラレーター界隈の5つのトレンドは、① 需給のギャップ、② コンピューティングアーキテクチャ、③ 汎用型と特化型、④ 自社開発を進めるクラウドプラットフォーマー、⑤ リソースの適材適所配置、の5つの背景によって動かされていると紹介しましたが、これらの5つの要素は全てが不可分な関係にあり、特にハイパースケーラーと呼ばれる巨大テクノロジー企業を題材にAIアクセラレーターを語る際には、より広い意味でのコンピューティングアーキテクチャの変化について触れる必要あります。
先日、現地2/21に行われたNVIDIAの2023年度Q4の決算説明会では、「Accelerated Computing Platform」という単なるGPUという半導体メーカーの枠をこえたコンピューティングの将来ビジョンとアーキテクチャを掲載したプレゼンテーション資料をNVIDIAが配布していましたが、ハイパースケーラー達も同様に、数えきれないほどの技術革新を生み出しながら、コンピューティングアーキテクチャを長年に渡って絶え間なく変化させ続けています。
今回は、そのような視点も踏まえて、ハイパースケーラーが自社で開発するAIアクセラレーターの現状について、1. マイクロソフト、2. メタプラットフォーム、3. Google、4. AWS、そして、5. IBMという流れで紹介して行きたいと思います。
前回の主要半導体メーカー編もよければご参考ください。
1. マイクロソフト「MAIA」
2023年11月にシアトルで開催されたマイクロソフトのイベント「Microsoft Ignite」において、同社が自社開発を進める2つの半導体が発表されました。ひとつがAIアクセラレーターの「Azure MAIA」(Microsoft AI Accelerator)で、もう一つがRISCプロセッサ「Azure Cobalt」です。
Azure MAIAは、マイクロソフト自身がAIおよび生成AIタスクに最適化したAIアクセレレーターで、Azure上で実行される膨大なAIタスクを高速かつ効率的に処理することを目的に、2024年の上期での実践配備を予定して開発が進んでいるものです。また一方のAzure Cobaltは、Azure上の汎用コンピューティングタスクを処理するために最適化されたARMアーキテクチャによるRISCプロセッサです。
マイクロソフトがAIに関する半導体チップを開発するのは、今回が初めてではありません。2018年には、Project Brainwaveと呼ばれる深層学習用の推論用アクセラレーションチップをFPGA(Field-Programmable Gate Array)ベースで開発していたことが公表されています。尚、このProject Brainwaveの開発成果がAzureのサービスに組み込まれているか否かについての正式な発表は見当たりませんが、Azure Machine Learningという機械学習のためのサービスとの統合やBingのインテリジェント検索に利用されている可能性があります。
(1)MAIAについて
MAIA 100は、マイクロソフトがAzure上での大規模な言語モデルの学習と推論を行うために設計したのASICで、シリーズの第1世代となるAIアクセラレーターとなります。5nmプロセス技術開発されるこのアクセラレーターは、1,050億のトランジスタを搭載し、大規模なAIモデルに対応できるように64GBのHBM2Eメモリを搭載して、このクラスで最大クラスのAIアクセラレーターになっています。高いエネルギー効率によって電力コストを削減。MAIAを複数組み合わせることでスケールアウトが可能となり、AIや生成AIの大規模タスクを高速処理できる設計になっているようです。尚、MAIA 100の次となる第2世代バージョンの設計が進んでいるそうです。
2024年に実戦配備される予定のMAIAは、既にサービス提供されているAzure OpenAIサービスやMicrosoft CopilotなどのAIタスクの処理に利用されるとされ、更に将来的には、AzureのコンピュートインスタンスとしてNVIDIAのGPUインスタンスと横並びして、主に企業のAIアプリケーションの開発者向けサービスとして提供が予定されています。

(2)OpenAIとのパートナーシップ
MAIAはOpenAI社との広範な協力によって開発されています。Microsoft CopilotやAzure OpenAIサービスなどのマイクロソフトが提供するAIサービスは、OpenAI社によって開発されたGPT 3.5 TurboやGPT-4といった大規模言語モデルに支えられています。これらの最先端のモデルをさらに高精度かつ洗練されたものにするためのモデル学習は、前例のない規模となり、経済合理性とのバランスを取りながらのモデルの高速学習には、コンピューティングを支える基盤にもイノベーションが必要になります。
OpenAI社のCEOであるサム・アルトマンは次のように述べています。
「マイクロソフトと我々OpenAIは、OpenAIのモデルや訓練ニーズに合わせて、AzureのAIインフラストラクチャーのあらゆるレイヤーで共同設計を行い、モデルの改良とテストを連携して進めてきました。AzureのエンドツーエンドのAIアーキテクチャは、シリコンチップを含むすべてが最適化され、より高性能なモデルの学習を可能にし、OpenAIの顧客に対してよりコスト効率の高いサービス提供の道を開いています。」
このコメントからは、マイクロソフトの取り組みが、単にAIアクセラレーターという半導体を自社で開発するという個別プロジェクトの枠にとどまるものではなく、AIを支えるインフラストラクチャー、すなわちエンドツーエンドのAIアーキテクチャの再定義と再構成を目指していることが伺えます。
結果として、マイクロソフトが進める全体アーキテクチャの変革は、Azureを基盤とするOpenAIを含むAIサービスプロバイダーや一般企業の顧客、さらにはOpenAIのChatGPTやマイクロソフトのCopilotなどのAIアプリケーションを使用する個人ユーザーに対し、より魅力的なサービスを提供することにつながります。このことは、他のハイパースケーラーやAIサービスプロバイダーとの競争におけるマイクロソフトの競争力の源泉に直接つながる重要な活動であると考えられます。
(3)Azure Cobalt
Igniteで発表されたもう一つの半導体が「Azure Cobalt」です。Cobaltは、AIタスクではなく、汎用アプリケーションタスクのために開発された省電力プロセッサです。本記事のテーマであるAIアクセラレーターではありませんが、AIサービスに最適化されたインフラストラクチャーを構成する重要なパーツであることから簡単に紹介します。
今回発表された初代のCobalt 100は、ARMアーキテクチャを採用してAzure向けに開発したクラウドネイティブなプロセッサで、開発目標に同社の長期の重要課題である「ワットあたりのパフォーマンスの最適化」を掲げて開発した非常にエネルギー効率とコスト効率に優れたプロセッサになっています。この128コアを有する64ビットプロセッサは、現在、Microsoft TeamsやAzure SQLなどのサービスで汎用タスクを処理し、サービスの向上に貢献しています。また既に、第2世代Cobaltの開発も進行中であり、将来的にはAzureや同社の幅広いサービスにおける高速処理と低消費電力での運用が期待されています。

(4)AIインフラの再定義と再構成
2016年以前、マイクロソフトは、データセンターを構成するほとんどの機器は、サードパーティ・メーカーが販売している既製品を購入して利用していましたが、それ以降、マイクロソフトは、自社でカスタムメイドしたサーバーやラック、ネットワーク機器を使いデータセンターの環境を整備するようになりました。 結果として、システムの調達・構築・運用において自社のグリップが効くようになり、コスト削減も進んで顧客に対して、より品質の高いリーズナブルなサービス体験を提供できるように進化してきました。
但し、最後のミッシングパーツが半導体部分で、マイクロソフトの要件に沿ったインフラストラクチャーをエンドツーエンドで構成するために、この最後のパズルのピースを埋める必要があったとのことです。
そのような背景の中、実際に発表されたMAIA 100は、単にスタンドアロンのASICという存在ではなく、データセンターのエコシステムにしっかりと組み込まれることを前提に設計されており、ソフトウェア、ネットワーク、サーバーラック、電源システムや冷却システム等の周辺エコシステムとタイトに連携して機能するよう最適化されています。
マイクロソフトのクラウド+AIグループのEVPであるスコット・ガスリー氏やAHSI(Azure Hardware Systems and Infrastructure)部門のコーポレートバイスプレジデントであるラニ・ボルカー氏は共に、MAIAやAIインフラストラクチャーについての以下のように要旨を語っています。
現在、Azureデータセンターでは、主にNVIDIAのGPUが採用されているが、インフラストラクチャースタックの全ての層を最適化して統合することが重要であると考えており、MAIA 100は、その考えにしたがってAIワークロードとAzureを構成するハードウェアスタック専用に最適化設計されている。Azure上のワークロードを念頭に置いて設計された半導体チップと大規模なAIインフラシステムの垂直統合は、パフォーマンスと効率性において大きな利益をもたらすことができる。マイクロソフトは、半導体からシステムまで、クラウドインフラストラクチャーを再定義し、すべてのビジネス、すべてのアプリケーション、すべての人のためのAIに備えて行く。
補足として、マイクロソフトが進めるAIインフラストラクチャーの再定義と再構成について、MAIAやCobaltとともに発表されている幾つかの取組みを以下に紹介します。
① サーバーラックの開発
マイクロソフトは、MAIA 100を搭載するサーバーを収納するサーバーラックも新たに自社開発しています。安定した電力を提供する大量の電源ケーブルやネットワークケーブルを収容するためのスペースの確保に加え、膨大な計算処理を行うAIアクセラレーターが発生させる熱は、システムのパフォーマンスやサービス持続性にも影響を与える大きな課題となります。そのため空冷方式ではなく、冷媒を利用した冷却システムを使い、MAIA 100の表面に装着されたコールドプレートにある溝を通して冷媒を循環させて熱を吸収・搬送する冷却装置を開発しています。これによりシステムの効率的な温度管理を実現し、エネルギー効率を高めながらAIアクセラレーターの性能を最大限に引き出すためのエコシステムシステムを開発しています。

(出典:マイクロソフト)

(出典:マイクロソフト)
② Azure Boost
Azure Boostは、マイクロソフトが開発した専用のSoC(System on Chip)を搭載したMANA(Microsoft Azure Network Adapter)と共に実現する仮想マシンのストレージとネットワークのタスクを外部処理する仕組みを提供します。これは、従来ハイパーバイザーとホストOSが担っていたサーバー仮想化処理の部分をホストサーバーからAzure Boost(専用のハードウェアとソフトウェア)へ移行させて負荷分散し、ストレージとネットワーキングのパフォーマンスを高速化させるというシステムです。このAzure Boostを導入することで、最大200Gbpsのネットワークスループットを実現し、ローカルストレージでは3800K IOPsのスループット、リモートストレージでは、650K IOPsのスループットを実現可能で、データ集約的なワークロードを効率的に処理することが可能としています。
また、Azure Boostは、優れたメンテナンス性とセキュリティの強化をもたらします。メンテナンス性については、ハードウェアとソフトウェアの両方を包含するメンテナンス機能を持ち、システムに搭載されている各コンポーネントの更新をシステムのスループットに大きな影響を与えることなく実施することができるとしています。例えば、ネットワークコンポーネントの更新による影響は1秒未満、システムレベルの更新による影響は3秒未満とし、メンテナンス時でもシステムのダウンタイムとシステムへの影響を最小化することができます。セキュリティについては、独立したハードウェアのルートオブトラスト(Cerberus)、Azure Boost SoC、FPGAなどによる最新のセキュリティ技術を採用し、ネットワークと仮想マシン、そしてワークロードのセキュリティの完全性を保証することが可能としています。

(出典:マイクロソフト)
(5)NVIDIAやAMDとの関係
上記に説明した通り、マイクロソフトがAIアクセラレーターやRISCプロセッサを自社開発しているのは、単にGPUのサプライチェーン課題の緩和策であるとか、NVIDIAのGPUを自社製品で全て置き換えようとしている訳ではなく、次世代のAIシステムを見据えたデータセンターのアーキテクチャの再定義が根底のモチベーションになっています。 よってマイクロソフトは、既存の半導体メーカーとのパートナーシップについても、引き続き協力関係を築いていくことを発表しています。
① NVIDIA
マイクロソフトは既に、NVIDIA H100をベースとする新たな仮想マシンとして「ND H100 v5」「NCads H100 v5」のサービス提供が開始されています。この仮想マシンは、主に中規模のAIモデルの学習と生成AIの推論を目的として高いパフォーマンスと信頼性を発揮するサービスになっています。 また2024年には、最新のNVIDIAの最新GPUとなる「H200」を導入した仮想マシンを追加し、より大規模なモデルの推論を可能とする更に高パフォーマンスなサービスを提供する予定です。
② AMD
マイクロソフトは、AMDの新GPUであるMI300Xを搭載するAI用に最適化した仮想マシン「ND MI300」のサービスを2024年初頭から提供します。
このサービスは、従来のNVIDIAのGPUによって構成されていたサービスラインナップを拡張し、ユーザーに新たな価格やパフォーマンスの選択肢を提供するものとなります。この新たな仮想マシンにより、AIモデルの学習や推論の要件に対し、更に幅広い選択肢を提供することができます。
2. メタ プラットフォームズ 「MTIA」
Meta Platform(以降、メタとする)は、2023年5月にMeta MTIA(Meta Machine Translation and Intelligence Accelerator)というAIアクセラレーターの開発を発表しています。 Oclus QuestやRay-Banグラスなどのハードウェアも開発・販売するメタですが、データセンターを構成するサーバーやネットワーク、ストレージなど、ハードウェアおよびソフトウェアの技術標準化について業界を通じて多大な貢献をしていることは、意外と知られていないかもしれません。
(1)メタとハードウェアシステム開発
メタ(当時Facebook)が2011年に発起人として立ち上げた業界横断プロジェクト「Open Compute Project」(OCP)は、データセンターのハードウェア設計をオープンソース化し、より効率的でスケーラブル、そしてより環境に優しいものにすることを目指したデータセンターを構成する、サーバーやストレージ、ネットワークやファシリティの設計情報や技術情報などの知財をメンバーが共有し、コスト削減や開発や製造の効率化を業界全体で促進するためのプロジェクトとなっています。そして、OCPの創設メンバーであるメタは、オープンソースのデータセンター設計や技術の推進者として中心的な役割を果たしています。
OCPの活動には、テクノロジー業界の大手企業からスタートアップ、個人に至るまで幅広いメンバーが参加しており、ハードウェアやソフトウェアの設計情報の共有やベストプラクティスの共有を通じて、業界を通じたイノベーションの促進に取り組んでいます。主なコントリビュータとして、マイクロソフト、Google、IBM、インテル、ブロードコム、Rackspace、DELL/EMC、HPEなどが参加しており、これら企業の間で、サーバーやストレージ、ネットワーキング、冷却装置、セキュリティ、データセンターファシリティの分野で各社が強力しながら、技術開発進められています。NVIDIAとAMDもOCPのメンバーであり、NVIDIAは特にGPUに関する技術情報、AMDからは高性能CPUに関する技術情報が共有され、AIや深層学習、高性能コンピューティング(HPC)分野での業界全体のイノベーションを底上げしています。

(2)Meta MTIA
さて、2023年5月にその開発が発表されたAIアクセラレーターの「Meta MTIA」(以下、MTIAとする)について紹介して行きます。未だ開発中の半導体であり、情報も限定されている状況ですが、公表されている情報をベースに紹介をして行こうと思います。
MTIAは、同社のサービスであるFacebookやInstagramなどで使用されるAIタスクを大幅に高速化するためにカスタム設計されたASICで、従来のCPUやGPUに比較して処理速度の向上と高い電力効率を実現します。 また、メタが開発した機械学習及び深層学習のフレームワークであるPyTorchに最適化されており、メタが提供しているFacebook、Instagram、WhatsApp、Meta Quest、Horizon Worlds、Ray-Ban Storiesなどのサービスで利用されている深層学習ベースのレコメンデーションモデルに最適化されて設計されている模様で、これらサービスの精度や品質の向上、運用コスト削減に直接貢献することが期待されています。
尚、現在開発中のMTIAですが、TSMCの7nmプロセス技術で、熱設計電力(TDP)は25W。64個のプロセッサを配置し、隣接して128MBのSRAMを置き、64GB のDRAMをオフチップ配置します。その演算処理性能は、FP16による学習タスクで51.2テラFLOPS、INT8による推論タスクで102.4TOPSを達成するとのことです。またメタが実施した深層学習モデルでの推論性能テストでは、NVIDIAのGPUと比較し、複雑ではないAIモデルでは、電力消費当たりの浮動小数点演算処理において約3倍の性能を実現した模様ながら、複雑なAIモデルの場合には、性能が約半分になるとことで、メタでは引き続いてソフトウェアの最適化と性能改善を進めて行くとしています。尚、このMTIA、学習タスクと推論タスクを処理可能ですが、主に推論タスクに重心を置いて開発されているとのことです。

(出典:The Next Platform)
(3)第二世代「Artemis」
メタからは、前述のMTIAに加え、第2世代のAIアクセラレーターとしてのカスタムASICの開発が既に進められていることが発表されています。 この「Artemis」と呼ばれる推論タスクに特化したASICは、2024年後半から量産を開始する計画とのことです。メタが数十万個規模で購入するNVIDIA製のGPUと組み合わせて動作させることで、メタのサービスに固有のワークロードに対して最適な性能と効率性を提供することが期待されています。
尚、このArtemisについての情報は、ロイターが入手したメタの社内文書に基づく情報ということで、メタからの公式のアナウンスではありませんのでご留意ください。
(4)DCアーキテクチャの再定義
今後も加速度的に高度化が進むであろうAIアプリケーションに必要な演算能力やエネルギー、インフラなどのリソースは増加して行くでしょう。 このことは、メタに限らず、ハイパースケーラー達にとって引き続いて莫大な投資が必要である、ということと同意です。メタに限ったとしても、地球の人口の40%、つまり30億人以上にサービスを提供しているメタのような事業規模を考慮すれば、自社に最適化された独自半導体の導入に成功すれば、GPU調達費やエネルギーコストのコスト削減は、数十億規模で削減できる可能性があります。そのことは、OCPの発起人であるメタが誰よりも理解しているロジックです。
この点、膨大なデータセンターリソースを運用してサービスを提供しているメタにとってもデータセンターのアーキテクチャやコンポーネントの再定義と再構成というのは、前述のマイクロソフトと同様に、メタにとっても命綱であり、カスタムASICの開発に留まらない取組みが必要と言えます。
2023年にメタが発表したデータセンターおよびAIアプリケーションを支えるテクノロジーについての新たな成果や取組について、ヘッドラインのみですが以下紹介したいと思います。
AI向けに最適化された次世代データセンターの設計、液体冷却ハードウェアやAIアクセラレーターの大規模クラスタリング技術の開発
FacebookやInstagram上の動画やライブストリーミングコンテンツの低遅延で高速処理を実現するASIC「Meta Scalable Video Processor(MSVP)」の開発
1万6000個の「A100」GPUを搭載した2000台の「DGX A100」システムから構成される世界最速レベルのスーパーコンピュータ「Research SuperCluster(RSC)」の開発
プログラムコーディングのための生成AIツール「Code Compose」の開発
次世代のオープンソース大規模言語モデル「Llama3」の開発
その他、たくさん。。。
3. Google(Alphabet) 「TPU」
2010年初頭に深層学習が勃興してから、AIの社会実装を牽引してきたGoogle(Alphabet)が着手したAIアクセラレーターがTensor Processing Unit (TPU)と呼ばれるASIC(特定用途向け集積回路)で、2016年に韓国の囲碁棋士 イ・セドルと戦って勝利したAlphaGoにも利用されていることでも良く知られています。このTPUは、2015年のリリースから世代を重ねて現在最新のTPU v5まで、同社のAI研究開発とAIサービス開発の進化に大きく貢献してきました。
既に同社のクラウドサービスであるGCP(Google Cloud Platform)に配備され、AIの学習と推論を安価で高速に実現するサービスとして多くの企業ユーザーなどに広く使われています。また、2023年12月にBardからGeminiに名称変更してリブランドされた生成AIサービスにおいても、モデルの学習と推論のタスクでこのTPUが利用されています。
(1)TPUについて
GoogleのTPU(Tensor Processing Unit)は、ニューラルネットワークのモデル学習や推論の大量かつ高速な計算処理に最適化されたエネルギー効率の高いカスタムASICです。
主な特長は、大容量のAIモデルを処理可能な大容量メモリを搭載し、CPU や GPU と比べて大幅に高い処理速度を実現していることです。 特に、大規模な行列計算を高速に処理できるよう最適化されており、深層学習で利用される「テンソル演算」を得意とし、機械学習モデルの学習と推論を高速化することができます。複数のTPUを組み合わせてシステム全体をスケールアウトさせることが可能で、従来のCPUやGPUに比べてエネルギー効率が高いため、システム全体の電力コストを抑えながらより多くの演算が可能となります。

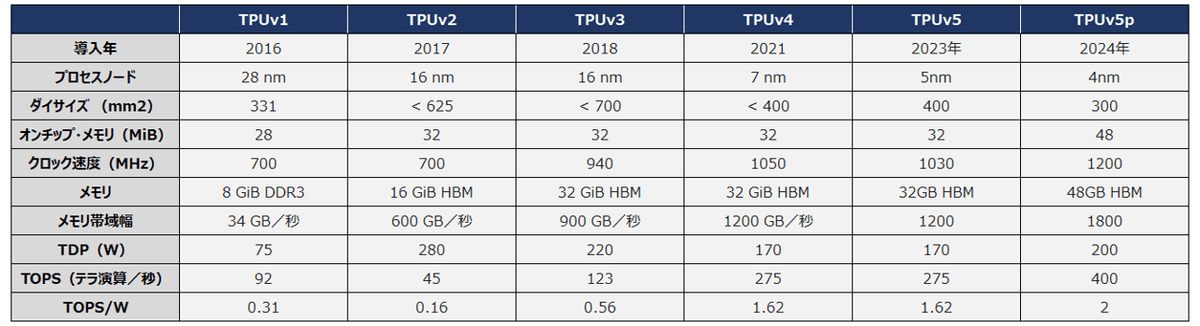
TPUの開発系譜を下図に示します。 最新のTPU v5pは、全バージョンのTPUv5に比べ、ポッドあたりのチップ数が8,960個から17,920個に倍増し、1秒あたりの演算数が393兆回から918兆回へと、約2.3倍の高速化が進んでいます。(※1秒あたりの演算数 = TOPS * 10^12)
(クリックして拡大)
TPUのユースケースとしては、物体検出、顔認識、画像分類などの画像系処理。音声翻訳、音声合成、音声認識などの音声処理。機械翻訳、テキスト要約、質問応答などの自然言語処理。 そして商品やコンテンツのレコメンデーションやネットワーク侵入検知やクレジットカード詐欺検知などを挙げることができます。
ユーザー企業は、GCPを通じてTPUを利用できるほか、モバイルデバイスやIoTデバイスなどに搭載してAIタスクを実行できる軽量化されたEdge TPUもCoralというブランドでリリースされています。
(2)AI Hypercomputer
Google Cloudは、2023年12月のTPU v5p発表時に、AIタスクに最適化された統合コンピューティングシステム「AI Hypercomputer」という新たなアーキテクチャを発表しています。これは、AIのワークロードに最適化されたコンピューティング、ストレージ、ネットワークを基盤として、コンテナオーケストレーションレイヤや機械学習フレームワークなどのオープンソースを最適化して統合したもので、Google Cloudの定義する様々なAI活用ニーズに対応するリファレンスアーキテクチャになります。
AI Hypercomputerは、AIの処理能力を最大限に引き出すために最適化されたコンピューティングアーキテクチャで、限られた物理スペース内に高密度にコンピュータリソースを集約して大量の計算リソースを提供することができます。膨大な演算によって発生する熱の処理は液体冷却システムが行い、システムを安定稼働します。また、エネルギー効率や再生可能エネルギーの利用について配慮がなされ、環境への影響を最小限に抑えて、持続可能な方法で高性能な演算処理サービスを提供することができるとしています。
AI Hypercomputerは、TensorFlowやPyTorch、JAXなどのオープンソフトウェアの機械学習フレームワークとライブラリをサポートし、AIモデルの学習と推論のパフォーマンスを最適化し、開発者に効率的で柔軟なAIモデルの開発環境と実行環境を提供します。また、マルチスライス学習とマルチホスト推論のソフトウェアによってAIワークロードのスケーリング、トレーニング、サービングを簡単に管理でき、Google Kubernetes Engine(GKE)とGoogle Compute Engineの統合により、効率的なリソース管理と運用の自動化を実現します。

4. AWS 「Inferentia & Trainium」
AWSは、AIアクセラレーターの内製化に早い時期から積極的に取り組んでいます。2015年にアマゾンが買収したイスラエルのAnnapurna Labs社を通じて開発したAIの学習と推論に特化した2つのASIC、「Inferentia」(インフェレンシア)と「Trainium」(トレイニウム)を既に同社のクラウドサービスであるEC2で実践配備しています。推論用のInferentiaは2019年、学習用のTrainiumは、2021年のリリースです。 また、この子会社のAnnapurna Labs社は、セキュリティチップの「Nitro」とARMベースの汎用CPUの「Graviton」を開発しており、共にAWSのサービスとして既に実践配備されています。

(1)Inferentia の概要
Inferentiaは、EC2インスタンスに特化したAIアクセラレーターであり、EC2のInf1もしくは、Inf2インスタンスとして利用することができます。画像認識や音声認識、自然言語処理などの深層学習の推論タスクに最適化され、高スループットで低遅延という特徴を持ちます。推論速度は、従来のCPUやGPUに比べて大幅向上しており、省電力性能も高く、更に調達コストも低いことから、TCO(トータルコストオーナーシップ)を大幅に削減することができます。また複数のインスタンスを組み合わせて最大2.3 PFLOP(ペタフロップス)、最大384GBの共有アクセラレーターメモリ、総メモリ帯域幅が9.8 TB/sと、かなりの大規模な推論ワークロードに対応可能なよう構成することが可能です。
EC2インスタンスには、Inf1とInf2のインスタンスが用意されており、Inf1は最大4つの初代Inferentiaを搭載。また、Inf2は最大8つの第二世代のInferentia2を搭載します。最大4倍のスループットと最大10倍の低レイテンシーを実現するInf2インスタンスでは、深層学習タスクの他、大規模言語モデル(LLM)や拡散モデル(Diffusion Model)、ビジョントランスフォーマー(VT)などの生成AI系モデルも十分にカバーでき、AWSのEC2サービスの中で最も低コストで高パフォーマンスを発揮するサービスであるとされています。 Runway や Leonardo.ai など、名の知れた生成AIサービス企業でも利用されています。
(2)Trainium の概要
Trainiumは、AWSがAIモデルの学習用に独自設計したカスタムASICで、大量の学習データでAIモデルを高速かつコスト効率高く学習させることができるAIアクセラレーターです。 最大数兆のパラメータ(数トリリオン!)を持つ大規模言語モデル(LLM)や基盤モデル(Foundation Model)を高速に学習できるようです。
2023年11月に発表された最新版の第2世代Trainium2は、第1世代のTrainiumと比較し、メモリ容量3倍となる96GBのHBMを搭載し、学習速度が最大で4倍高速になるよう設計がなされています。最大10万個のクラスター化が可能で、最大2倍のエネルギー効率を実現し、スーパーコンピューター級の最大65エクサフロップスの計算処理性能をオンデマンドで提供することができるとしています。 最近の大規模言語モデルや基盤モデルは、パラメータ数が数兆におよぶものもあり、学習データもテキストだけではなく、画像や動画、オーディオやプログラムコードなど多岐に渡っており、モデル学習時のコンピューティングリソースにかかる負荷は想像を超えています。そのような巨大スケールの学習が必要な場合でも、Trainium2を利用すれば、数ヶ月かかっていた3,000億パラメータの大規模言語モデルの学習も数週間で実現できるとしています。尚、Trainiumのユースケースとには、画像生成や音声合成などの巨大な生成AI系モデルや医療画像診断や創薬、金融市場予測やリスク分析などが挙げられています。
(3)Neuronの概要
Neuron(ニュートロン)は、InferentiaとTrainiumのインスタンス上で深層学習タスクを実行するためのソフトウェア開発ツールです。
AWS Neuronは、TensorFlow、PyTorch、MXNetをサポートし、コンパイラ、ランタイム、その他のツールを提供し、機械学習モデルの構築から学習、最適化、本番環境での実装と運用に至るまで、AIの開発ライフサイクルを支援する環境を提供しています。
下図は、Neuronを使用したAIモデルの開発と本番環境実装までのAIモデルのライフサイクルイメージです。 左から(1)機械学習フレームワークの選択、(2)Jupyter Notebookを使用してモデル構築、(3)モデルの学習、(4)繰り返し反復してのモデルのテストと評価、(5)モデル利用する環境への実装、というごくごく一般的な流れとなりますが、AWS上の他のサービスやインスタンスと透過的かつ疎結合できる点で、Neuron を利用することで、AWS上のAIモデルの開発と実装の作業効率を大幅に引き上げることができます。

(クリックして拡大)
(4)NVIDIAとのパートナーシップ
AWSは従来から、NVIDIAのGPUを使ったクラウドサービスを広く提供しています。もちろん両社のパートナーシップは良好です(と思います)。2023年11月にAWSが発表されたNVIDIAとの戦略提携内容は以下の通りです。
NVIDIA Grace Hopper Superchipを搭載するクラウド型のAIスーパーコンピューターをAWSが提供します。
NVIDIA GH200 NVL32を搭載するNVIDIA DGX CloudをAWSがクラウドサービスで提供します。
両社が強力してAIの研究開発とカスタムモデル開発を行い世界最速のAIスーパーコンピューターを実現します。
Amazon EC2に、NVIDIA GH200、H200、L40S、L4 GPUの新たなインスタンスを追加します。
AWSにNVIDIAのソフトウェア開発フレームワークを実装します。
5. IBM 「Hermes」
Watsonという人工知能のブランドで有名なIBMですが、ここにIBMが名を連ねることに違和感を覚える方もいるかと思います。IBMは長年に渡って半導体の設計と製造の分野で多くの研究実績と製品を生み出して来た企業です。現在でもPower と呼ばれるRISCプロセッサの開発製造を行い、主に自社製品に搭載するなど、半導体分野の最前線で活動を行っている企業です。最近では、IBMが開発した2nm半導体製造技術を基にしたRapidus社(千代田区)との共同開発パートナーシップは、日本政府が推進する日の丸半導体復権に向けた1つのマイルストーンとして良く知られたプロジェクトとなっています。
(1)AIアクセラレーター開発の先駆者
さて、そのIBMですが、深層学習のAIアプリケーションが広く世間に拡がり始めた2014年に、「TrueNorth」と呼ばれる脳のニューロンを模倣したニューロモーフィックチップの開発を発表しました。このニューロモーフィックチップというアーキテクチャは、極めてエネルギー効率が高く、特定のAIタスクにおいて従来の演算チップよりも高速に動作する可能性があるとして長年に渡ってIBMのみならず、少なくない企業で研究が続けられている技術になります。
GPUは複数のコアを利用して大量データを高速に並列処理することができるため、深層学習で必要な繰り返し処理がとても得意なのですが、ニューロモーフィックチップは、ニューロンとシナプスのネットワークを使用し、脳の仕組みのようにデータを処理することでエネルギー効率と処理速度の向上を図ることができ、それゆえに、低消費電力でリアルタイムの処理の求められるパターン認識やセンサーデータの解析などで優れた性能を発揮できるとしています。
(2)アナログ インメモリ チップ
2023年8月にIBM研究所が発表したのが、演算精度を維持しつつ、電力消費の多い深層学習のエネルギー効率を飛躍的に高める全く新しいアナログ インメモリ チップ(Analog In-memory chip)です。この「Hermes」と名付けられたチップは、デジタル回路と相変化メモリ(PCM)を融合させ、ニューラルネットワークの計算をメモリ回路内で行えるようにしています。これにより、メモリと演算回路の間でデータのやり取りをする必要がなくなることから、消費電力を大幅に抑えて、コンピュータビジョンなどのAIタスクで、GPUなどのデジタル処理のチップと同等の性能を達成することができるとしています。
CPUやGPUが抱えるAIタスクを処理する際の電力消費に関する課題の根底には、「フォン・ノイマンのボトルネック」と呼ばれる現象があります。この現象は、そもそも演算回路とメモリが別個に存在し、処理過程で演算回路とメモリの間をデータが絶えず行き来する必要があることからエネルギー消費が増えてしまう、というコンピューティングのアーキテクチャそのものが原因となって発生している問題となります。そしてこの課題に対し、これまでの設計者たちは、メモリ・キャッシングやパイプライン、階層型メモリなどの様々な施策によってこのボトルネックと戦ってきましたが、IBM研究所の開発したこのアナログ・インメモリ・コンピューティングでは、メモリ内部で直接演算することができるため、フォン・ノイマンのボトルネックを回避してエネルギー効率を大きく高めながら、従来の演算回路と同等のパフォーマンスを達成することができたとしています。
尚、IBM研究所は、この「Hermes」は、まだ研究段階にあるとして、今後は、よりシナプス密度を高めた大型チップを製造し、エネルギー効率と精度の高い推論をエンドツーエンドで実現可能な、GPUを超える性能を持つアナログ インメモリ チップの実現を目指して研究を進めるとしています。

(出典:IBM)
(3)市場の細分化を表現するIBM
IBMは、今回のシリーズ記事で取り組みを紹介している大手半導体メーカーやクラウドプラットフォーマーとは少々異なる独自な路線を進んでいるイメージのある企業です。(あくまでも私見ですが)
IBMは、前述のように半導体分野での研究開発や設計を今でも積極的に行っていますが、2015年に半導体製造部門をグローバルファウンドリーズとしてスピンアウトし、IBMの技術やノウハウを移管して以来は、半導体そのものの製造を自社では行っていません。現在は、特にローエンドの半導体の世界からほぼ手を引いており、半導体技術の特に先端技術の研究開発には積極的で、開発した特許や技術を外部の半導体メーカーや製造パートナーにライセンスしています。しかしながら、現在のIBMの主要事業がクラウド、AI、コンサルティングサービスなど、特にバーティカルなB2Bビジネスに軸足があることから、半導体関連の収益は全体の売上の小さな部分を占めるに過ぎないと考えられます。そのため、IBMが開発した技術による半導体が市場を席捲する可能性は低いと思われるものの、AIアクセラレーターなどの特定市場セグメントにおける研究開発や技術革新の面では、依然として業界の中で重要な役割を果たしています。
御礼
最後までお読み頂きまして誠に有難うございます。
今回は、主要なハイパースケーラーたちのAIアクセラレーター事情を紹介しましたが、さらに細分化の進む市場動向について非上場企業の取組みも含めて続々編となる記事掲載を予定しています。
ご興味ありましたら、ぜひともフォローをお願いいたします。
今後ともどうぞよろしくお願いいたします。
だうじょん
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?