

#LoRa


Qwen2-VL-7B-InstructのLoRA
OCRなどで高性能と話題のQwen2-VL-7B-InstructをLoRAしたのでまとめました。
LoRAにはこのライブラリを用います。
環境としてDockerを用いました。
自分が使ったコマンドは以下です。
docker run -it --gpus all -v $(pwd):/mnt/workspace registry.cn-hangzhou.aliyuncs.com/models

LLama2の訓練可能な全層をQLoRAで学習する
はじめにLLama2はMetaが23年7月に公開した、GPT-3に匹敵するレベルのオープンソース大規模言語モデル(LLM)です。
最近はFalcon 180bのような、より大きなモデルも出ていますが、デファクトスタンダードとして定着している感があります
LLMに新たな情報を加える手法として、ファインチューニング、特にQLoRAが注目されています。
しかしQLoRA、特に初期設定では一部のパラ

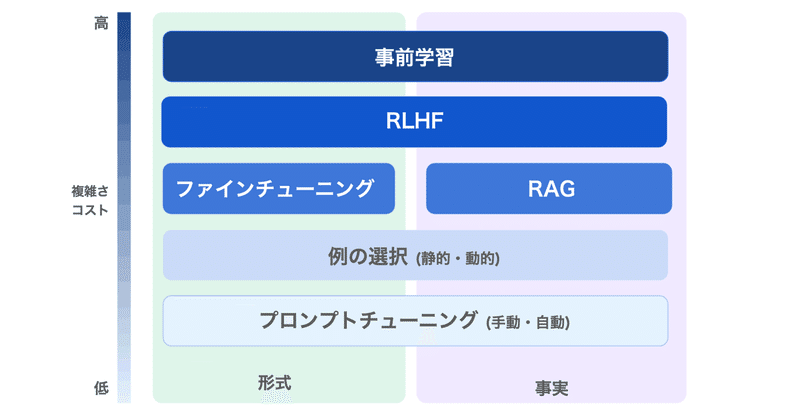
LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


LLM の LoRA / RLHF によるファインチューニング用のツールキットまとめ
「LLM」の「LoRA」「RLHF」によるファインチューニング用のツールキットをまとめました。
1. PEFT「PEFT」は、モデルの全体のファインチューニングなしに、事前学習済みの言語モデルをさまざまな下流タスクに適応させることができるパッケージです。
現在サポートしている手法は、次の4つです。
◎ LLaMA + LoRA
「Alpaca-LoRA」は、「LLaMA」に「LoRA」を適用


GPT/LLMモデルの進化!追加の知識を組み込む最新テクニック
OpenAIの範囲外の話題でも、オープンソースコミュニティの作業を見ることができます。LLMに知識を追加するには、fine-tuningを使用することができます。OpenAIはfine-tune APIを提供していますが、LLM関連のオープンソースコミュニティの作業に少し調査レポートしました。関連情報を共有します。
fine-tuning以外のオプションStanfordのLLaMAに基づくAlp


手元で動く軽量の大規模言語モデルを日本語でファインチューニングしてみました(Alpaca-LoRA)
イントロ最近、ChatGPTやGPT-4などの大規模言語モデル(LLM)が急速に注目を集めています。要約タスクや質疑応答タスクなど様々なタスクで高い性能を発揮しています。これらのモデルはビジネス分野での応用が非常に期待されており、GoogleやMicrosoftが自社サービスとの連携を進めているという報道も相次いでいます。
今回は、手元で動作する軽量な大規模言語モデル「Alpaca-LoRA」を