

#人工知能


Google Colab で SSD-1B を試す
「Google Colab」で「SSD-1B」を試したので、まとめました。
1. SSD-1B「SSD-1B」(Segmind Stable Diffusion Model) は、「SDXL」(Stable Diffusion XL) を50% 小型化したバージョンで、高品質のテキストから画像への生成機能を維持しながら60% の高速化を実現します。
2. Colabでの実行Colabでの実行手
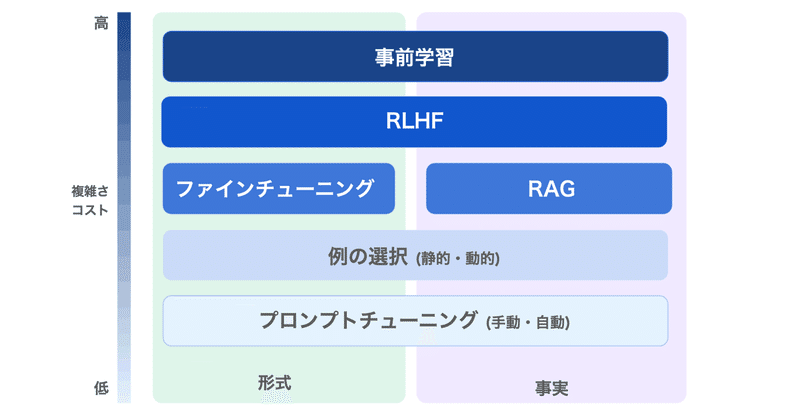
LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動


人工知能による自然言語処理(日本語の言語モデル開発の現状)
海外では、2020年5月に、1,750億のパラメーターを持つOpenAIのGPT-3が登場して以来、1,000億以上のパラメーターを持つ巨大言語モデルが続々と誕生しています。
巨大言語モデルとは、大規模なテキストデータを事前学習することによって、わずか数例のサンプルを示しただけで、機械翻訳、文章生成、質問対応など様々な言語処理タスクに対応することができる言語モデルのことです。
一方、日本では



Rinna 3.6B の量子化とメモリ消費量
「Google Colabでの「Rinna 3.6B」の量子化とメモリ消費量を調べてみました。
1. 量子化とメモリ消費量「量子化」は、LLMのメモリ消費量を削減するための手法の1つです。通常、メモリ使用量が削減のトレードオフとして、LLMの精度が低下します。
AutoTokenizer.from_pretrained()の以下のパラメータを調整します。
2. Colabでの確認Colabで