
学習まとめ「社会人のためのデータサイエンス入門」→データはある、仮説を立てろ

「社会人のためのデータサイエンス入門」総務省統計局
※講義期間は終了しています。
一言で言うと
データはある、仮説を立てろ
概要
「社会人のためのデータサイエンス入門」、無事に最終課題までやり遂げました。なんとか修了証がもらえる成績で終えられて一安心です。
思いつきで受講登録だけして放置してましたが、そのあとPower Platformを有効活用するにはデータの知識が必須、と感じて講義を猛追しました。PL-200資格の学習からちょうどいいタイミングでスイッチできたのが幸運でした。
本講座からの一番の学びは、仮説を立てる力の重要性です。公的統計として膨大なデータがあり、データを表現するモデルも色々なものが考案されています。しかし、それを活かして有益・斬新なメッセージを作るのは簡単ではありません。どの時期のどんなデータを組み合わせるのか、仮説を立て、それに基づいて検証することが重要になると感じました。
本稿では、本講座の学びのトピックを3つ紹介します。
① グラフを正しく作る・読む
グラフは、視える化して表現する・伝えるために有効なツールです。考え方は図解と共通していて、私がnoteに公開している図解にも、模式図的に折れ線グラフや棒グラフを使うことがあります。グラフの正しい使い方を理解して、グラフと図解で相乗効果を出したいと思いました。
グラフの描き方次第では、実際より誇張して見せることもできてしまいます。グラフの作り手としてだけでなく、特に読み手として気をつけたいところですね。単位の取り方や3Dグラフの利用など、作り手が恣意的な表現をしていないか、注意が必要です。本講座では、「詐欺グラフ」で検索すると実例がたくさん出てくる、と紹介されていました。事例を見て学習することで、詐欺グラフへの免疫力を高めるのもよさそうです。
② 偏差・分散・標準偏差の復習
数学の授業で習った概念を、再学習して多少理解できました。シグマが出てきた途端、文系の自分には拒否反応が表れるので、言葉で理解して乗り切りました。VBAやPythonでプログラミング脳が鍛えられたことも、理解の助けになったかもしれません。i = 1から開始してi = nになるまで繰り返す、ってプログラムがシグマってことですね。
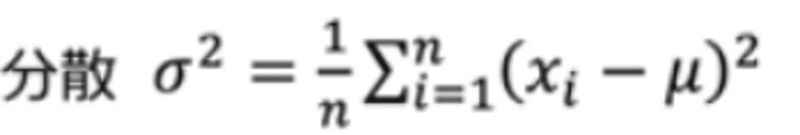
Excelにも偏差・分散を扱う関数が用意されています。Power BIを使って分析するのが本線ではありますが、Excelの関数も使えるようにしておきたいと思います。
VAR.P(配列):配列の分散
STDEV.P(配列):配列の標準偏差
分散とは少しズレますが、相関係数のCORREL関数でドル円レートと保有株式の損益の相関とか見たらおもしろいかも。
CORREL(配列1,配列2):二つの配列の相関係数
③ 統計データはe-STATから
日本の統計データは、e-STATからアクセスできます。お役所仕事のデータなんて使いにくいんじゃない?と身構えてしまう人もいるかもしれませんが、個人的にはとても使いやすかったです。よく使われるグラフがダッシュボードに表示してあったり、データをダウンロードせずにひととおりのフィルター・グラフ化ができたりと、統計を活用してもらうための工夫を感じました。
ただし、統計の前提情報には注意が必要です。似たようなデータでも、期間(4〜翌3月、10〜翌9月など)や対象(単身世帯を含む/含まない)が異なる場合があります。前提情報を確認して、データを正しく使えるようになりましょう。
補足
「社会人のためのデータサイエンス演習」が10月に開講します。入門編よりも実践的な内容で、Excelや統計解析ソフトRで実際に演習する講義も入っているようです。お楽しみに!
#最近の学び #データ #データサイエンス #データサイエンティスト #学習 #講義 #講座 #統計 #統計局 #詐欺グラフ #数学 #e -STAT #グラフ
いつも図書館で本を借りているので、たまには本屋で新刊を買ってインプット・アウトプットします。