

#AI初心者


Negative Prompt を入れるタイミングについて
こんにちはこんばんは、teftef です。久しぶりに書きます。
今回は Negative Prompt が画像生成時に与える影響についてです。
簡単に内容だけネタバレすると、Diffuseion モデルの推論では Negative Prompt は 1 step 目からかけるより、 n >1 step 目からかけたほうがいいんでね。という趣旨です。
私もまだ初学者であり、説明が間違っていたり勘

超解像について (その3・Real-ESRGAN)
こんにちはこんばんは、teftef です。超解像その 2 の続きです。CNN を使った超解像が主流となる中で、GAN を使った超解像によって画像の高周波成分の復元が高品質にできるようになり、画像がぼやけることがなくなりました。しかし、SRGAN も ESRGAN も学習に使ったデータセットの質の問題が考慮されていませんでした。今回は学習する画像の質にバリエーションを増やし、汎化性能を上げた Re
もっとみる
AI を自分好みに調整できる、追加学習まとめ (その1 : 概要)
こんにちは、こんばんは teftef です。今回は最近流行りの「追加学習」について書いていこうと思います。今回の記事は追加学習の大まかな解説とどのような手法があるのかについてまとめていきます。私もまだつい最近まで初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
モデルの作成
AI (人工知能) を作るため

AI を自分好みに調整できる、追加学習まとめ ( その3 : DreamBooth )
こんにちはこんばんは、teftef です。今回も追加学習手法についてです。今回は DreamBooth、前回の記事の Textual Inversion に似ていますが、これはこれでまた一味違った手法になっています。Textual Inversion との違いを比べつつ、書いていこうと思います。私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください
もっとみる
ComfyUI で動かす Stable Diffsion XL
こんにちはこんばんは、teftef です。今回は話題の Stable Diffusion XL についてです。と、言っても使い方の記事は調べればいくらでも出てくると思うので、主は依然として論文解説をします。使い方を見に来たという方々にとってはその目的にに沿わないと思うので、主が特に分かりやすいと思った記事を下に張っておきます。今回は SDXL が条件付けとして画像のサイズを使用していることについ
もっとみる
GlyphControl: 文字を描く ControlNet
こんにちはこんばんは、teftef です。今回は GlyphControl です。DeepFloyd IF は Imagen をベースにしたカスケード式モデルであり、Text Encoder に大規模自然言語モデル(LLM)に使われる T5 モデルを使用していて文字が出力できる Generative AI として大きな話題となりました。しかし T5 モデルは非常に大きなモデルでありパラメータ数が
もっとみる
自律型マインクラフター (Minecraft played by AI)
こんにちはこんばんは、teftef です。今回は AI がマインクラフト (Minecraft) をプレイするということに関してです。OpenAI が開発した Video PreTraining (VPT) 、強化学習を使用した MINEDOJO、GPT-4 を使用した Voyager という最新手法などを3つの異なるアプローチを紹介していきます。
私もまだ初学者であり、説明が間違っていたり勘

AI の, AI による, AI のための Governance
こんにちはこんばんは、teftef です。ここ最近の AI (Artificial Inteligence) は様々な形で私たちの身の回りのタスクを補うようになっています。しかし AI を受け入れ、共存していくという選択肢とともに AI に支配(統治)されることを恐れる声もあります。現在の AI にはどのような能力があり、人間とどのような関係性を気づいているのか、また、これから先私たちは AI
もっとみる
DeepFloyd IF : 自然言語モデルの知識を利用した画像生成モデル (Imagen)
こんにちはこんばんは、teftef です。2023 年 4 月 29 日に Stability AI に所属する開発チーム : DeepFloyd から Stable Diffusion とは異なる手法を使用した DeepFloyd IF が公開されました。このモデルは文字を破綻せずに生成できたり、高品質な画像を生成できるモデルとして注目を集めています。今回はこの DeepFloyd IF のベ
もっとみる
CyberAgent より、画像生成タスクにおける新たな評価指標の提案
こんにちはこんばんは、teftef です。今回は CyberAgent より、生成モデルから生成された画像の品質評価に関する論文です。近年の画像生 AI の発展によって、『高品質』な画像が生成できるようになりました。しかしよくよく考えてみると『高品質』というのは何でしょうか?人間の好みが違いをどのように評価するのでしょうか?今回はそこについて軽く書いていきます。
私もまだ初学者であり、説明が間
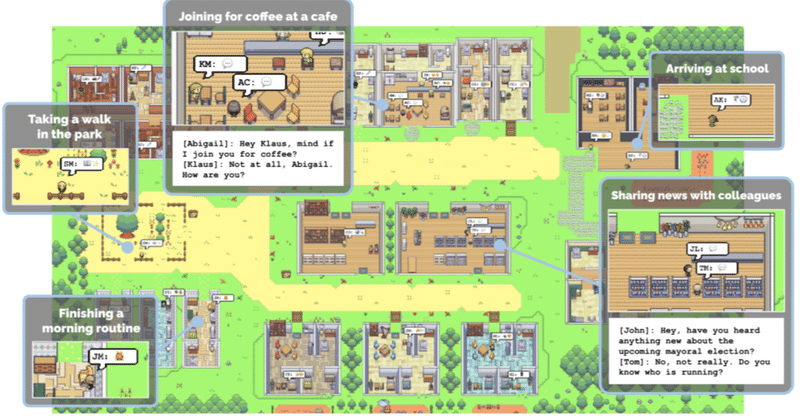
エージェント論文:Chat GPTによる人間社会のシミュラクラ
こんにちはこんばんは、teftef です。今回はシミュレーションゲーム「ザ・シムズ」にインスパイアされた、スタンフォード大学と Google の共同研究である「エージェント論文」です。ChatGPT を用いた 25 人の AI エージェントを実際に 2 日間動かし、どのようになったかを調べました。町の様子や家具の動作、人間関係など設定がかなり凝っていて、実世界にかなり近い結果となっています。
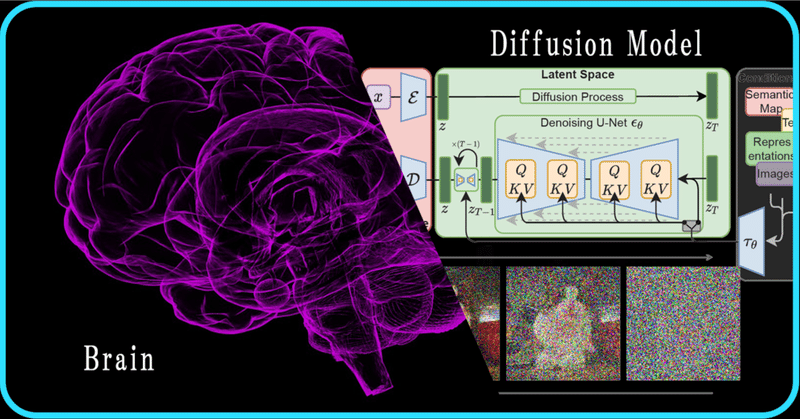
fMRI から画像を生成する話
こんにちはこんばんは、teftef です。今回は大阪大学から出た fMRI 画像から Stable Diffusion を用いて画像生成する論文をベースに Brain 2 Image について書いていこうと思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、

AI を自分好みに調整できる、追加学習まとめ (その2 : Textual Inversion )
こんにちはこんばんは、teftef です。昨今のAI画像生成において、既存のモデル以外にも、独自の「絵柄」や「画風」を出力できるようにした『オリジナルモデル』を制作する方々が増えています。しかし個人が 0 からモデルを学習させるには膨大な時間と計算量を必要とするため、既存のモデルをベースに学習する「追加学習」と呼ばれる手法を使用することが一般的でしょう。追加学習の大雑把な解説は前回の記事をご覧く
もっとみる