
Negative Prompt を入れるタイミングについて

こんにちはこんばんは、teftef です。久しぶりに書きます。
今回は Negative Prompt が画像生成時に与える影響についてです。
簡単に内容だけネタバレすると、Diffuseion モデルの推論では Negative Prompt は 1 step 目からかけるより、 n >1 step 目からかけたほうがいいんでね。という趣旨です。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
※この記事は有料となっていますが、最後まで内容が読めます。
Diffusion Model
Diffusion Model の推論(Reverse step)は完全なガウシアンノイズから開始し、学習済みのUnet を用いて、Time step ごとに応じた特定の平均と分散を持った微小ガウシアンノイズを除去することで画像を生成します。このプロセスでは、 Prompt と呼ばれるテキスト入力を条件として使用します。 テキスト条件は、Attention Block 内のクロスアテンションを通じて、Text 入力に沿ったノイズ除去を実現します。これにより、最終的に Prompt に沿った画像が生成されます。
Negative Prompt と CFG
現状の画像生成では、除去するノイズを決定する際に、CGG(Classifier-Free guaidance) を用います。
$$
\epsilon_{\theta}^{\prime} = {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) + \gamma \left( {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) - {\epsilon_\theta}(\mathbf{x}_t, t, \text{NULL}) \right)
$$
この場合では、 Prompt に [""] を入れた状態 (何も入れない状態) で予測されたノイズと、Prompt を入れた状態で予測されたノイズの差分の外分をとることで、 Prompt がノイズ推定に与える影響を増幅させます。こうすることで Prompt に対する忠実性を向上させることができます。通常 γ = 7 ~8 をとることが多いと思います。

対して、Prompt (以降、便宜的にPositive Prompt と呼ぶ)だけでなく、画像に含まれたくない情報を、 Negative Prompt として入力し、上式を
$$
\epsilon_{\theta}^{\prime} \\={\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) + \gamma \big[ \{ {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) - {\epsilon_\theta}(\mathbf{x}_t, t, \text{NULL}) \} - \{ {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{neg}}) - {\epsilon_\theta}(\mathbf{x}_t, t, \text{NULL}) \} \big] \\= {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) + \gamma \left( {\epsilon_\theta}(\mathbf{x_t}, t, \mathcal{T_{pos}}) - {\epsilon_\theta}(\mathbf{x}_t, t, \mathcal{T_{neg}}) \right)
$$
と変形することができます。これによって生成画像に含まれて欲しくない情報を消すことができるようになります。

Negative Prompt の影響
しかし、 Negative Prompt を入れることによって、元の画像の構造や背景など、Negative Prompt で指定した以外の要素を変更してしまうことがあります。実際に画像を見ると、Positive Prompt をのみの場合に比べて、Negative Prompt を入れてしまうと、構造や背景が大きく変わってしまっています。

Negative Prompt はいつ効くのか
そこで、 Negative Prompt の効きを調べることのよって、Negative Prompt で指定した以外の要素をなるべく変えることなく生成し、 Positive Prompt の構図を保ちつつ Negative Prompt の効きを最大化させます。

まずは Negative Prompt がいつ効いているのかを調べます。上図では、特定の Time step にのみ Negative Prompt を適応して画像生成した様子です。例えば上の行では Negative Prompt に glass を入れていて生成した際に 4 step 以降に Negative Prompt を入れた場合に大幅に構造が変わっていることがわかります。
理由1
Negative Prompt が適用されない場合(図2の最初の列)、指定されたオブジェクトは生成されません。これは通常通りの動きです。しかし、初期段階でネガティブプロンプトを導入すると、構造が定まらないうちにNegative Prompt が影響している画像が生成されてしまい、Negative Prompt が適用されない場合の構造が維持されません。Negative Prompt を初期段階で適用すると、その後のステップでもその影響が持続し、オブジェクトの生成が促進されてます。
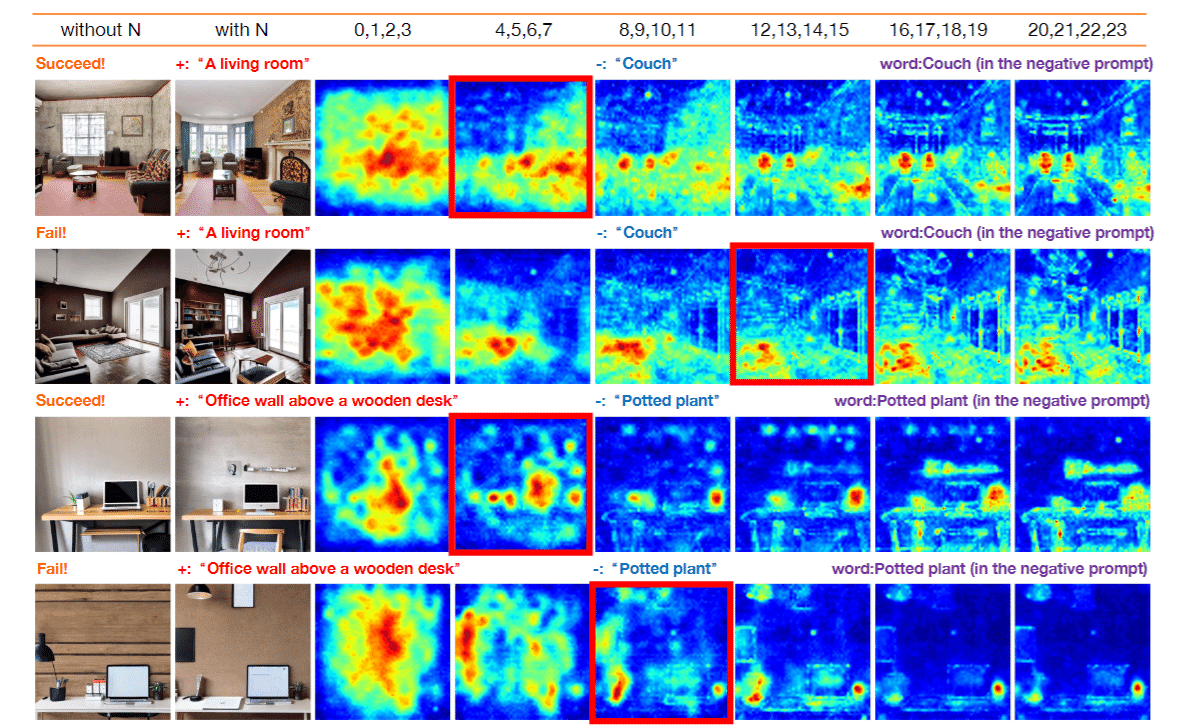
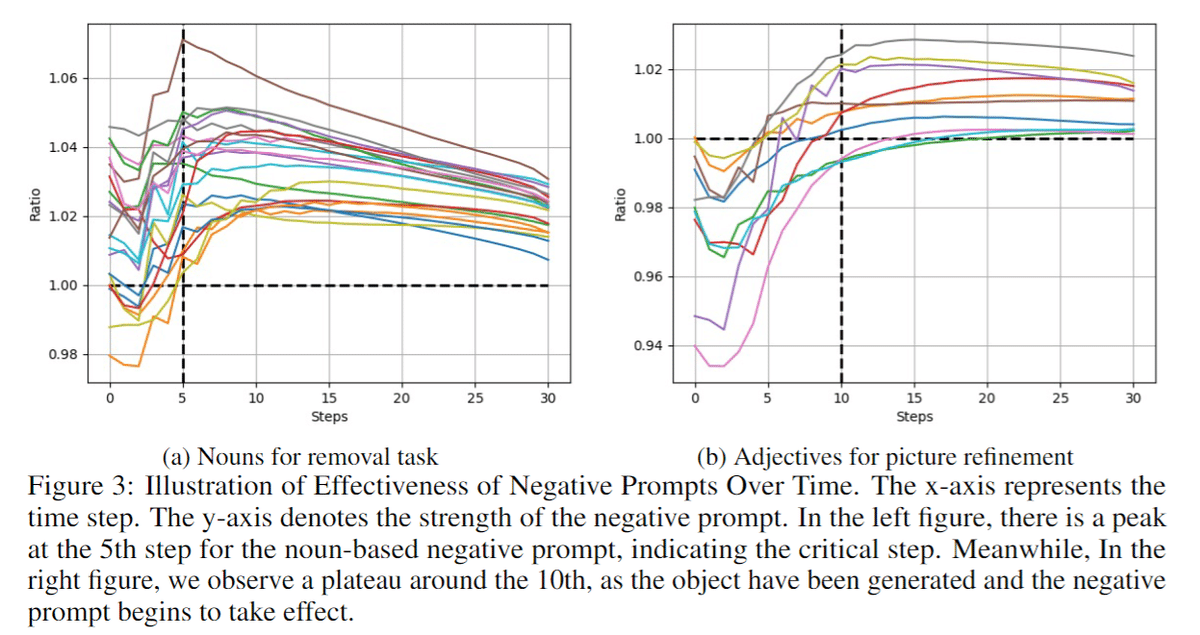
実際に、調べてみると初期段階では Negative Prompt と Positive Prompt は同等に扱われているが、5 step あたりでピークに達し Negative Prompt が Positive Prompt ので生成された構造を基にオブジェクトを除去しようとし、その影響が最大になり、オブジェクトが画像から消えると、Negative Prompt の影響も減少する。
理由2
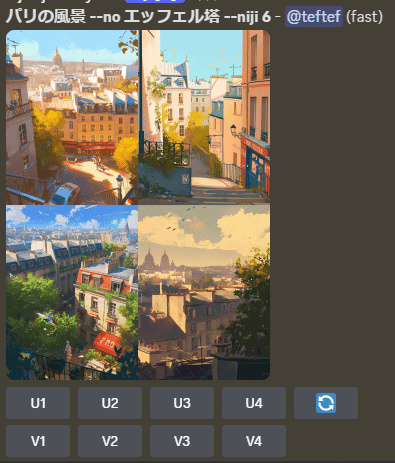
もう一つは尤度ベースのモデルに原因があります。まず、モデルは学習データによって知っている知識が異なります。学習データにも大きな偏りやもつれがあります。例えば、女性の髪の毛は長いのが多く、剥げている頭の画像はほとんどが男性であり、パリの町並みにはエッフェル塔が映っていることが多いです。それゆえにレアケースに当たった時に活性化エネルギーが非常に高くなってしまい、そのレアケースに映りにくくなってしまいます。わかりにくいので、例を出します。

例えばパリの風景を生成したい場合、エッフェル塔がないパリの風景は非常にレアなデータです。そのため、初期段階でNegative Prompt としてエッフェル塔を適用してしまうと、その強い影響によりエッフェル塔を取り除くために必要な活性化エネルギーを超えることができず、エッフェル塔が残ってしまうことがあります。
分かったこと
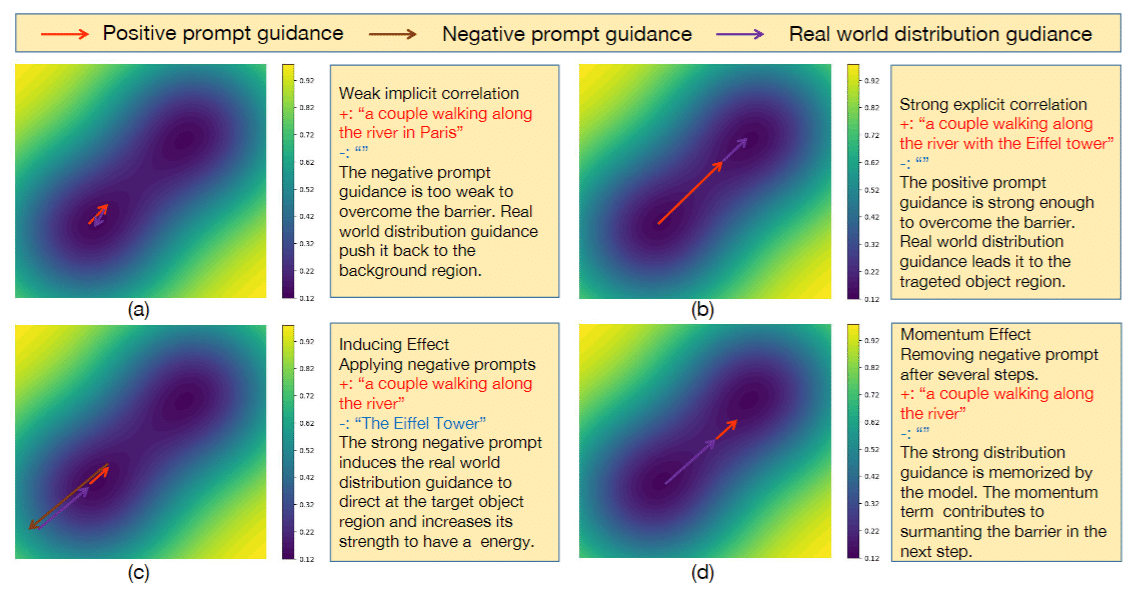
(a):
Positive Prompt : パリの川沿いを歩くカップルのイメージ。
Negative Prompt : なし
結果: ネガティブプロンプトのガイダンスが弱く、実世界の分布ガイダンスにより背景領域に戻される。
(b):
Positive Prompt : エッフェル塔と共に川沿いを歩くカップル。
Negative Prompt : なし
結果: ポジティブプロンプトのガイダンスが強く、エネルギーバリアを超えてターゲットオブジェクト領域に導かれる。
(c):
Positive Prompt : パリの川沿いを歩くカップル
Negative Prompt : エッフェル塔
結果: 強いネガティブプロンプトが実世界の分布ガイダンスをターゲットオブジェクト領域に誘導し、その強度を高める。
(d):
Positive Prompt : パリの川沿いを歩くカップル
Negative Prompt : なし
結果: 数ステップ後にネガティブプロンプトを取り除くと、実世界の分布ガイダンスが記憶され、次のステップでバリアを越えるのに貢献する。
このことから、 Negative Prompt にはモーメンタムのような働きがあり、その効きが画像全体に大きく影響してくることがわかります。
そこで 初期ステップでの Negative Prompt の影響を避けることで、(d)のように Positive Prompt だけのガイダンスが働き、エッフェル塔のないパリの風景を生成することができます。
このように、ピークに達したときに Negative Prompt を掛けるとで、効果的に機能させることができます。
そのタイミングは
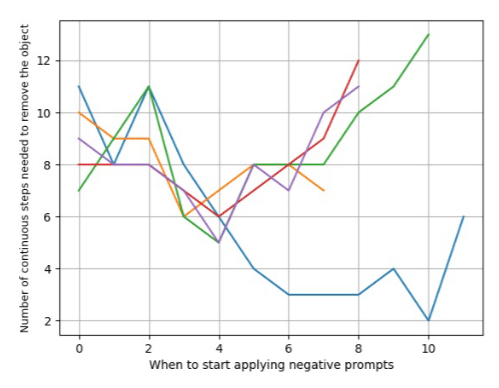
y軸: 対象オブジェクトを正確に除去するために必要な連続ステップ数を示しています。
では、そのピークのタイミングはいつなのか。
図を見ると、 Prompt によってタイミングが異なります。このように Prompt の効きをマッピングしてみると U 字のようになっていて、その最小値がピークになっています。
ピーク以降に Negative Prompt をかける
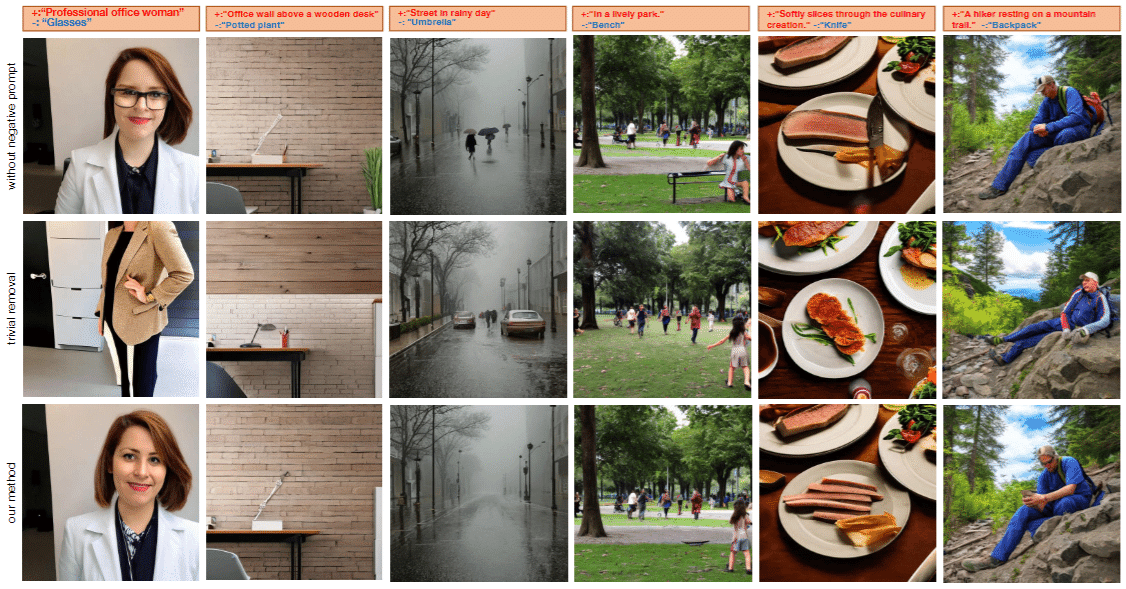
結果を見て見ると、このように単純に Negative Prompt を入れた場合に比べて、ピーク以降に Negative Prompt を適応したときには構造が多き変わらずに Negative Prompt の内容が除去されています。
実際にやってみよう
それでは、実際にやってみましょう。今回は Kohya さんの sd-Scripts をお借りしました。
py
if do_classifier_free_guidance:
if negative_scale is None:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings]) ## cat torch.Size([1, 77, 768]) and torch.Size([1, 77, 768])
if args.negative_prompt_steps > 0:
none_negative_text_embeddings, none_negative_uncond_embeddings, none_negative_prompt_tokens = get_weighted_text_embeddings( ## ここで Prompt = [""] を Embed に変換
pipe=self,
prompt=prompt,
uncond_prompt=[""] if do_classifier_free_guidance else None,
max_embeddings_multiples=max_embeddings_multiples,
clip_skip=self.clip_skip,
**kwargs,
)
text_embedding_no_uncond = torch.cat([none_negative_uncond_embeddings,text_embeddings_tmp])
else:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings, real_uncond_embeddings])
py
for i, t in enumerate(tqdm(timesteps)): ####genration roop starts
# expand the latents if we are doing classifier free guidance
latent_model_input = latents.repeat((num_latent_input, 1, 1, 1))
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
if self.control_nets and self.control_net_enabled:
if reginonal_network:
num_sub_and_neg_prompts = len(text_embeddings) // batch_size
text_emb_last = text_embeddings[num_sub_and_neg_prompts - 2 :: num_sub_and_neg_prompts] # last subprompt
else:
if i < args.negative_prompt_steps :
text_emb_last = text_embedding_no_uncond
else:
text_emb_last = text_embeddings
noise_pred = original_control_net.call_unet_and_control_net(
i,
num_latent_input,
self.unet,
self.control_nets,
guided_hints,
i / len(timesteps),
latent_model_input,
t,
text_emb_last,
).sample
else:
if i < args.negative_prompt_steps : ## Negative Prompt なしでノイズ予測
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embedding_no_uncond).sample
else: ## Negative Prompt ありでノイズ予測
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sampleこんな感じで変更します。
それでは CFG : 7.5 , step : 40 , Scheduler : DDPM , シードはそれぞれの行で固定して Negative Prompt を適応するタイミングを変えて生成ます。
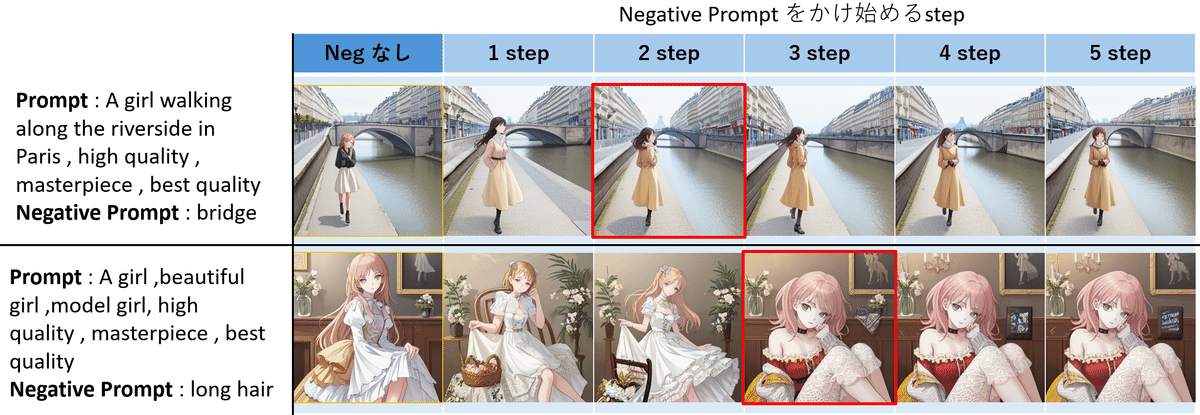
結果
1行目は 2 step 目に最も Bridge 要素を取り除くことができましたが人が変わってしまいました。
2 行目は分かり易く、 3 step 目から short Hair になり、また背景の棚や植物、絵画が Negative Prompt がない状態から、比較的維持されています。しかし、やはり人物は大きく変わってしまいました。
なかなか論文の通りには行かないですね…(実装違ったら教えてください)
まとめ
自分で実装してやってみた結果、論文を完全に再現することはできませんでしたが、提案手法では Negative Prompt を掛けない時に生成されたオブジェクトが維持されていることから、ある程度の効果はあることがわかりました。
しかし、一つの属性だけを変更する際に他の属性に影響しないような Disentangle な変形を行うためには、推論だけではなく、学習段階、 LDMs だと VAE の学習段階からもつれの少ない特徴空間を設計する必要がありそうです。
参考文献
最後に
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーでは Midjourney やStable Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(5,500 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?