
CyberAgent より、画像生成タスクにおける新たな評価指標の提案

こんにちはこんばんは、teftef です。今回は CyberAgent より、生成モデルから生成された画像の品質評価に関する論文です。近年の画像生 AI の発展によって、『高品質』な画像が生成できるようになりました。しかしよくよく考えてみると『高品質』というのは何でしょうか?人間の好みが違いをどのように評価するのでしょうか?今回はそこについて軽く書いていきます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。(ちなみにサムネはnijijyourney を用いて、評価指標、統計学、 --ar 3:2のように関連キーワードで作ってます)
それでは行きます。
論文
今回参考にさせていただいた論文はこちら
画像生成 AI の評価
近年の Stable Diffusion や Midjourney などの画像生成 AI は自然言語を元に、非常に「高品質」な画像を生成できるようになりました。現状、画像の品質評価には FID や CLIP Score などの機械的な定量評価指標があります。それぞれについて軽く見ておきます。
FID
FID(Frechet Inception Distance)は GAN などの定量評価指標の一つです。生成された画像(生成画像)の集合と本物の画像(実画像)の集合をInceptionネットワークを使用して、画像の高次元的な情報を保持した特徴ベクトルに変換します。この 2 つの特徴ベクトルの分布をガウス分布と仮定して、平均と共分散行列を求めます。これらの値を用いて、確率分布間の "距離" (どれだけ似ているか)を測ることで生成画像が実画像とどれだけ近いかを評価することができます。値が小さければ小さいほど『高品質』と評価されます。
CLIP Score
CLIP Score は自然言語と画像のペアを学習することげ、両者間の意味的な関係性を捉えます。自然言語と画像のペアをそれぞれ特徴ベクトルに変換し、これらの Cos 類似度を計算します。CLIP Score が高いと、より関連性の高い画像-テキストペアとなります。CLIP Score は自然言語と画像のペアの一致度、関連度を評価します。値が大きい (1に近い) ほど高い評価を行います。

また私たちの感覚としては、品質は一番右の画像は低いはずです。
Inception Score(IS)
Inception Score(IS)は生成された画像の品質(quality)と多様性(diversity)を評価します。品質(quality)に関しては、生成された画像を Inceptionネットワークを用いて分類(ラベル付け)して、正しい分類結果に一点集中すればするほど『高品質』な画像ということになります。多様性(diversity)に関しては生成されたすべての画像を多様なラベルに分類できる(エントロピーが高い)状態ほど『多様性』が大きいということになります。これらを合わせて、生成画像の品質(quality)の分布が大きく、多様性(diversity)の分布が小さいスコアになる、つまり、条件付きクラス確率分布とクラス確率分布との間のKLダイバージェンス (KL divergence)を大きくすればするほどいいスコアということになります。
そのほかにも評価方法 (LPIPS など) はありますが、機械的な定量評価指標はこの 3 つが有名なものとなっています。
問題点
しかし、この FID というスコアは実際に人間の感覚とは大きく異なる評価をすることがあり、本当に人間のいう『高品質』とは異なる結果を出すことが多くあります。また他の評価指標も同じように私たちの感覚とは異なる結果を出力することがあります。(後述)
加えて、画像とその Prompt の一致度を測定することが難しくなっています。簡単な描写なら、ある程度評価できるのですが、ある程度複雑な描写を評価することができません。また CLIP Score においては CLIP が学習していない表現を評価することが難しく、現在のモデルの進化スピードに少し時代遅れな評価となってしまうことがあります。
提案手法
そこで今回、あらためて人による画像生成の評価に取り組みました、機械的評価以外に人間によるアンケートを用いて画像の『品質』を評価する主観的評価があります。しかし、これはただ道端アンケートのように無造作に人を選んでアンケートを実施しても信頼性が保証されません。そこである程度の専門知識などの信頼できる人物による回答、その人がでたらめに回答していないという保証が必要となります。また回答する人数も大事になっており、あまりにも少ないサンプル数は偏った結果を生み出すことになります。
今回の目標
これらを総合的にまとめて、人間による評価をできるフレームワークを作成し、信頼性のある条件を用いた新しい評価方法を提案します。
また機械的評価指標と人間による評価のズレを分析することで機械的評価指標を評価することもでき、機械的評価の改良につなげます。
近年の論文
まず、手始めに近年のtext2image に関する論文を 37 本選びすべても評価方法を調べました。


その結果、人間による評価をした論文は 20 本だけでした。(つまり 17 本は FID などのスコアのみで評価されているということになります。 4割くらいです、意外と多いですね。) この 20本の論文の中で 18 本が人間や画像のサンプル数などの情報を報告しています。中でもサンプルごとの評価数 (より詳しく)を評価しているのは 4 本のみでした。
つまりほとんどの論文が機械的評価指標のみを用いている or 評価方法の信頼性に不足があると言えます。
基準
評価にはどのような問題があるか、細かく見ていきます。
側面
画像の全体的な品質とテキストプロンプトとの関連性に関しては、18の論文が全体的な品質を評価し、14の論文がテキストとの関連性を評価しています。しかしこれだけではなくオブジェクトの位置の正しさ、複数画像生成の一貫性などを含め評価する必要がありますが、一部の側面からしか評価をしていない論文がありました。
妥当性
論文によって人間評価の実施方法に大きな相違がある。しかし、その妥当性についてはほとんど議論されていません。
アノテーションクオリティ
アノテーションとは、データや情報にtext などのタグ付けをすることで、その意味や関連性を明確にすることであり、画像では画像内の物体や特徴などをキストや図形を用いて情報を付加します。

アノテーションでは、品質を報告しないという問題のある。アノテーションの典型的な評価指標は、Cohen’s κ や Krippendorff’s α のようなアノテーター間合意(IAA)であり、この品質を報告してないと信頼性の低下につながります。
サンプルサイズ
ほとんどの論文では評価に用いた人数 (サンプルサイズ) 100 人未満となっていて、偏りが生じる可能性があります。
報酬と資格
倫理的に、人を使うということはそれに対して賃金が発生することになります。例えば無賃労働で評価させてしまうと、やる気搾取となり、その人がでたらめな評価をする可能性もあります。
また評価する人間が素人ではいけません。資格のような基準が必要となります。
UI
アノテーションのためのユーザーインターフェイスは選択に影響が出ることがありますが、評価したときのインターフェイスを公開されていない論文が多いです。
今の解決策
そこで、今回は経験の浅いアノテーション担当者でも、タスクに慣れるための余分な努力をすることなく、タスクを完成させることができるようなシンプルなものを作成し、私たちがわかりやすいような直感的なスコアリングができる評価フォーマットを使用します。

評価には絶対評価を用い、2つの側面から評価しました。
忠実性 (Fiderity) : 生成された画像がどれだけ実際の写真に似ているか
整合性 (Alignment) : アライメント、生成された画像がどれだけテキストと一致しているか、
(一貫性ともいうかな?)
これまでと違い、アンケートの選択肢に工夫がしてあります。

→提案された選択肢
左の A はこれまでの選択肢は典型的な選択肢で、右の B は今回提案された選択肢です。この図のように B ではより選択肢を具体的に書き、回答者の主観を減らしています。また
忠実性 (Fiderity)
1 : AI generated Photo (AI 製である)
5 : Real photo (実画像である)
整合性 (Alignment)
1 : Does not match at all (text と画像の整合性がまったくない)
5 : Matches exactly (text と画像の整合性がとても高い)
のように極端な選択肢を含んでいます。
実験
COCO Captions の 200 のテキスト-画像ペアに対する人間のアノテーションをサンプリングしました。この 200 個のサンプルのうち、100 個の画像はキャプションを条件として Stable Diffusion によって生成され、残りの 100個の画像は実際のものにしました。条件としては以下の通りです。
各評価タスクに対して0.04ドルの報酬を得る
回答者 1 人あたりのアノテーション数を最大 40 に制限
成熟度、経験、場所の資格フィルターで回答者を選別
人選
この中でもあのテータ―の選別方法は以下の 5 種類を基準にしています。
i) 成熟度: 18歳以上であり、攻撃的なコンテンツを扱うことに同意している。
ii) 経験: 5000件以上のHITを完了した。99% 以上の承認率。
iii) 所在地 : 英語圏に所在すること。
← VPNでごまかせるよね!!!!iv) スキル : 画質評価、文字と画像の位置合わせの基本的なスキルを確認するための3つの簡単な質問からなるプレタスク資格テストに合格している。
v) AMTマスター: 成績が良く、AMTマスターを取得した者。
結果
それでは実際の結果を見ていきます。

表の見方
Qualification 、今回は人選のパターンを 4 パターン用意しています。(一番左)
Annotator performance (真ん中)は、あるデータセットに対して付与したラベルや評価の一致度を測っています。(1に近いほど一致)、また Med.Time は解答時間の中央値です。
右の Stable Diffusion と Realimage の値は、3 人の回答者を用いて 1~5 の評価をした時の平均値を算出した結果です。(右 2 つ)

専門性やスキルなどを無視した回答者ループが回答にかける時間が短いことが観察されましたが、IAAが低くなってしまいました。(赤枠)
一方で、(v) : AMTマスターグループは、IAAが高く、その割に回答時間が大きく悪化しないことから、今後の実験ではマスター資格フィルターが使用しました。(青枠)
モデルを評価する
それでは実際にこの青枠の条件を用いて、 4つのモデルを評価してきます。
使用するモデル
Lafite、GLIDE、CogView2、Stable Diffusion です。
使用するデータセット
COCOデータセット(画像と、各画像に対して5つの注釈付きキャプションを提供するデータセット)
DrawBench (長いテキスト、珍しい単語、スペルミスなど、難しいテキストプロンプトを集めたもの)
PartiPrompts (プロンプト学習に使用される大規模な自然言語処理のデータセット)
を用いて、5つのキャプションの内1つを選んで画像を生成して評価します。
結果
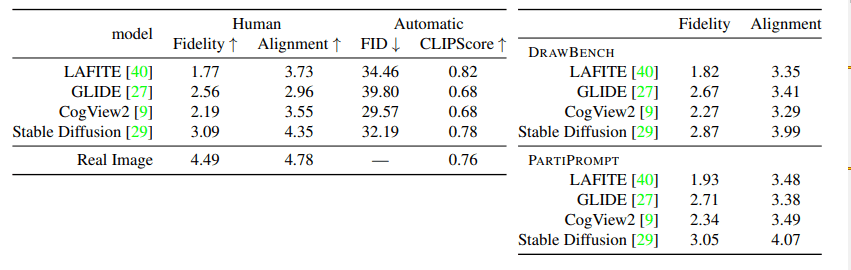
忠実性 (Fiderity) の結果

このように、忠実性ではFID は CogView2 が最も優れている結果を出しました。
しかし人間による評価では Stable Diffusion を忠実度の点でモデルの中で最も優れていました。(CogView2 は3位)
では実際に生成された画像を見てみましょう。

これを見ると CogView2 は Stable Diffusion よりもおかしい部分が多く発生していることがわかります。また LAFITE と GLIDE の順位も、FIDと人間の評価で矛盾しています。
FID の考察
FIDはこのような不規則なテクスチャを捉えることができず、人間の評価とかけ離れていると考えられます。
整合性 (Alignment) の結果

興味深いことに、LAFITE (黄色) は Stable Diffusion (赤) に比べて、CLIP Score において非常に高いスコアを達成していますが、表の右側や 人間による評価を見るとに示すように、人間の回答者は、アライメントの観点から Stable Diffusion (赤) を最も良く評価しています。
では実際に生成された画像を見てみましょう。

このように右の列の LAFITE の画像はお世辞にも『高品質』とは言えません。 CLIP Score が良いからと言って必ずしも整合性 (Alignment) が良いとは限らず、スコアの尺度は画像とテキストの整合性 (Alignment) の良し悪しを表しているわけではありません。
CLIP Score の考察
実は、LAFITE では CLIP ベースのGANの損失に関して最適化を伴うため、スコアが高いのは当然の結果です。(CLIP 空間を用いて生成しているから)
対して、Stable Diffusionは、CLIP空間での最適化を行ってないにもかかわらず、スコアが高いので Stable Diffusion の性能の高さがわかります。
結論
以上の結果から、以下のことがわかります。
評価指標は、しばしば最適化における目的となっている (LAFITEなど)
CLIP Scoreは、人間のアノテーターが Stable Diffusionで生成した画像と実画像を区別できるにもかかわらず、実画像を区別できない
CLIP 空間にはギャップがある
CLIP Score はすでに飽和状態にあり、最先端の生成モデルの評価にはもはや役立たない
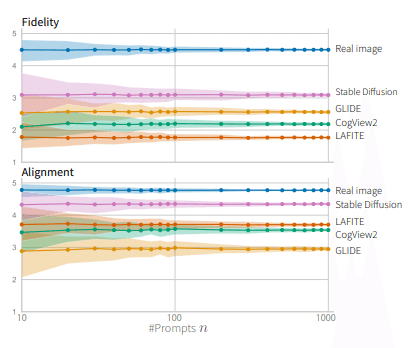
サンプル数
プロンプトのサンプル数については少し割愛します。少ない評価数で評価すると不安定になることが直感的にも明らかです。一貫した結論を得るためには、100以上のプロンプトが必要であることがわかりました。
全体のまとめ
今回の実験によって、現在の機械的評価指標は人間の知覚を表現するには不十分ということがわかりました。特に FID や Clip Score では最先端の生成モデルの評価にはもはや役立たないということも判明しました。これを踏まえて、今後は、機械的評価指標だけに頼って結論の信頼性が低くなってしまうので、人間による評価もするべきであると考えられます。
しかし人間による評価でも以下を気を付ける必要があります。
透明性を確保するための実験内容の報告
文献はアノテーションの詳細な説明を提供する
補足資料として人間評価設定の報告 (bot などを排除する)
今後の課題
生成された画像に望ましくない偏りがある場合の評価をどうするか。
AMTマスター資格による評価の限界
i) 限定的である
ⅱ)マスター資格の基準が不明確である
などがありますが、これらを解決するためには、他の資格で代替することがあげられますが、コスト問題というのは付きまとうと考えられます。
主の考察
FID や IS などは『高品質』を説明するときによく使う指標ですが、これら評価指標による結果は「ほんとに?」と疑うことが多くあります。この論文では、これに対処するためには自動化された尺度を常に更新し、人間の知覚に合うようにする必要がある。と、まとめてあり、その通りだなと感じました。しかし、昨今の生成 AI の早い技術発展に沿ったような評価指標を開発することは非常に難しいことであり、研究が期待されます。
人間の好みは人種、文化、居住地、さらには個人で十人十色であり、それを定量的に線引きするというのは非常に難しいタスクです。しかし、人間の感覚であるからこそ生の人間による評価結果と統計を使い、新たな指標を更新し続けることは大事だと考えています。
参考文献
次回予告と宣伝
今回は人間の『高品質』という感覚に突っ込んだ論文となっています。そのため、「良し悪しの境界はここ」という結論には至りませんが、大まかな評価指標の一つとして、人間の感覚による評価方法を採用することの重要性について伝わればと思います。次回も画像生成に関することになりそうです。
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(7200字、teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?