
ビッグデータマイニングとアナリシス_グループワーク

どうも!
セイタです!!
北京大学社修士課程で社会学を学んでいます。
この記事では、自分が北京大学で
・どのような授業を受講したのか
・どのような授業の進め方なのか
・課題をどのようにクリアしていったのか について執筆していきたいと思います。
対象としている読者は
・中国の大学に興味がある。
・社会学修士に興味がある。
・海外の大学院に興味がある。
方を想定しています。
もちろん当てはまらない方でも全く問題なく読める内容となっております。
《ビッグデータマイニングとアナリシス(大数据挖掘与分析)》という授業で行われた課題である3つのグループワークについて詳細に説明しています。授業の概略については下記記事をご覧ください。
この記事では
・グループワークの内容
・どのように取り組んだか?
・その他のメンバーの様子
・グループでのアウトプット
について書いていきます。
正直グループワークはどんな学生と一緒のグループになるかが成績を決めるといっても過言ではありません。自分は最初こそくじ運に恵まれませんでしたが、後に行くにつれてツキが巡ってきました(笑)
結果として、この授業の成績は「A+」でした!!
GPA4.0です!!
うれしいです(笑)
一つ目の課題-回帰分析
一つ目の課題は二つのテーマがあり、5人で分担して行います。一つ目が「平均収入予測」で、もう一つが「消費者購買予測」です。ともに回帰分析をメインで使用します。
この課題は最初の課題だけあって、そこまで難易度は高くなかったように感じました。
メンバー
自分以外のメンバーは
・政府管理学院
・マルクス主義学院
・·新聞伝播学院
・景観学院
でした。
学部の癖が強めですね(笑)
一回目の宿題の時のメンバーが一番くじ運なかったです。
まず、新聞伝播学院の学生が「知り合いのPythonできる子に200元で頼もうと思うけど、どう?」みたいなことを言っていて、マルクス主義学院の学生に「そもそも何のために宿題やってるの?」みたいな感じで一蹴されてました。
ちなみに、マルクス主義学院の学生はなぜかめっちゃPythonできてました、、
また、景観学院の学生も自分でグループ会議しようと言っていたのに、忘れていて参加しなかったり、グループワークの最後の部分の担当にも関わらず、前日になって、「なんか数字がうまいこといかない」みたいなことを言っていました。
政府管理学院の学生は最初はいい感じだなと思ってました。しかも「統計学やったことある」って言っていたので。なので、政府管理学院の学生とペアになって、グループワークに取り組んだのですが、正直統計学に関しては全然ダメでした(笑)
自分が数字の前処理を行って、そのあとに回帰分析をお願いしたのですが、「全然有意な数字にならないから、学院の同級生に聞いてくれないか」とお願いされました。そこで、コードを見ると、あろうことか名義尺度をそのままモデルに使用していました、、、
※後述します
ちなみに、10分で理由がわかりました(笑)

グループワークの進め方
グループワークは2人と3人に分かれて実施しました。自分は政府管理学院の学生と一緒に「消費者購買予測」に取り組みました。自分が前処理をした後にデータとコードを政府管理学院の学生に渡したのですが、彼は「名義尺度」をそのまま変数として使っていました、、
あまり定量調査になじみのない人のために少し説明すると、
「名義尺度」というのは、他と区別し分類するための名称のようなもので、数字で表されてはいますが、数字そのものに意味がない変数のことです。
例えば、都道府県でいえば、北海道に1、青森に2、沖縄には47という数字を慣習的につけますが、数字そのものに意味がありません。北海道の方が沖縄よりも影響が小さいということはありません。
ただ、この変数をそのまま統計モデルに使ってしまうと、まるで北海道は1という効果しかないが、沖縄は47という効果があるという風に統計ツールは解釈してしまいます。上記のような問題を回避するために、ワンホットエンコーディング(One Hot Encoding)という手法を使うことが多いです。自分も今回この手法を使いました。
血液型という項目を例にとると、
1, A型
2, B型
3, O型
4, AB型
といった項目があった場合には以下のような処理が必要です。

もしそのまま数字として使ってしまうと、数字が1のA型は効果が少なくて、数字が4のAB型は効果が大きいなどのように、各項目ごとに順序があるかのようにモデルが処理してしまうからです。そのような処理をしてしまったら、当然ですが有意なモデルになりません。
このミスをしてしまった学生は政府管理学院に所属しているのですが、英語圏だとMaster of Public Administration、日本だと公共政策院学部にあたります。学部の知り合いにも何人かいるのですが、定量調査や計量経済に長ける学生が多い印象です。そのため、政府管理学院かつ自分で「統計やったことある」って言っていたので大丈夫かなと思っていましたが、全然ダメでした(笑)
ただ、それ以外はしっかりしていました。時間も守りますし、提出期限に余裕をもって間に合わせます。書いたコードをレポートにしないといけないのですが、丁寧に書かれていました。なので、統計の理論を授業で齧っただけで、手を動かしたことがないのだと思います。僕は社会人時代に前処理おじさんだったのでこの辺は実務で嫌ほどやっていました(笑)
あとは、二つのグループの課題をがっちゃんこして提出するだけです。提出期限ぎりぎりですが、何とか間に合いました、、
この課題は5時間強で終わりました。
二つ目の課題−グループプレゼン
二つ目の課題はグループプレゼンです。各自与えられた論文リストの中から好きな論文を選び、その内容で発表します。自分の班は論文リストに唯一あった中国語の論文をマルクス主義学院の学生が抑えてました(笑)
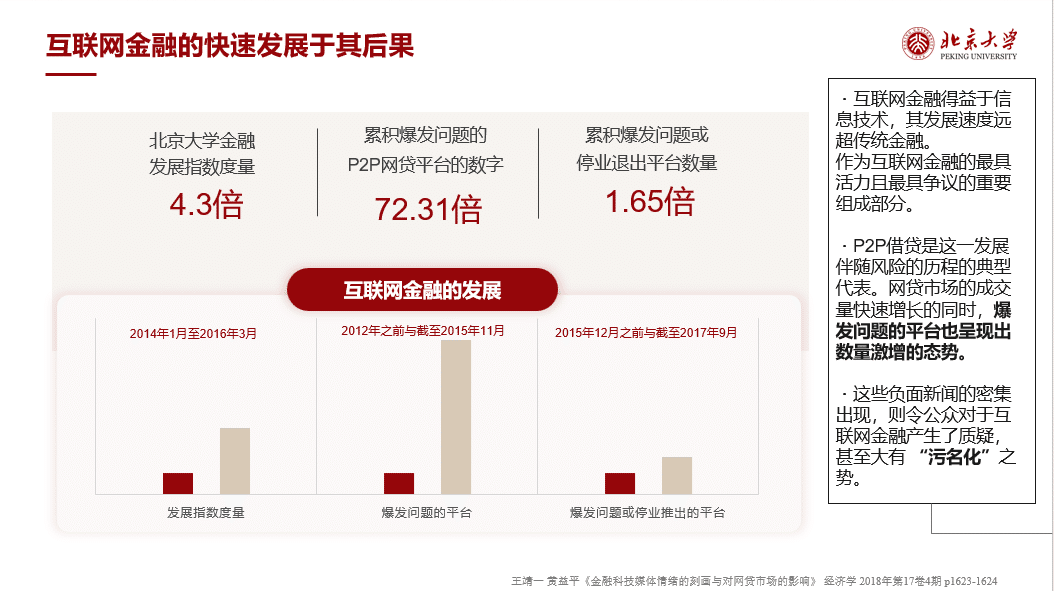
テーマは「フィンテックがメディアの感情表現がネットバンキングマーケットに与える影響」です。
※下記が論文概要です
王靖一 黄益平《金融科技媒体情绪的刻画与对网贷市场的影响》 经济学 2018年第17卷4期 p1623-1624
内容としては、フィンテックがネットバンキングマーケットに与えた影響を比較的高度な手法を用いて、分析するといったものです。内容が難しくて、あんまりわかってません、、、
自分の担当が導入で本当によかったです(笑)
メンバー
自分以外のメンバーは
・政府管理学院×2
・社会学院(専門修士)
・マルクス主義学院
です。
社会学には2年制の専門修士と3年制の学術修士があります。学術修士の方が学費が安かったり、学生寮が提供されたりいろいろメリットがありますが、その分入るのが難しいです。自分は3年制の学術修士です。
※詳細は以下の記事をご覧ください。
今回もマルクス主義学院の学生が非常に優秀で、やりやすい論文を抑えただけでなく、プレゼンのとりまとめもしてくれました。おかげで、自分は導入をわかりやすくまとめるだけで済みました
自分が作成したプレゼン
以下自分が作成したプレゼンのみ紹介させていただきます。



ざっくりこんな感じです!!
北京大学はテンプレートがいっぱいあって、プレゼン作成が本当に楽です(笑)
この課題は4時間で終わりました。
三つ目の課題-テキストマイニング
ここも2つの課題があります。1つが「豆辮(DouBan)の映画批評の感情分析」で、もう1つが「IMDbの映画批評の感情分析」です。自分は豆辮という中国の映画レビューサイトを担当したのですが、今回はテキストマイニングの手法が必要であり、めちゃくちゃ苦労しました。。。
とりあえず、参考になるコードをコピペして、何とか結果だけ出したって感じです。本質的にあまり理解できていません、、
メンバー
自分以外のメンバーは
・政府管理学部
・社会学院(学術修士)
・情報管理学部
・深圳研究学院
です!
自分は社会学院と深圳研究学院の学生と一緒に「豆辮(DouBan)の映画批評の感情分析」に取り組みました。同じクラスの社会学院(学術修士)の学生がめっちゃPythonも定量調査もできるのを知っていたため、同じグループになるようにしました(笑)

自分が担当した箇所
2人のメンバーがほとんど終わらせてくれたので自分は何もしなくていいかなと思っていたのですが、そんなに甘くはなかったです(笑)自分もしっかりと働きました。主に二つの内容についてコーディングとレポート作成をしました。
一つ目が、二人の学生が出した結果の図式化です。テキストマイニングした結果の判定のためによく使われる概念としてAUCとROC曲線があります。興味がある人は下記のブログを参照してください。ざっくり言えば、どれくらい正確に推定できているかのバロメーターです。
上記の曲線を僕がコーディングすることになったのですが、理解が足りず苦労しました。もう片方のグループに情報系の学生がいたので、その学生が使ったコーディングを見よう見まねで何とか以下のようそれっぽい図を導出することができました。。。

もう一つがトピック分析(Topic Model)です。これはあるトピックごとにどのような単語が出ているのかを表すものです。トピック分析した結果は以下のようになりました。
Topic #0
▶ 剧情 好看 感觉 特效 第一部 英雄 场面 钢铁 绿巨人 奥创
Topic #1
▶ 电影 喜欢 睡着 失望 漫威 女巫 剧情 电影院 真的 一部
Topic #2
▶ 画面 剧情 故事 不错 动画 台词 真的 中国 音乐 尴尬
このように優秀なチームメイトのコードを参考にすることで、何とか自分のパートを完了させることができました。それでも提出締め切りの日にようやく結果が出揃うという中国人みたいなことをしてしまいました、、
というのみ、データが10万と膨大で一回一回の処理に途方もない時間がかかったからです、、
この課題は8時間強で終わりました。
なにはともあれ無事に終わってよかったです。
この授業を通して思ったのが、AIを活用すればより効率的にタスクを処理できるということです。実際に周りの学生もChatGPTを大いに活用していました。ChatGPTとPythonはかなり相性がいいように感じます。
自分も利用したかったのですが、OpenAIが中国にサービスを提供していないため、アカウントが作れませんでした。ですが、フィリピンに一か月滞在する機会があり、そこで現地のSimカードを買ったので、ようやくChatGPTのアカウントを作ることができました!!
なので、まずは下記Udemyの講座を受けて、ChapGPTの勉強をしていこうと思います。

ということで、今回の記事は以上となります。
長い記事ですが最後まで読んでいただきありがとうございます。
このマガジンでは引き続き、北京大学社会学修士の授業について執筆していきます。
もし気に入っていただけたならば、
スキとフォロー、マガジンの購読よろしくお願いします~
この記事が気に入ったらサポートをしてみませんか?