記事一覧




イラスト・デザイン忘備録
マンガ
【読み切りは32ページで描く】
読み切りのほどよいページ数は
だいたい26~32p(おおよそ100コマ)
このページ数なら雑誌にも載りやすい
(ページ数が多いと載せづらい)
そのうち4p(12~20コマ)ごとに場面転換が行われ
4p×8=32pとなることを以前解説し、
最初の4pに"情報"を入れたね
(次へ)
— とかげねこ@web漫画家 (@tokageneko_w)

stable Diffusion WebUI拡張機能 個人的セレクション
更新履歴
24/08/04
「Segment Anything V2」「PaintsUNDO」を追加
24/06/02
「sdweb-easy-prompt-selector」と「sdweb-easy-prompt-text-bigger」「PBRemTools」「Omost」「starline」「aesthetic-predictor-v2-5」を追加
コントロールネット(Control

画像生成AI忘備録 12月第一週
※11月の収集し忘れた情報も含みます。
新技術MagicAnimate
TikTokを運営するByteDanceが公開した、用意したモーション動画をコントロールネット「DancePose」で変換して一枚の写真から動かす技術です。
Animate Anyoneとはまた違う技術でもあります。
huggingface上では性能の高いGPUがなくても体験することができます。
抹茶もなかさんに

画像生成AI忘備録 11月号
stable Diffusion webUIの導入
NovelAI V3 初心者向け講座
ホットトピックAnimate Anyone
Animatediffなどと同じようにstableDiffusionを基盤に動画生成ができるものです。以前のものより一貫性が高く、一枚の絵から動かせるのが特徴です。まだ、デモやモデルの配布などは行われていませんが期待の持てる技術です。
抹茶もなかさんが

画像生成AI初心者教本 プロンプト辞典(服装編)
NovelAIではdanbooruタグと呼ばれる形式のキャプション学習を行っています。ですので、普通では使われない単語やローマ字読みの日本語のプロンプトが理解されたりします。
基本的な単語の組成 danbooruタグでは服装の前に接頭辞が追加されていることがあります。例えばfrilled hairband(フリル付きのヘアバンド)のように、frilled[接頭辞] + hairband(本体)

NovelAI V3 初心者教本・改
初めての方は初めまして、知っている方はこんにちは。かたらぎと申します。この度前作のNovelAI初心者教本を改定して公開することになりました。NovelAIの新UIやインペイント、コントールネットの一部などに対応した解説をしていきます。
↓前作
NovelAIに登録する まずは下記のURLにアクセスして下さい。
NovelAI公式サイト
このような画面が現れますので「ログイン」を押して
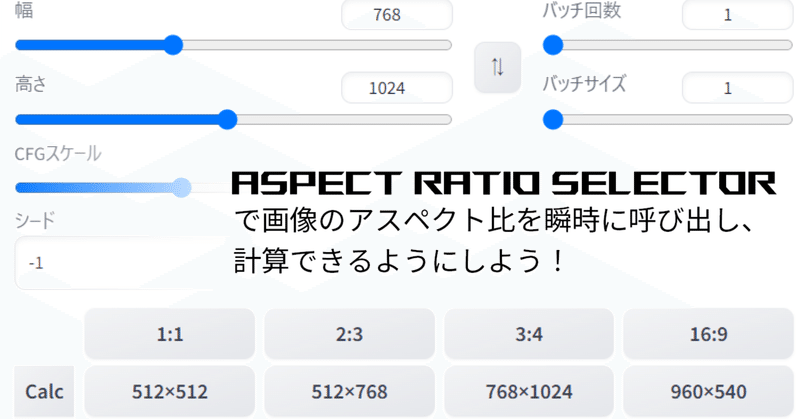
SDWebUIで画像のアスペクト比を瞬時に呼び出し、計算できるようにしよう!(Aspect Ratio selector)
stable Diffusion WebUIで画像生成をしていると「お気に入りの画像サイズをすぐに呼び出せるようにしたい」とか「画像の縦横比を計算するのが面倒くさい…」と思ったことはないですか?
この記事では「Aspect Ratio selector」を使って画像サイズを瞬時に呼び出したり計算したりする方法をご紹介します。
導入
まずは拡張機能の導入します。(わかる人は飛ばしてください

ControlNet初心者教本 改訂版
0:ControlNetとは
ControlNet(コントロールネット)とは画像などを下地にしてポーズや構図、画像の雰囲気を抽出し、画像の生成時に参照する仕組みです。この時利用する仕組みのことをプリプロセッサ(preprocessor)といいます。
下の画像は人間を棒人間のような線で抽出するopenposeの例です。このようにポーズをまねたりすることができます。
1:コントロールネットの

Stable Diffusion webUI忘備録 導入編
はじめに
初めましての方は初めまして、すでに知っている方はこんにちは、かたらぎと申します。私はStable Diffusionという画像生成AIのモデル開発をしています。
Stable Diffusionとは、文字列の意味を読み取りそれに沿った画像を生成する技術のことです。この記事ではそれを自分のPCで実行できる一つの方法であるWebUI(1111 AUTOMATIC)という方法を紹介します。

LoRA初心者教本・改 前編
ごあいさつ
初めましての方は初めまして。知っている方はこんにちは。かたらぎと申します。以前、記事にしたLoRAの初心者教本が非常に盛況だったため古くなった内容を改定して再発表することにしました。
前編ではLoRAを作る環境の構築と、簡単なおすすめ設定を紹介します。近日公開予定の後編では上級者を目指すための詳しい解説を行います。
LoRAとは
LoRAとはLow-Rank Adaptati

画像生成AIにおけるpythonとgitの導入
ここでは画像生成AIにおけるpythonとgitの導入方法を紹介します。
1:pythonをダウンロードする
上記のページにアクセスし、pythonのインストーラーをダウンロードしてください。Windowsの方は赤枠の中から選んでください。大抵の方は64bitで大丈夫です。
インストーラーを起動すると次の画面が出るので「Add python 3.10 to PATH」にチェックを入れて
SDwebUI環境再構築ガイド
SDwebUI環境を再構築する際のガイド。主に自分用。
各種ファイルの退避
・modelsフォルダ内のcheckpointとVAE、LoRA、LyCORIS
・output(画像の保存先)
・styles.csv(記録したプロンプト)
・ui-config.json(記録した設定、変更してないなら削除してもよい)
・controlnetのモデル(controlnetを使っている場合)
・embe

kohya版LoRA初心者教本 服を着せ替えできる高性能キャラLoRAをつくろう!
AI(Stable Diffusion WebUI)で画像生成をしていると意外と言うことを聞いてくれないということがよくありますよね。例えばキャラクターの髪や目や服の色がまちまちだったり、そもそもうまく出せなかったり……そんな悩みを解消するのが今日ご紹介するLoRAというわけです。
そもそもLoRAって何?
簡単に言えば素材となる画像を20~30枚程度用意し、AIに特徴を覚えさせることで人

Stable Diffusion WebUI 忘備録
自著 NovelAIの登録方法から各種設定の意味とプロンプトの書き方や画風までを網羅した解説書
SDwebUIなどで使える画像生成AIのモデルを画像と特徴、推奨設定などが一覧で見られるカタログ
総合資料画像生成AIの詳しい仕組みと歴史について詳しく書かれた資料
画像生成AIでよく使われる用語の解説
LoRA 簡単に言えば素材となる画像を20~30枚程度用意し、AIに特徴を覚えさせることで
- #note
- #AI
- #AIイラスト
- #StableDiffusion
- #aiart
- #廃墟
- #nijijourney
- #novelai
- #LoRa
- #StableDiffusionWebUI
- #Trinart
- #controlnet
- #AUTOMATIC1111
- #NovelAIDiffusion
- #AIArtworks
- #AI絵
- #HolaraAI
- #aiartcommunity
- #Extension
- #stableDifusion
- #AIイケメン部
- #Chilled_re_generic
- #rembg
- #AIファンタジー
- #DefmixV2
- #AI呪文情報共有
- #シンプルプロンプト選手権
- #NovelAIイケメン部
- #AIイラストどうでもいい豆知識では様々な情報が載せられています
- #AIイラストどうでもいい豆知識
- #TheBeastsofAI
- #ChilloutMix物語
- #Pixelization
- #7th_anime
- #DeDeDeArt
- #SE_V1_A
- #ネタ呪文紹介
- #しずくのアートメモリー